Documentação Técnica — Quarkus IRIS Monitor System
1. Objetivo e Escopo
Este módulo permite a integração entre aplicações Java baseadas em Quarkus e as capacidades nativas de monitoramento de performance do InterSystems IRIS.
Ele possibilita que o desenvolvedor anote métodos com @PerfmonReport, acionando automaticamente as rotinas ^PERFMON do IRIS durante a execução do método e gerando relatórios de performance sem intervenção manual.
2. Componentes do Sistema
2.1 Anotação: @PerfmonReport
- Definida como InterceptorBinding do CDI.
- Pode ser aplicada a métodos ou classes.
- Instrui o framework a envolver a execução do método com a lógica de monitoramento do IRIS.
2.2 Interceptor: PerfmonReportInterceptor
Intercepta chamadas a métodos anotados.
Fluxo de execução:
- Registrar evento de início (
LOG.infof("INIT: …")) - Chamar
monitorSystem.startPerfmon() - Prosseguir com
context.proceed() - No bloco
finally:- Chamar
monitorSystem.generateReportPerfmon(...) - Chamar
monitorSystem.stopPerfmon() - Registrar evento de fim com tempo de execução
- Chamar
- Registrar evento de início (
Garante que o monitoramento sempre será encerrado, mesmo se ocorrer uma exceção.
2.3 Bean DAO: MonitorSystem
Bean CDI anotado com
@ApplicationScoped.Mantém uma única instância de
IRISinicializada na inicialização.Configuração injetada via
@ConfigProperty(URL JDBC, usuário, senha).Utiliza
DriverManager.getConnection(...)para obter umaIRISConnectionnativa.Contém os métodos:
startPerfmon()generateReportPerfmon(String reportName)stopPerfmon()
Cada método chama as correspondentes rotinas ObjectScript em
iris.src.dc.AdapterPerfmonProcviairis.classMethodVoid(...).
2.4 Adapter ObjectScript: iris.src.dc.AdapterPerfmonProc
Define as rotinas que encapsulam a lógica do
^PERFMON:Class iris.src.dc.AdapterPerfmonProc Extends %RegisteredObject { ClassMethod start() As %Status { Set namespace = $NAMESPACE zn "%SYS" set status = $$Stop^PERFMON() set status = $$Start^PERFMON() zn namespace return status } ClassMethod generateReport(nameReport As %String = "report.txt") As %Status { Set namespace = $NAMESPACE zn "%SYS" Set tempDirectory = ##class(%SYS.System).TempDirectory() set status = $$Report^PERFMON("R","R","P", tempDirectory_"/"_nameReport) zn namespace return status } ClassMethod stop() As %Status { Set namespace = $NAMESPACE zn "%SYS" Set status = $$Stop^PERFMON() zn namespace return status } }Opera no namespace
%SYSpara acessar as rotinas^PERFMONe, em seguida, retorna para o namespace original.Opera no namespace
%SYSpara acessar as rotinas^PERFMON, retornando ao namespace original.
3. Fluxo de Execução
Uma requisição entra na aplicação Quarkus.
O interceptor CDI detecta a anotação
@PerfmonReporte intercepta a chamada do método.monitorSystem.startPerfmon()é invocado, acionando o monitoramento^PERFMONdo IRIS.O método de negócio é executado normalmente (acesso a dados, transformações, lógica, etc.).
Após o método retornar ou lançar uma exceção, o interceptor garante que:
monitorSystem.generateReportPerfmon(...)seja chamado para criar um relatório de performance.txt.monitorSystem.stopPerfmon()seja executado para encerrar a sessão de monitoramento.- O tempo total de execução do lado Java seja registrado usando
Logger.infof(...).
