Olá, esta postagem foi escrita inicialmente para Caché. Em junho de 2023, finalmente a atualizei para IRIS. Se você está revisitando a postagem agora, a única mudança real foi a substituição do Caché pelo IRIS! Também atualizei os links para a documentação do IRIS e corrigi alguns erros de digitação e gramaticais. Aproveite :)
Nesta postagem, mostro estratégias para fazer backup do InterSystems IRIS usando o Backup Externo, incluindo exemplos da integração com soluções baseadas em cópias instantâneas. A maioria das soluções que vejo hoje são implantadas no Linux no VMware. Portanto, grande parte da postagem mostra as formas como as soluções integram a tecnologia de cópia instantânea VMware como exemplos.
Backup do IRIS - acompanha pilhas?
O backup online do IRIS está incluído na instalação do IRIS para backup contínuo dos bancos de dados do IRIS. Porém, há soluções de backup mais eficientes que você deve considerar ao ampliar os sistemas. O Backup Externo integrado com tecnologias de cópia instantânea é a solução recomendada para backup de sistemas, incluindo bancos de dados do IRIS.
Há alguma consideração especial para backup externo?
A documentação online do Backup Externo tem todos os detalhes. Uma consideração importante é:
"Para garantir a integridade cópia instantânea, o IRIS oferece métodos para congelar gravações em bancos de dados enquanto a cópia é criada. Somente as gravações físicas nos arquivos dos bancos de dados são congeladas durante a criação da cópia instantânea, permitindo que os processos do usuário continuem realizando atualizações na memória sem interrupções."
Também é importante observar que parte do processo de cópia em sistemas virtualizados causa uma pequena pausa no backup de uma VM, geralmente chamada de "tempo de stun". Ela costuma durar menos de um segundo, então não é percebida pelos usuários nem afeta a operação do sistema. Porém, em algumas circunstâncias, o stun pode durar mais tempo. Se o stun durar mais que o tempo limite de qualidade de serviço (QoS) para o espelhamento do banco de dados do IRIS, o nó de backup pensará que houve uma falha no primário e fará a tolerância a falhas. Mais adiante nesta postagem, explico como você pode revisar os tempos de stun caso precise alterar o tempo limite de QoS do espelhamento.
[Veja aqui uma lista de outras Plataformas de Dados da InterSystems e postagens da série de desempenho.](https://community.intersystems.com/post/capacity-planning-and-performance-series-index)
Leia também a Guia de Backup e Restauração da documentação online do IRIS para esta postagem.
Opções de backup
Solução de backup mínima - Backup Online do IRIS
Se você não tiver mais nada, ela vem incluída na plataforma de dados da InterSystems para backups de tempo de inatividade zero. Lembre-se: o backup online do IRIS só faz backup de arquivos dos bancos de dados do IRIS, capturando todos os blocos nos bancos de dados alocados para dados com a saída gravada em um arquivo sequencial. O Backup Online do IRIS é compatível com backups cumulativos e incrementais.
No contexto do VMware, o Backup Online do IRIS é uma solução de backup a nível de convidado. Como outras soluções de convidado, as operações do Backup Online do IRIS são praticamente as mesmas, quer o aplicativo seja virtualizado ou executado diretamente em um host. O Backup Online do IRIS precisa ser coordenado com um backup do sistema para copiar o arquivo de saída do backup online do IRIS para a mídia de backup e todos os outros sistemas de arquivos usados pelo seu aplicativo. No mínimo, o backup do sistema precisa incluir o diretório de instalação, o diário e os diretórios alternativos do diário, os arquivos do aplicativo e qualquer diretório com os arquivos externos usados pelo aplicativo.
O Backup Online do IRIS deve ser considerado como uma abordagem inicial para sites menores que querem implementar uma solução de baixo custo para fazer backup apenas de bancos de dados do IRIS ou backups ad hoc. Por exemplo, é útil na configuração do espelhamento. No entanto, como os bancos de dados crescem e o IRIS só costuma ser uma parte do cenário de dados do cliente, é uma prática recomendada combinar os Backups Externos com a tecnologia de cópia instantânea e utilitários de terceiros, o que possui vantagens como inclusão do backup de arquivos que não são dos bancos de dados, restaurações mais rápidas, visão de dados de toda a empresa e melhores ferramentas de gestão e catálogo.
