Plataformas de Dados e Desempenho da InterSystems - Parte 5: Monitoramento com SNMP
Em posts anteriores, mostrei como é possível coletar métricas de desempenho histórico usando pButtons. Recorro ao pButtons primeiro porque sei que ele é instalado com todas as instâncias de Plataformas de Dados (Ensemble, Caché, ...). No entanto, existem outras maneiras de coletar, processar e exibir métricas de desempenho do Caché em tempo real, seja para monitoramento simples ou, ainda, para análises operacionais e planejamento de capacidade muito mais sofisticados. Um dos métodos mais comuns de coleta de dados é usar o SNMP (Simple Network Management Protocol).
SNMP é uma maneira padrão para o Caché fornecer informações de gerenciamento e monitoramento para uma ampla variedade de ferramentas de gerenciamento. A documentação online do Caché inclui detalhes da interface entre o Caché e o SNMP. Embora o SNMP deva 'simplesmente funcionar' com o Caché, existem alguns truques e armadilhas de configuração. Levei alguns começos falsos e ajuda de outras pessoas aqui na InterSystems para fazer o Caché se comunicar com o agente mestre SNMP do Sistema Operacional, então escrevi este post para que você possa evitar a mesma dor.
Neste post, vou detalhar a configuração do SNMP para Caché no Red Hat Linux, e você deve ser capaz de usar os mesmos passos para outras distribuições *nix. Estou escrevendo o post usando o Red Hat porque o Linux pode ser um pouco mais complicado de configurar - no Windows, o Caché instala automaticamente uma DLL para se conectar com o serviço SNMP padrão do Windows, então deve ser mais fácil de configurar.
Uma vez que o SNMP esteja configurado no lado do servidor, você pode começar a monitorar usando várias ferramentas. Vou mostrar o monitoramento usando a popular ferramenta PRTG, mas existem muitas outras - Aqui está uma lista parcial.
Observe que os arquivos MIB do Caché e Ensemble estão incluídos na pasta Caché_installation_directory/SNMP. Os arquivos são: ISC-CACHE.mib e ISC-ENSEMBLE.mib.
Posts anteriores desta série:
Comece aqui...
Comece revisando "Monitorando o Caché Usando SNMP" na documentação online do Caché..
1. Configuração do Caché
Siga os passos na seção Gerenciando SNMP no Caché na documentação online do Caché para habilitar o serviço de monitoramento do Caché e configurar o subagente SNMP do Caché para iniciar automaticamente na inicialização do Caché.
Verifique se o processo do Caché está em execução, por exemplo, olhando na lista de processos ou no sistema operacional:
ps -ef | grep SNMP
root 1171 1097 0 02:26 pts/1 00:00:00 grep SNMP
root 27833 1 0 00:34 pts/0 00:00:05 cache -s/db/trak/hs2015/mgr -cj -p33 JOB^SNMP
É só isso, a configuração do Caché está completa!
2. Configuração do sistema operacional
Há um pouco mais a fazer aqui. Primeiro, verifique se o daemon snmpd está instalado e em execução. Se não estiver, instale e inicie o snmpd.
Verifique o status do snmpd com:
service snmpd status
Inicie ou pare o snmpd com:
service snmpd start|stop
Se o SNMP não estiver instalado, você terá que instalá-lo de acordo com as instruções do sistema operacional, por exemplo:
yum -y install net-snmp net-snmp-utils
3. Configure o snmpd
Conforme detalhado na documentação do Caché, em sistemas Linux, a tarefa mais importante é verificar se o agente mestre SNMP no sistema é compatível com o protocolo Agent Extensibility (AgentX) (o Caché é executado como um subagente) e se o mestre está ativo e escutando conexões na porta TCP padrão do AgentX, 705.
Foi aqui que encontrei problemas. Cometi alguns erros básicos no arquivo snmp.conf que impediram o subagente SNMP do Caché de se comunicar com o agente mestre do sistema operacional. O seguinte arquivo de exemplo /etc/snmp/snmp.conf foi configurado para iniciar o AgentX e fornecer acesso aos MIBs SNMP do Caché e do Ensemble.
Observe que você terá que confirmar se a seguinte configuração está em conformidade com as políticas de segurança da sua organização.
No mínimo, as seguintes linhas devem ser editadas para refletir a configuração do seu sistema.