O arquivo de relatório gerado é armazenado no diretório temporário do IRIS, normalmente:
/usr/irissys/mgr/Temp/- O nome do arquivo segue o padrão:
<ClassName><MethodName><timestamp>.txt
- O nome do arquivo segue o padrão:
4. Desafios Técnicos e Soluções
| Desafio | Solução |
|---|---|
ClassCastException ao usar conexões JDBC pooladas | Use DriverManager.getConnection(...) para obter uma IRISConnection nativa, em vez do ConnectionWrapper poolado. |
| Sobrecarga por abrir conexões repetidamente | Mantenha uma única instância de IRIS dentro de um bean @ApplicationScoped, inicializada via @PostConstruct. |
Garantir que ^PERFMON seja sempre encerrado, mesmo em exceções | Use try-finally no interceptor para chamar stopPerfmon() e generateReportPerfmon(). |
| Portabilidade de configuração | Injete as configurações de conexão (jdbc.url, username, password) usando @ConfigProperty e application.properties. |
| Gerenciamento de sessões de monitoramento concorrentes | Evite anotar endpoints com alta concorrência. Versões futuras podem implementar isolamento por sessão. |
5. Casos de Uso e Benefícios
- Permite visibilidade em tempo real da atividade do IRIS a partir do código Java.
- Simplifica a análise de performance e otimização de consultas para desenvolvedores.
- Útil para benchmarking, profiling e testes de regressão do sistema.
- Pode servir como um registro leve de auditoria de performance para operações críticas.
6. Exemplo Prático de Uso
O código-fonte completo e o setup de deployment estão disponíveis em:
- Open Exchange: https://openexchange.intersystems.com/package/quarkus-iris-monitor-system
- Repositório GitHub: https://github.com/Davi-Massaru/quarkus-iris-monitor-system
6.1 Visão Geral
A aplicação roda um servidor Quarkus conectado a uma instância InterSystems IRIS configurada com o namespace FHIRSERVER.
A camada ORM é implementada usando Hibernate ORM com PanacheRepository, permitindo mapeamento direto entre entidades Java e classes do banco IRIS.
Quando a aplicação é iniciada (via docker-compose up), são iniciados:
- O container IRIS, hospedando o modelo de dados FHIR e rotinas ObjectScript (incluindo
AdapterPerfmonProc); - O container Quarkus, expondo endpoints REST e conectando-se ao IRIS via driver JDBC nativo.
6.2 Endpoint REST
Um recurso REST expõe um endpoint simples para recuperar informações de pacientes:
@Path("/patient")
public class PatientResource {
@Inject
PatientService patientService;
@GET
@Path("/info")
@Produces(MediaType.APPLICATION_JSON)
public PatientInfoDTO searchPatientInfo(@QueryParam("key") String key) {
return patientService.patientGetInfo(key);
}
}
Este endpoint aceita um parâmetro de consulta (key) que identifica o recurso do paciente dentro do repositório de dados FHIR.
6.3 Camada de Serviço com @PerfmonReport
A classe PatientService contém a lógica de negócio para recuperar e compor informações do paciente.
Ela é anotada com @PerfmonReport, o que significa que cada requisição para /patient/info aciona o monitoramento de performance do IRIS:
@ApplicationScoped
public class PatientService {
@Inject
PatientRepository patientRepository;
@PerfmonReport
public PatientInfoDTO patientGetInfo(String patientKey) {
Optional<Patient> patientOpt = patientRepository.find("key", patientKey).firstResultOptional();
Patient patient = patientOpt.orElseThrow(() -> new IllegalArgumentException("Patient not found"));
PatientInfoDTO dto = new PatientInfoDTO();
dto.setKey(patient.key);
dto.setName(patient.name);
dto.setAddress(patient.address);
dto.setBirthDate(patient.birthDate != null ? patient.birthDate.toString() : null);
dto.setGender(patient.gender);
dto.setMedications(patientRepository.findMedicationTextByPatient(patientKey));
dto.setConditions(patientRepository.findConditionsByPatient(patientKey));
dto.setAllergies(patientRepository.findAllergyByPatient(patientKey));
return dto;
}
}
6.4 Fluxo de Execução
Uma requisição é feita para: GET /patient/info?key=Patient/4
O Quarkus encaminha a requisição para PatientResource.searchPatientInfo().
O interceptor CDI detecta a anotação @PerfmonReport em PatientService.patientGetInfo().
Antes de executar a lógica de serviço:
O interceptor invoca
MonitorSystem.startPerfmon(), que chama a classe IRISiris.src.dc.AdapterPerfmonProc.start().O método executa a lógica de negócio, consultando dados do paciente usando os mapeamentos Hibernate
PanacheRepository.