Solução de backup recomendada - Backup Externo
Usando o VMware como exemplo, a virtualização no VMware adiciona funcionalidades e opções para proteger VMs inteiras. Depois de virtualizar uma solução, você encapsulará efetivamente seu sistema — incluindo o sistema operacional, o aplicativo e os dados —, tudo dentro de arquivos .vmdk (e alguns outros). Quando necessários, esses arquivos podem ser simples de gerenciar e usados para recuperar um sistema inteiro, o que difere muita da mesma situação em um sistema físico, onde você precisa recuperar e configurar os componentes separadamente – sistema operacional, drivers, aplicativos de terceiros, banco de dados, arquivos de bancos de dados etc.
# Cópia instantanea da VMware
A vSphere Data Protection (VDP) do VMware e outras soluções de backup de terceiros para o backup da VM, como Veeam ou Commvault, usam a funcionalidade de cópias instantâneas das máquinas virtuais do VMware para criar backups. Segue uma explicação de nível superior das cópias instantâneas do VMware. Veja a documentação do VMware para mais detalhes.
É importante lembrar que as cópias instantâneas são aplicados à VM inteira, e o sistema operacional e qualquer aplicativo ou mecanismo de banco de dados não sabem que a cópia está acontecendo. Além disso, lembre-se:
Sozinhas, as cópias instantâneas da VMware não são backups!
As cópias instantâneas permitem que o software de backup faça backups, mas eles não são backups por si sós.
O VDP e as soluções de backup de terceiros usam o processo de cópia do VMware em conjunto com o aplicativo de backup para gerenciar a criação e, mais importantemente, a exclusão da cópia instantânea. Em um nível superior, o processo e a sequência de eventos para um backup externo usando cópias instantâneas do VMware são os seguintes:
- O software de backup de terceiros solicita que o host ESXi acione uma cópia instantânea do VMware.
- Os arquivos .vmdk de uma VM são colocados em um estado somente leitura, e um arquivo delta .vmdk filho é criado para cada um dos arquivos .vmdk da VM.
- A cópia na gravação é usada com todas as mudanças na VM gravadas nos arquivos delta. Quaisquer leituras são primeiro do arquivo delta.
- O software de backup gerencia a cópia dos arquivos .vmdk pai somente leitura para o destino do backup.
- Quando o backup é concluído, é feito o commit da cópia (os discos da VM retomam as gravações e atualizam os blocos nos arquivos delta gravados no pai).
- A cópia instantânea do VMware é excluído agora.
As soluções de backup também usam outros recursos, como Changed Block Tracking (CBT), permitindo backups incrementais ou cumulativos para velocidade e eficiência (especialmente importante para a economia de espaço), e geralmente adicionam outras funções importantes, como deduplicação e compactação de dados, agendamento, montagem de VMs com endereços IP alterados para verificações de integridade etc., restaurações completas no nível da VM e do arquivo e gestão de catálogo.
As cópias instantâneas da VMware que não forem gerenciados adequadamente ou forem deixados em execução por um longo período podem usar armazenamento excessivo (quanto mais dados forem alterados, mais os arquivos delta continuarão a crescer) e deixar as VMs mais lentas.
Considere com cuidado antes de executar uma cópia instantânea manual em uma instância de produção. Por que você está fazendo isso? O que acontecerá se você reverter para quando a cópia instantânea foi criada? O que acontecerá com todas as transações do aplicativo entre a criação e a reversão?
Não tem problema se o seu software de backup criar e excluir uma cópia instantânea. A cópia instantânea deve existir apenas por um breve período. Uma parte fundamental da sua estratégia de backup será escolher um momento de baixo uso do sistema para minimizar qualquer impacto adicional nos usuários e no desempenho.
Considerações do banco de dados do IRIS para cópias instantâneas
Antes de obter a cópia instantânea, é preciso colocar o banco de dados no modo desativado. Assim, é realizado o commit de todas as gravações pendentes e o banco de dados fica em um estado consistente. O IRIS oferece métodos e uma API para fazer o commit e congelar (interromper) gravações no banco de dados por um breve período enquanto a cópia instantânea é criada. Assim, somente as gravações físicas nos arquivos do banco de dados são congeladas durante a criação da cópia instantânea, permitindo que os processos do usuário continuem realizando atualizações na memória sem interrupções. Depois que a cópia instantânea é acionada, as gravações no banco de dados são descongeladas e o backup continua copiando os dados para a mídia de backup. O tempo entre o congelamento e o descongelamento deve ser rápido (alguns segundos).