Por exemplo, altere:
syslocation "System_Location"
para
syslocation "Primary Server Room"
Edite também pelo menos as seguintes duas linhas:
syscontact "Your Name"
trapsink Caché_database_server_name_or_ip_address public
Edite ou substitua o arquivo /etc/snmp/snmp.conf existente para corresponder ao seguinte::
###############################################################################
#
# snmpd.conf:
# Um arquivo de configuração de exemplo para configurar o agente NET-SNMP com o
# Caché.
#
# Isto foi usado com sucesso no Red Hat Enterprise Linux e executando
# o daemon snmpd em primeiro plano com o seguinte comando:
#
# /usr/sbin/snmpd -f -L -x TCP:localhost:705 -c./snmpd.conf
#
# Você pode querer/precisar alterar algumas das informações, especialmente o
# endereço IP do receptor de traps se você espera receber traps. Eu também vi
# um caso (no AIX) onde tivemos que usar a opção "-C" na linha de comando snmpd,
# para garantir que estávamos obtendo o arquivo snmpd.conf correto.
#
###############################################################################
###########################################################################
# SEÇÃO: Configuração de Informações do Sistema
#
# Esta seção define algumas das informações relatadas no
# grupo mib "system" na árvore mibII.
# syslocation: A localização [tipicamente física] do sistema.
# Observe que definir este valor aqui significa que ao tentar
# executar uma operação snmp SET na variável sysLocation.0, o agente
# etornará o código de erro "notWritable". Ou seja, incluir
# este token no arquivo snmpd.conf desativará o acesso de gravação à
# variável.
# argumentos: string_de_localização
syslocation "Localização do Sistema"
# syscontact: As informações de contato do administrador
# Observe que definir este valor aqui significa que ao tentar
# executar uma operação snmp SET na variável sysContact.0, o agente
# retornará o código de erro "notWritable". Ou seja, incluir
# este token no arquivo snmpd.conf desativará o acesso de gravação à
# variável.
# argumentos: string_de_contato
syscontact "Seu Nome"
# sysservices: O valor adequado para o objeto sysServices.
# argumentos: número_sysservices
sysservices 76
###########################################################################
# SEÇÃO: Modo de Operação do Agente
#
# Esta seção define como o agente operará quando estiver em execução.
#
# master: O agente deve operar como um agente mestre ou não.
# Atualmente, o único tipo de agente mestre suportado para este token
# é "agentx".
#
# argumentos: (on|yes|agentx|all|off|no)
master agentx
agentXSocket tcp:localhost:705
###########################################################################
# SEÇÃO: Destinos de Trap
#
# Aqui definimos para quem o agente enviará traps.
# trapsink: Um receptor de traps SNMPv1
# argumentos: host [community] [portnum]
trapsink Caché_database_server_name_or_ip_address public
###############################################################################
# Controle de Acesso
###############################################################################
# Como fornecido, o daemon snmpd responderá apenas a consultas no
# grupo mib do sistema até que este arquivo seja substituído ou modificado
# para fins de segurança. Exemplos de como aumentar o nível de acesso
# são mostrados abaixo.
#
# De longe, a pergunta mais comum que recebo sobre o agente é "por que ele
# não funciona?", quando na verdade deveria ser "como configuro o agente
# para me permitir acessá-lo?"
#
# Por padrão, o agente responde à comunidade "public" para acesso somente
# leitura, se executado diretamente, sem nenhum arquivo de configuração
# no lugar. Os exemplos a seguir mostram outras maneiras de configurar
# o agente para que você possa alterar os nomes da comunidade e conceder
# a si mesmo acesso de gravação à árvore mib também.
#
# Para mais informações, leia o FAQ, bem como a página de manual
# snmpd.conf(5).
#
####
# Primeiro, mapeie o nome da comunidade "public" para um "nome de segurança"
# sec.name source community
com2sec notConfigUser default public
####
# Segundo, mapeie o nome de segurança para um nome de grupo:
# groupName securityModel securityName
group notConfigGroup v1 notConfigUser
group notConfigGroup v2c notConfigUser
####
# Terceiro, crie uma visualização para que o grupo tenha direitos de acesso:
# Faça com que pelo menos o snmpwalk -v 1 localhost -c public system volte a ser rápido.
# name incl/excl subtree mask(optional)
# acesso ao subconjunto 'internet'
view systemview included .1.3.6.1
# Acesso aos MIBs do Cache Caché e Ensemble
view systemview included .1.3.6.1.4.1.16563.1
view systemview included .1.3.6.1.4.1.16563.2
####
# Finalmente, conceda ao grupo acesso somente leitura à visualização systemview.
# group context sec.model sec.level prefix read write notif
access notConfigGroup "" any noauth exact systemview none none
Após editar o arquivo /etc/snmp/snmp.conf, reinicie o daemon snmpd.
service snmpd restart
Verifique o status do snmpd, observe que o AgentX foi iniciado, veja a linha de status: Ativando o suporte mestre AgentX.
h-4.2# service snmpd restart
Redirecting to /bin/systemctl restart snmpd.service
sh-4.2# service snmpd status
Redirecting to /bin/systemctl status snmpd.service
● snmpd.service - Simple Network Management Protocol (SNMP) Daemon.