Após a conclusão do método:
MonitorSystem.generateReportPerfmon()é chamado para criar o relatório de performance.MonitorSystem.stopPerfmon()interrompe o monitoramento de performance do IRIS.
Um relatório .txt é gerado em: usr/irissys/mgr/Temp/
Exemplo de nome de arquivo: PatientService_patientGetInfo_20251005_161906.txt
6.5 Resultado
O relatório gerado contém estatísticas detalhadas de execução do IRIS, por exemplo:
Routine Activity by Routine
Started: 10/11/2025 05:07:30PM Collected: 10/11/2025 05:07:31PM
Routine Name RtnLines % Lines RtnLoads RtnFetch Line/Load Directory
----------------------------------- --------- --------- --------- --------- --------- ---------
Other 0.0 0.0 0.0 0.0 0
PERFMON 44.0 0.0 0.0 0.0 0 /usr/irissys/mgr/
%occLibrary 3415047.0 34.1 48278.0 0.0 70.7 /usr/irissys/mgr/irislib/
iris.src.dc.AdapterPerfmonProc.1 7.0 0.0 2.0 0.0 3.5 /usr/irissys/mgr/FHIRSERVER/
%occName 5079994.0 50.7 0.0 0.0 0 /usr/irissys/mgr/irislib/
%apiDDL2 1078497.0 10.8 63358.0 0.0 17.0 /usr/irissys/mgr/irislib/
%SQL.FeatureGetter.1 446710.0 4.5 66939.0 0.0 6.7 /usr/irissys/mgr/irislib/
%SYS.WorkQueueMgr 365.0 0.0 1.0 0.0 365.0 /usr/irissys/mgr/
%CSP.Daemon.1 16.0 0.0 1.0 0.0 16.0 /usr/irissys/mgr/irislib/
%SYS.TokenAuth.1 14.0 0.0 5.0 0.0 2.8 /usr/irissys/mgr/
%Library.PosixTime.1 2.0 0.0 0.0 0.0 0 /usr/irissys/mgr/irislib/
%SYS.sqlcq.uEXTg3QR7a7I7Osf9e8Bz... 52.0 0.0 1.0 0.0 52.0 /usr/irissys/mgr/
%SYS.SQLSRV 16.0 0.0 0.0 0.0 0 /usr/irissys/mgr/
%apiOBJ 756.0 0.0 0.0 0.0 0 /usr/irissys/mgr/irislib/
FT.Collector.1 0.0 0.0 0.0 0.0 0 /usr/irissys/mgr/
SYS.Monitor.FeatureTrackerSensor.1 0.0 0.0 0.0 0.0 0 /usr/irissys/mgr/
%SYS.Monitor.Control.1 0.0 0.0 0.0 0.0 0 /usr/irissys/mgr/