Além de pausar as gravações, o congelamento do IRIS também processa a troca de arquivos de diário e a gravação de um marcador de backup no diário. O arquivo de diário continua a ser gravado normalmente enquanto as gravações no banco de dados físico estão congeladas. Se o sistema falhar enquanto as gravações no banco de dados físico estiverem congeladas, os dados serão recuperados do diário normalmente durante a inicialização.
O diagrama a seguir mostra as etapas de congelamento e descongelamento com cópias instantâneas da VMware para criar um backup com uma imagem de banco de dados consistente.
Linha do tempo da cópia instantânea da VMware + congelamento/descongelamento do IRIS (não escalar)
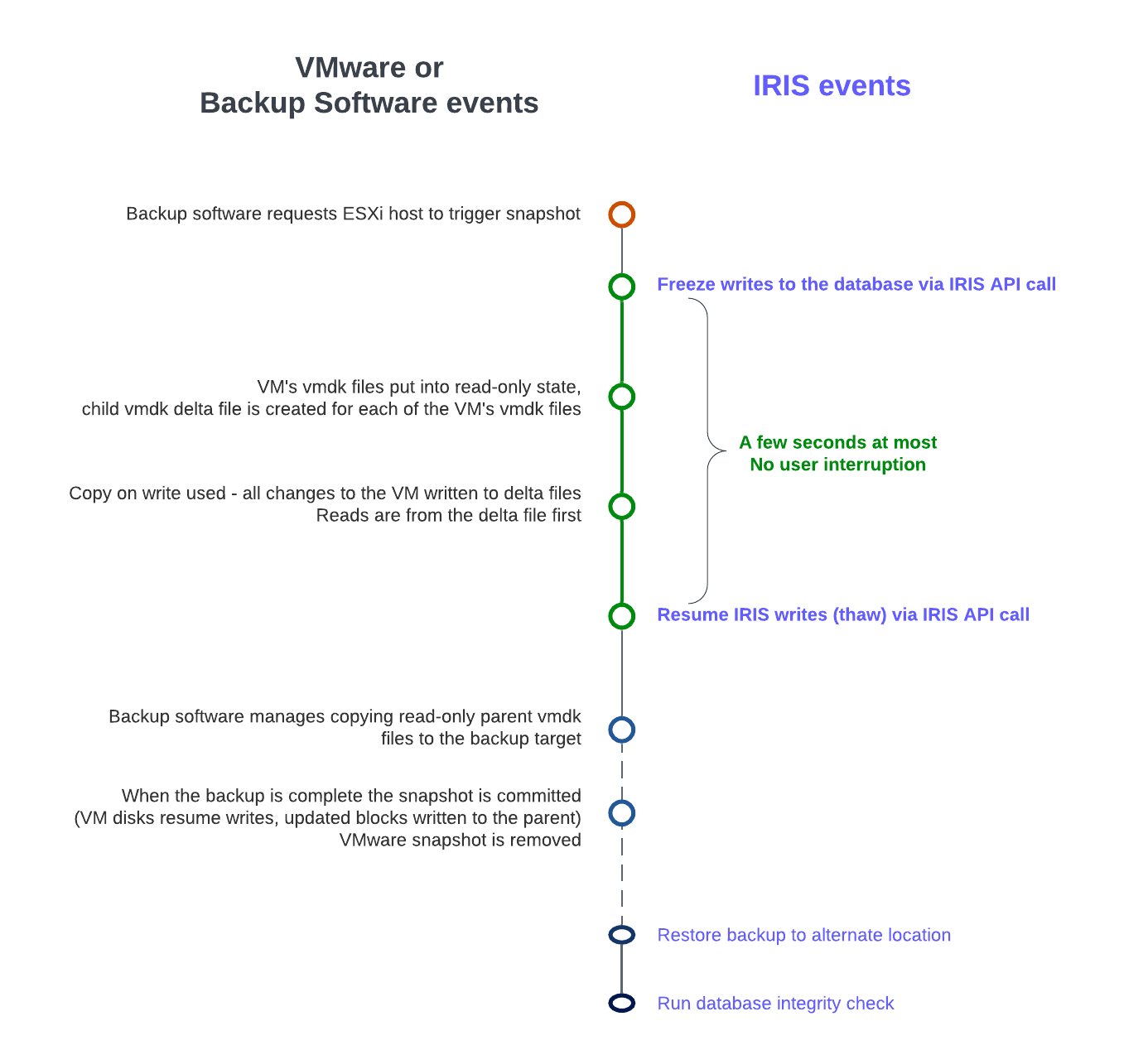
Observe o breve período entre o congelamento e o descongelamento: apenas o suficiente para criar a cópia instantânea, e não copiar o pai somente leitura para o destino do backup.
Resumo - Por que preciso congelar e descongelar o banco de dados do IRIS quando o VMware está criando uma cópia instantânea?
O processo de congelar e descongelar o banco de dados é fundamental para garantir a consistência e integridade dos dados. Isso ocorre porque:
Consistência dos dados: o IRIS pode escrever diários ou o WIJ ou fazer gravações aleatórias no banco de dados a qualquer momento. Uma cópia instantânea captura o estado da VM em um momento específico. Se o banco de dados estiver sendo ativamente gravado durante a cópia instantânea, isso poderá causar uma cópia com dados parciais ou inconsistentes. Congelar o banco de dados garante que todas as transações sejam concluídas e nenhuma transação nova seja iniciada durante a cópia, levando a um estado de disco consistente.
Desativação do sistema de arquivos: A tecnologia de cópia instantânea da VMware pode desativar o sistema de arquivos para garantir a consistência dele. No entanto, isso não abrange a consistência no nível do aplicativo ou do banco de dados. O congelamento do banco de dados garante que ele esteja em um estado consistente no nível do aplicativo, complementando o quiesce do VMware.
Redução do tempo de recuperação: a restauração de cópia instantânea obtida sem congelar o banco de dados pode exigir etapas adicionais, como o reparo do banco de dados ou verificações de consistência, o que pode aumentar significativamente o tempo de recuperação. O congelamento e descongelamento garantem que o banco de dados possa ser usado imediatamente após a restauração, diminuindo o tempo de inatividade.
Integração do congelamento e descongelamento do IRIS
O vSphere permite que um script seja chamado automaticamente em ambos os lados da criação da cópia instantânea. É quando são chamados o congelamento e descongelamento do IRIS. Observação: para essa funcionalidade funcionar corretamente, o host ESXi solicita que o sistema operacional convidado desative os discos pelas Ferramentas do VMware.
As ferramentas do VMware precisam ser instaladas no sistema operacional convidado.
Os scripts precisam obedecer regras rígidas de nome e localização. As permissões de arquivo também precisam ser definidas. Para o VMware no Linux, os nomes dos scripts são:
# /usr/sbin/pre-freeze-script
# /usr/sbin/post-thaw-script
Confira abaixo exemplos de scripts de congelamento e descongelamento que nossa equipe usa com o backup do Veeam para instâncias internas de laboratório de testes, mas eles também devem funcionar com outras soluções. Esses exemplos foram testados e usados no vSphere 6 e Red Hat 7.
Embora esses scripts possam ser usados como exemplos e ilustrem o método, você precisa validá-los para seus ambientes!
Exemplo de script pré-congelamento:
#!/bin/sh
#
# Script called by VMWare immediately prior to snapshot for backup.
# Tested on Red Hat 7.2
#
LOGDIR=/var/log
SNAPLOG=$LOGDIR/snapshot.log
echo >> $SNAPLOG
echo "`date`: Pre freeze script started" >> $SNAPLOG
exit_code=0
# Only for running instances
for INST in `iris qall 2>/dev/null | tail -n +3 | grep '^up' | cut -c5- | awk '{print $1}'`; do
echo "`date`: Attempting to freeze $INST" >> $SNAPLOG
# Detailed instances specific log
LOGFILE=$LOGDIR/$INST-pre_post.log
# Freeze
irissession $INST -U '%SYS' "##Class(Backup.General).ExternalFreeze(\"$LOGFILE\",,,,,,1800)" >> $SNAPLOG $
status=$?
case $status in
5) echo "`date`: $INST IS FROZEN" >> $SNAPLOG
;;
3) echo "`date`: $INST FREEZE FAILED" >> $SNAPLOG
logger -p user.err "freeze of $INST failed"
exit_code=1
;;
*) echo "`date`: ERROR: Unknown status code: $status" >> $SNAPLOG
logger -p user.err "ERROR when freezing $INST"
exit_code=1
;;
esac
echo "`date`: Completed freeze of $INST" >> $SNAPLOG
done
echo "`date`: Pre freeze script finished" >> $SNAPLOG
exit $exit_code
Exemplo de script de descongelamento:
#!/bin/sh
#
# Script called by VMWare immediately after backup snapshot has been created
# Tested on Red Hat 7.2
#
LOGDIR=/var/log
SNAPLOG=$LOGDIR/snapshot.log
echo >> $SNAPLOG
echo "`date`: Post thaw script started" >> $SNAPLOG
exit_code=0
if [ -d "$LOGDIR" ]; then
# Only for running instances
for INST in `iris qall 2>/dev/null | tail -n +3 | grep '^up' | cut -c5- | awk '{print $1}'`; do
echo "`date`: Attempting to thaw $INST" >> $SNAPLOG
# Detailed instances specific log
LOGFILE=$LOGDIR/$INST-pre_post.log
# Thaw
irissession $INST -U%SYS "##Class(Backup.General).ExternalThaw(\"$LOGFILE\")" >> $SNAPLOG 2>&1
status=$?
case $status in
5) echo "`date`: $INST IS THAWED" >> $SNAPLOG
irissession $INST -U%SYS "##Class(Backup.General).ExternalSetHistory(\"$LOGFILE\")" >> $SNAPLOG$
;;
3) echo "`date`: $INST THAW FAILED" >> $SNAPLOG
logger -p user.err "thaw of $INST failed"
exit_code=1
;;
*) echo "`date`: ERROR: Unknown status code: $status" >> $SNAPLOG
logger -p user.err "ERROR when thawing $INST"
exit_code=1
;;
esac
echo "`date`: Completed thaw of $INST" >> $SNAPLOG
done
fi
echo "`date`: Post thaw script finished" >> $SNAPLOG
exit $exit_code
Lembre-se de definir as permissões:
# sudo chown root.root /usr/sbin/pre-freeze-script /usr/sbin/post-thaw-script
# sudo chmod 0700 /usr/sbin/pre-freeze-script /usr/sbin/post-thaw-script
Teste de congelamento e descongelamento
Para testar se os scripts estão funcionando corretamente, você pode executar uma cópia instantânea manualmente em uma VM e verificar a saída do script. A captura de tela a seguir mostra a caixa de diálogo "Take VM Snapshot" (Tirar a cópia instantânea da VM) e as opções.

Desmarque- "Snapshot the virtual machine's memory" (Tirar a cópia instantânea da memória da máquina virtual).
Selecione - a caixa de seleção "Quiesce guest file system (Needs VMware Tools installed)", ou "Colocar o sistema de arquivos convidado em modo quiesced (as ferramentas do VMware precisam estar instaladas)", para pausar os processos em execução no sistema operacional convidado, deixando o conteúdo do sistema de arquivos em um estado consistente conhecido ao tirar a cópia instantânea.
Importante! Depois do teste, lembre-se de excluir a cópia instantânea!!!!
Se a sinalização quiesce for verdadeira e a máquina virtual estiver ligada ao tirar a cópia instantânea, as ferramentas do VMware serão usadas para o quiesce do sistema de arquivos na máquina virtual. O quiesce do sistema de arquivos é o processo de colocar os dados no disco em um estado adequado para backups. Esse processo pode incluir operações como a limpeza de buffers sujos no cache da memória do sistema operacional para o disco.
A saída a seguir mostra o conteúdo do arquivo de log $SNAPSHOT definido nos scripts de congelamento/descongelamento acima após executar um backup que inclui uma cópia instantânea como parte da sua operação.
Wed Jan 4 16:30:35 EST 2017: Pre freeze script started
Wed Jan 4 16:30:35 EST 2017: Attempting to freeze H20152
Wed Jan 4 16:30:36 EST 2017: H20152 IS FROZEN
Wed Jan 4 16:30:36 EST 2017: Completed freeze of H20152
Wed Jan 4 16:30:36 EST 2017: Pre freeze script finished
Wed Jan 4 16:30:41 EST 2017: Post thaw script started
Wed Jan 4 16:30:41 EST 2017: Attempting to thaw H20152
Wed Jan 4 16:30:42 EST 2017: H20152 IS THAWED
Wed Jan 4 16:30:42 EST 2017: Completed thaw of H20152
Wed Jan 4 16:30:42 EST 2017: Post thaw script finished
Esse exemplo mostra os 6 segundos decorridos entre o congelamento e o descongelamento (16:30:36-16:30:42). As operações dos usuários NÃO são interrompidas durante esse período. Você precisará coletar métricas dos seus próprios sistemas, mas, para um pouco de contexto, esse exemplo é de um sistema que está executando um benchmark de aplicativo em uma VM sem gargalos de IO e com uma média de mais de 2 milhões de glorefs/s, 170.000 de gloupds/s, 1.100 gravações físicas/s e 3.000 gravações por ciclo de daemon de gravação.
Lembre-se de que a memória não faz parte da cópia instantânea, portanto, ao reiniciar, a VM será reinicializada e recuperada. Os arquivos de banco de dados serão consistentes. Você não quer "retomar" um backup, e sim quer os arquivos em um momento conhecido. Então, você pode fazer o roll forward dos diários e quaisquer outras etapas de recuperação necessárias para o aplicativo e a consistência transacional assim que os arquivos forem recuperados.
Para proteção de dados adicional, a troca do diário pode ser feita por si só, e os diários podem ser armazenados em backup ou replicados em outro local, por exemplo, a cada hora.
Confira abaixo a saída de $LOGFILE nos scripts de congelamento/descongelamento acima, mostrando os detalhes do diário para a cópia instantânea.
01/04/2017 16:30:35: Backup.General.ExternalFreeze: Suspending system
Journal file switched to:
/trak/jnl/jrnpri/h20152/H20152_20170104.011
01/04/2017 16:30:35: Backup.General.ExternalFreeze: Start a journal restore for this backup with journal file: /trak/jnl/jrnpri/h20152/H20152_20170104.011
Journal marker set at
offset 197192 of /trak/jnl/jrnpri/h20152/H20152_20170104.011
01/04/2017 16:30:36: Backup.General.ExternalFreeze: System suspended
01/04/2017 16:30:41: Backup.General.ExternalThaw: Resuming system
01/04/2017 16:30:42: Backup.General.ExternalThaw: System resumed
Tempos de stun da VM
No ponto de criação de uma cópia instantânea da VM e após a conclusão do backup e o commit do snapshot, a VM precisa ser congelada por um breve período. Esse pequeno congelamento costuma ser chamado de "stun" da VM. Veja uma ótima postagem de blog sobre os tempos de stun aqui. Resumo os detalhes abaixo e os contextualizo para as considerações do banco de dados do IRIS.
Da postagem sobre os tempos de stun: "Para criar uma cópia instantânea da VM, é feito o 'stun' da VM para (i) serializar o estado do dispositivo no disco e (ii) encerrar o disco que está em execução e criar um ponto da cópia instantânea… Durante a consolidação, é feito o 'stun' da VM para encerrar os discos e colocá-los em um estado apropriado para a consolidação."
O tempo de stun é normalmente algumas centenas de milésimos. No entanto, se houver uma atividade muito alta de gravação em disco durante a fase de commit, o tempo de stun poderá ser de vários segundos.
Se a VM estiver participando do Espelhamento do Banco de Dados do IRIS como um membro Primário ou de Backup, e o tempo de stun for maior que o tempo limite de Qualidade de Serviço (QoS) do espelho, o espelho relatará a falha da VM Primária e assumirá o controle.
Atualização de março de 2018:
Meu colega, Peter Greskoff, indicou que um membro espelho de backup poderia iniciar a tolerância a falhas na metade do tempo limite de QoS durante um stun da VM ou quando um membro espelho primário estiver indisponível.
Para conferir uma descrição detalhada das considerações de QoS e cenários de tolerância a falhas, consulte esta ótima postagem: Guia do Tempo Limite de Qualidade de Serviço para Espelhamento. Resumindo a questão dos tempos de stun da VM e QoS:
Se o espelho de backup não receber nenhuma mensagem do espelho primário dentro da metade do tempo limite de QoS, ele enviará uma mensagem para garantir que o primário ainda está ativo. Em seguida, o backup aguardará uma resposta da máquina primária pela outra metade do tempo de QoS. Se não houver resposta do primário, presume-se que ele está inativo, e o backup assumirá o controle.
Em um sistema ocupado, os diários são enviados continuamente do espelho primário para o espelho de backup, e o backup não precisa verificar se o primário ainda está ativo. No entanto, durante um período tranquilo — quando é mais provável que os backups ocorram —, se o aplicativo estiver ocioso, pode não haver mensagens entre o espelho primário e o de backup por mais da metade do tempo de QoS.
Confira abaixo o exemplo de Peter. Pense neste intervalo para um sistema ocioso com um tempo limite de QoS de 8 segundos e um tempo de stun da VM de 7 segundos:
- :00 O primário dá um ping no árbitro com um keepalive, e o árbitro responde imediatamente
- :01 O membro de backup envia o keepalive ao primário, e o primário responde imediatamente
- :02
- :03 Começa o stun da VM
- :04 O primário tenta enviar o keepalive ao árbitro, mas não consegue até a conclusão do stun
- :05 O membro de backup envia um ping ao primário, já que expirou metade da QoS
- :06
- :07
- :08 O árbitro não recebe resposta do primário durante todo o tempo limite de QoS, então encerra a conexão
- :09 O backup não recebeu uma resposta do primário e confirma com o árbitro que ele também perdeu a conexão, então assume o controle
- :10 O stun da VM acaba, tarde mais!!
Leia também a seção Pitfalls and Concerns when Configuring your Quality of Service Timeout (Armadilhas e Preocupações ao Configurar o Tempo Limite de Qualidade de Serviço) na postagem do link acima para entender o equilíbrio de ter a QoS somente pelo tempo necessário. Ter a QoS por muito tempo, especialmente por mais de 30 segundos, também pode causar problemas.
Final da atualização de março de 2018:
Para obter mais informações sobre a QoS do Espelhamento, consulte também a documentação.
As estratégias para reduzir ao mínimo o tempo de stun incluem executar backups quando houver pouca atividade no banco de dados e configurar bem o armazenamento.
Como observado acima, ao criar uma cópia instantânea, há várias opções que você pode especificar. Uma delas é incluir o estado da memória na cópia - Lembre-se, o estado da memória NÃO é necessário para backups de bancos de dados do IRIS. Se estiver configurada a sinalização da memória, um dump do estado interno da máquina virtual será incluído na cópia. A criação de cópias instantâneas da memória demora muito mais. As cópias da memória são usados para reverter o estado de uma máquina virtual em execução para como estava quando a cópia foi obtida. Isso NÃO é necessário para o backup de arquivos de um banco de dados.
Ao tirar uma cópia instantânea da memória, será realizado o stun de todo o estado da máquina virtual. O tempo de stun varia.
Como observado anteriormente, para backups, a sinalização do quiesce precisa ser definida como verdadeira para cópias manuais ou pelo software de backup para garantir um backup consistente e utilizável.
Revisar tempos de stun em logs do VMware
A partir do ESXi 5.0, os tempos de stun das cópias são registrados no arquivo de log de cada máquina virtual (vmware.log) com mensagens semelhantes a:
2017-01-04T22:15:58.846Z| vcpu-0| I125: Checkpoint_Unstun: vm stopped for 38123 us
Os tempos de stun estão em microssegundos. Então, no exemplo acima, 38123 us é 38123/1.000.000 segundos ou 0,038 segundos.
Para garantir que os tempos de stun estão dentro dos limites aceitáveis ou para solucionar problemas se você suspeitar que eles estão longos e causando problemas, baixe e revise os arquivos vmware.log da pasta da VM em que tem interesse. Depois de baixar, você pode extrair e ordenar o log usando os comandos Linux de exemplo abaixo.
Exemplo de download dos arquivos vmware.log
Há várias formas de baixar os logs de suporte, incluindo criando um pacote de suporte do VMware através do console de gerenciamento do vSphere ou da linha de comando do host ESXi. Consulte a documentação do VMware para ver todos os detalhes, mas abaixo está um método simples para criar e reunir um pacote de suporte bem menor que inclui o arquivo vmware.log para você revisar os tempos de stun.
Você precisará do nome longo do diretório onde os arquivos da VM estão localizados. Faça login no host ESXi onde a VM do banco de dados está em execução usando ssh e use o comando: vim-cmd vmsvc/getallvms para listar os arquivos vmx e os nomes longos exclusivos associados a eles.
Por exemplo, o nome longo da VM do banco de dados de exemplo usada nesta postagem fica assim:
26 vsan-tc2016-db1 [vsanDatastore] e2fe4e58-dbd1-5e79-e3e2-246e9613a6f0/vsan-tc2016-db1.vmx rhel7_64Guest vmx-11
Em seguida, execute o comando para reunir e empacotar apenas os arquivos de log:
vm-support -a VirtualMachines:logs.
O comando dará a localização do pacote de suporte, por exemplo:
To see the files collected, check '/vmfs/volumes/datastore1 (3)/esx-esxvsan4.iscinternal.com-2016-12-30--07.19-9235879.tgz'.
Agora você pode usar o sftp para transferir o arquivo para fora do host para processamento e análise adicional.
Nesse exemplo, após descompactar o pacote de suporte, acesse o caminho correspondente ao nome longo da VM do banco de dados. Por exemplo, nesse caso:
<bundle name>/vmfs/volumes/<host long name>/e2fe4e58-dbd1-5e79-e3e2-246e9613a6f0.
Você verá vários arquivos de log numerados. O arquivo de log mais recente não tem número, ou seja, vmware.log. O log pode ter só algumas centenas de KB, mas há muitas informações. Porém, queremos os tempos de stun/unstun, que são fáceis de encontrar com grep. Por exemplo:
$ grep Unstun vmware.log
2017-01-04T21:30:19.662Z| vcpu-0| I125: Checkpoint_Unstun: vm stopped for 1091706 us
---
2017-01-04T22:15:58.846Z| vcpu-0| I125: Checkpoint_Unstun: vm stopped for 38123 us
2017-01-04T22:15:59.573Z| vcpu-0| I125: Checkpoint_Unstun: vm stopped for 298346 us
2017-01-04T22:16:03.672Z| vcpu-0| I125: Checkpoint_Unstun: vm stopped for 301099 us
2017-01-04T22:16:06.471Z| vcpu-0| I125: Checkpoint_Unstun: vm stopped for 341616 us
2017-01-04T22:16:24.813Z| vcpu-0| I125: Checkpoint_Unstun: vm stopped for 264392 us
2017-01-04T22:16:30.921Z| vcpu-0| I125: Checkpoint_Unstun: vm stopped for 221633 us
Podemos ver dois grupos de tempos de stun no exemplo, um desde a criação da cópia instantânea e outro definido 45 minutos depois para cada disco quando a cópia foi excluído/consolidado (por exemplo, depois que o software de backup fez a cópia do arquivo vmx somente leitura). O exemplo acima mostra que a maioria dos tempos de stun é menor do que um segundo, mesmo que o tempo de stun inicial seja um pouco mais de um segundo.
Tempos de stun curtos não são perceptíveis para o usuário final. No entanto, os processos do sistema, como o Espelhamento do Banco de Dados do IRIS, verificam continuamente se uma instância está "ativa". Se o tempo de stun exceder o tempo limite de QoS do espelhamento, o nó poderá ser considerado fora de contato e "morto", e a tolerância a falhas será acionada.
Dica: para revisar todos os logs ou solucionar problemas, um comando útil é fazer o grep de todos os arquivos vmware*.log e procurar qualquer discrepância ou instância em que o tempo de stun chega próximo ao tempo limite de QoS. O seguinte comando canaliza a saída para awk para formatação:
grep Unstun vmware* | awk '{ printf ("%'"'"'d", $8)} {print " ---" $0}' | sort -nr
Resumo
Monitore seu sistema regularmente durante as operações normais para entender os tempos de stun e como eles podem afetar o tempo limite de QoS para HA, como o espelhamento. Como observado, as estratégias para reduzir ao mínimo o tempo de stun/unstun incluem executar backups quando houver pouca atividade no banco de dados e no armazenamento e configurar bem o armazenamento. Para monitoramento constante, os logs podem ser processados usando o VMware Log Insight ou outras ferramentas.
Em postagens futuras, revisitarei as operações de backup e restauração para as Plataformas de Dados da InterSystems. Por enquanto, caso você tenha algum comentário ou sugestão com base nos fluxos de trabalho dos seus sistemas, compartilhe nas seções de comentários abaixo.