Loaded: loaded (/usr/lib/systemd/system/snmpd.service; disabled; vendor preset: disabled)
Active: active (running) since Wed 2016-04-27 00:31:36 EDT; 7s ago
Main PID: 27820 (snmpd)
CGroup: /system.slice/snmpd.service
└─27820 /usr/sbin/snmpd -LS0-6d -f
Apr 27 00:31:36 vsan-tc-db2.iscinternal.com systemd[1]: Starting Simple Network Management Protocol (SNMP) Daemon....
Apr 27 00:31:36 vsan-tc-db2.iscinternal.com snmpd[27820]: Turning on AgentX master support.
Apr 27 00:31:36 vsan-tc-db2.iscinternal.com snmpd[27820]: NET-SNMP version 5.7.2
Apr 27 00:31:36 vsan-tc-db2.iscinternal.com systemd[1]: Started Simple Network Management Protocol (SNMP) Daemon..
sh-4.2#
Após reiniciar o snmpd, você deve reiniciar o subagente SNMP do Caché usando a rotina ^SNMP:
%SYS>do stop^SNMP()
%SYS>do start^SNMP(705,20)
O daemon snmpd do sistema operacional e o subagente Caché agora devem estar em execução e acessíveis.
4. Testando o acesso MIB
O acesso MIB pode ser verificado a partir da linha de comando com os seguintes comandos. snmpget retorna um único valor:
snmpget -mAll -v 2c -c public vsan-tc-db2 .1.3.6.1.4.1.16563.1.1.1.1.5.5.72.50.48.49.53
SNMPv2-SMI::enterprises.16563.1.1.1.1.5.5.72.50.48.49.53 = STRING: "Cache for UNIX (Red Hat Enterprise Linux for x86-64) 2015.2.1 (Build 705U) Mon Aug 31 2015 16:53:38 EDT"
E snmpwalk irá 'percorrer' a árvore ou ramo MIB::
snmpwalk -m ALL -v 2c -c public vsan-tc-db2 .1.3.6.1.4.1.16563.1.1.1.1
SNMPv2-SMI::enterprises.16563.1.1.1.1.2.5.72.50.48.49.53 = STRING: "H2015"
SNMPv2-SMI::enterprises.16563.1.1.1.1.3.5.72.50.48.49.53 = STRING: "/db/trak/hs2015/cache.cpf"
SNMPv2-SMI::enterprises.16563.1.1.1.1.4.5.72.50.48.49.53 = STRING: "/db/trak/hs2015/mgr/"
etc
etc
Existem também vários clientes Windows e *nix disponíveis para visualizar dados do sistema. Eu uso o iReasoning MIB Browser gratuito. Você precisará carregar o arquivo ISC-CACHE.MIB no cliente para que ele reconheça a estrutura do MIB.
A imagem a seguir mostra o iReasoning MIB Browser no OSX.
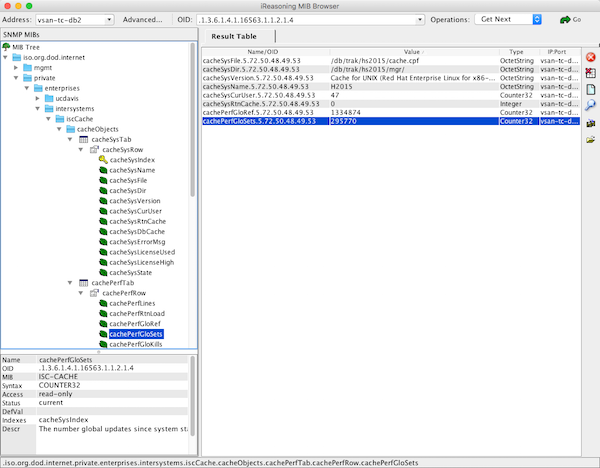
Incluindo em Ferramentas de Monitoramento
É aqui que podem haver grandes diferenças na implementação. A escolha da ferramenta de monitoramento ou análise fica a seu critério.
Por favor, deixe comentários na postagem detalhando as ferramentas e o valor que você obtém delas para monitorar e gerenciar seus sistemas. Isso será de grande ajuda para outros membros da comunidade.
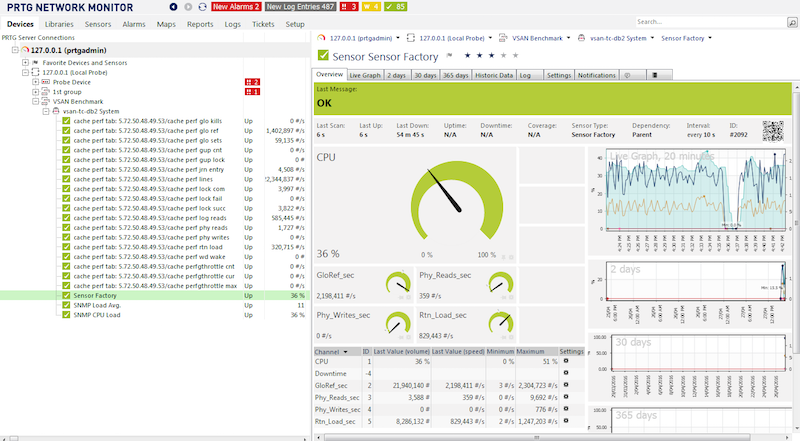
Abaixo está uma captura de tela do popular PRTG Network Monitor mostrando métricas do Caché. Os passos para incluir métricas do Caché no PRTG são semelhantes aos de outras ferramentas.
Fluxo de trabalho de exemplo - adicionando o MIB do Caché à ferramenta de monitoramento.
Passo 1.
Certifique-se de que você pode se conectar aos MIBs do sistema operacional. Uma dica é solucionar problemas com o sistema operacional, não com o Caché. É muito provável que as ferramentas de monitoramento já conheçam e estejam pré-configuradas para MIBs comuns de sistemas operacionais, então a ajuda de fornecedores ou outros usuários pode ser mais fácil.
Dependendo da ferramenta de monitoramento que você escolher, pode ser necessário adicionar um 'módulo' ou 'aplicativo' SNMP, que geralmente são gratuitos ou de código aberto. Achei as instruções do fornecedor bastante diretas para esta etapa.
Uma vez que você esteja monitorando as métricas do sistema operacional, é hora de adicionar o Caché.
Passo 2.
Importe os arquivos ISC-CACHE.mib eISC-ENSEMBLE.mibpara a ferramenta para que ela reconheça a estrutura do MIB.
Os passos aqui irão variar; por exemplo, o PRTG possui um utilitário 'Importador de MIB'. Os passos básicos são abrir o arquivo de texto ISC-CACHE.mib na ferramenta e importá-lo para o formato interno da ferramenta. Por exemplo, o Splunk usa um formato Python, etc.
Nota:_ Descobri que a ferramenta PRTG expirava o tempo limite se eu tentasse adicionar um sensor com todos os ramos do MIB do Caché. Presumo que ele estava percorrendo toda a árvore e expirou o tempo limite para algumas métricas como listas de processos. Não gastei tempo solucionando esse problema, em vez disso, contornei o problema importando apenas o ramo de desempenho (cachePerfTab) do ISC-CACHE.mib.
Uma vez importado/convertido, o MIB pode ser reutilizado para coletar dados de outros servidores em sua rede. O gráfico acima mostra o PRTG usando o sensor Sensor Factory para combinar vários sensores em um único gráfico.
Resumo
Existem muitas ferramentas de monitoramento, alerta e algumas ferramentas de análise muito inteligentes disponíveis, algumas gratuitas, outras com licenças para suporte e muitas funcionalidades variadas.
Você deve monitorar seu sistema e entender qual atividade é normal e qual atividade foge do normal e deve ser investigada. SNMP é uma maneira simples de expor métricas do Caché e do Ensemble.


.png)
.png)
.png)
.png)
.png)














 ficamos surpresos ao ver como nossas instâncias de plataforma de dados estão de fato se saindo quando comparamos a ter apenas as métricas EC2-OS padrão para fazer este tipo de monitoramento. Lembre-se de que o SAM oferece atualmente mais de 100 métricas de kernel do InterSystems IRIS e as combinam com os alertas do InterSystems IRIS. A fusão dos dois deve ser o começo... não de uma história de amor, mas de uma leitura mais precisa de seus sistemas.
ficamos surpresos ao ver como nossas instâncias de plataforma de dados estão de fato se saindo quando comparamos a ter apenas as métricas EC2-OS padrão para fazer este tipo de monitoramento. Lembre-se de que o SAM oferece atualmente mais de 100 métricas de kernel do InterSystems IRIS e as combinam com os alertas do InterSystems IRIS. A fusão dos dois deve ser o começo... não de uma história de amor, mas de uma leitura mais precisa de seus sistemas. 