%SYS.DBSRV.1 252.0 0.0 4.0 0.0 63.0 /usr/irissys/mgr/
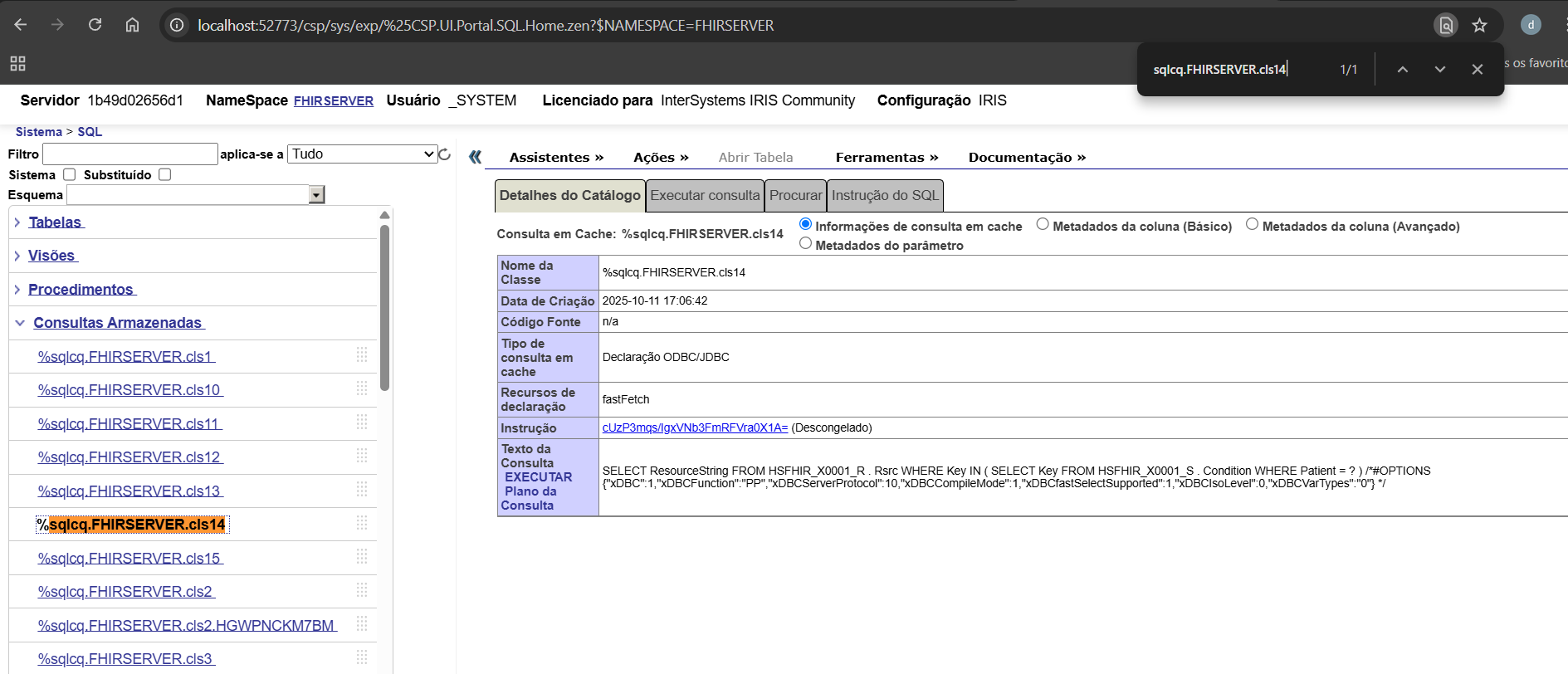
%sqlcq.FHIRSERVER.cls12.1 19.0 0.0 0.0 0.0 0 /usr/irissys/mgr/irislocaldata/
%sqlcq.FHIRSERVER.cls13.1 74.0 0.0 0.0 0.0 0 /usr/irissys/mgr/irislocaldata/
%sqlcq.FHIRSERVER.cls14.1 74.0 0.0 0.0 0.0 0 /usr/irissys/mgr/irislocaldata/
%sqlcq.FHIRSERVER.cls15.1 52.0 0.0 0.0 0.0 0 /usr/irissys/mgr/irislocaldata/
%SYS.System.1 1.0 0.0 0.0 0.0 0 /usr/irissys/mgr/
Esses dados fornecem uma visão precisa sobre quais rotinas foram executadas internamente pelo IRIS durante aquela chamada REST — incluindo compilação de SQL, execução e acesso a dados FHIR.
Observação: As rotinas
%sqlcq.FHIRSERVER.*registram todas as consultas SQL cache executadas pelo Quarkus dentro do método. Monitorar essas rotinas permite aos desenvolvedores analisar a execução das queries, compreender o comportamento do código e identificar possíveis gargalos de performance. Isso as torna uma ferramenta poderosa para desenvolvimento e depuração de operações relacionadas ao FHIR.
6.6 Resumo
Este exemplo demonstra como um serviço padrão Quarkus pode utilizar de forma transparente as ferramentas nativas de monitoramento do IRIS usando a anotação @PerfmonReport.
Ele combina:
- Interceptadores CDI (Quarkus)
- Hibernate PanacheRepositories (ORM)
- Rotinas ObjectScript nativas do IRIS (^PERFMON)
O resultado é um mecanismo de profiling de performance totalmente automatizado e reproduzível, que pode ser aplicado a qualquer método de serviço na aplicação.



 Olá!
Olá!.jpg)










.png)






























.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)



 Aplicativo usado na demonstração:
Aplicativo usado na demonstração: