1. interoperability-embedded-python
Esta prova de conceito busca mostrar como o framework de interoperabilidade do iris pode ser usado com o embedded python.
1.1. Índice
1.2. Exemplo
from grongier.pex import BusinessOperation,Message
class MyBusinessOperation(BusinessOperation):
def on_init(self):
#Esse método é chamado quando o componente está se tornando ativo na produção
self.log_info("[Python] ...MyBusinessOperation:on_init() is called")
return
def on_teardown(self):
#Esse método é chamado quando o componente está se tornando inativo na produção
self.log_info("[Python] ...MyBusinessOperation:on_teardown() is called")
return
def on_message(self, message_input:MyRequest):
#É chamado do serviço/processo/operação, a mensagem é do tipo MyRequest com a propriedade request_string
self.log_info("[Python] ...MyBusinessOperation:on_message() is called with message:"+message_input.request_string)
response = MyResponse("...MyBusinessOperation:on_message() echos")
return response
@dataclass
class MyRequest(Message):
request_string:str = None
@dataclass
class MyResponse(Message):
my_string:str = None
1.3. Registrar um componente
Graças ao método grongier.pex.Utils.register_component():
Inicie um shell do embedded python:
/usr/irissys/bin/irispython
Em seguida, use esse método de classe para adicionar uma classe do python à lista de componentes para interoperabilidade.
from grongier.pex import Utils
Utils.register_component(<ModuleName>,<ClassName>,<PathToPyFile>,<OverWrite>,<NameOfTheComponent>)
Por exemplo:
from grongier.pex import Utils
Utils.register_component("MyCombinedBusinessOperation","MyCombinedBusinessOperation","/irisdev/app/src/python/demo/",1,"PEX.MyCombinedBusinessOperation")
Isso é um truque, e não serve para produção.
2. Demonstração
A demonstração pode ser encontrada em src/python/demo/reddit/ e é composta de:
Um arquivo adapter.py com um RedditInboundAdapter que, dado um serviço, buscará postagens recentes do Reddit.
Um arquivo bs.py com três services que faz a mesma coisa: ele chamará nosso Process e enviará a postagem do Reddit. Um funciona sozinho, um usa o RedditInBoundAdapter que mencionamos antes e o último usa um inbound adapter do Reddit codificado em ObjectScript.
Um arquivo bp.py com um processo FilterPostRoutingRule que analisará nossas postagens do Reddit e as enviará para nossas operations se tiverem determinadas palavras.
Um arquivo bo.py com:
- Duas operações de e-mail que enviarão um e-mail para uma empresa específica dependendo das palavras analisadas antes. Uma funciona sozinha e a outra funciona com um OutBoundAdapter.
- Duas operações de arquivo que escreverão em um arquivo de texto dependendo das palavras analisadas antes. Uma funciona sozinha e outra funciona com um OutBoundAdapter.
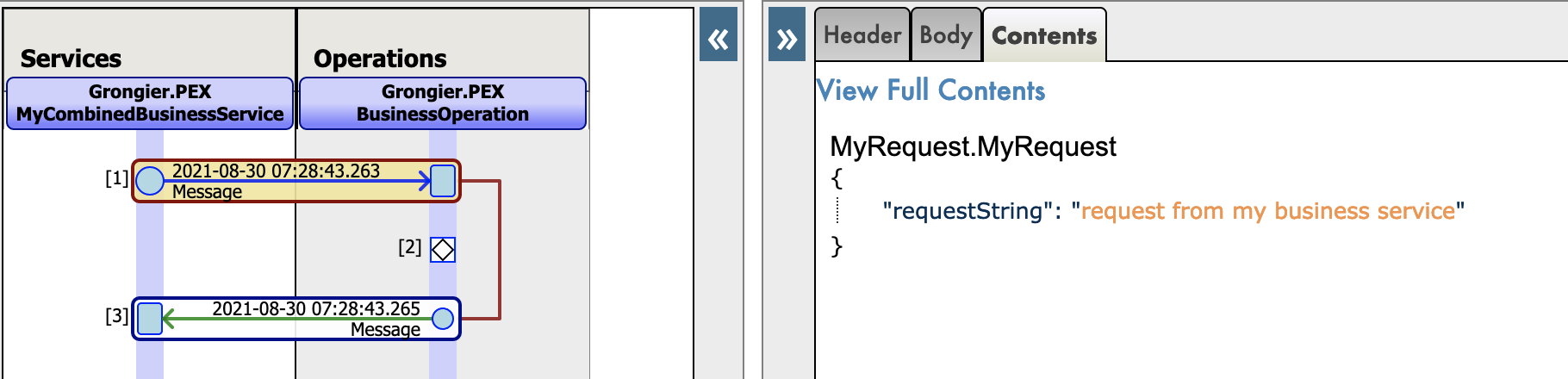
Novo trace json para mensagens nativas do python:
3. Pré-requisitos
Verifique se você tem o git e o Docker desktop instalados.
4. Instalação
4.1. Com Docker
Faça o git pull/clone do repositório em qualquer diretório local
git clone https://github.com/grongierisc/interpeorability-embedded-python
Abra o terminal nesse diretório e execute:
docker-compose build
Execute o contêiner IRIS com seu projeto:
docker-compose up -d
4.2. Sem Docker
Instale o grongier_pex-1.2.4-py3-none-any.whl na sua instância iris local:
/usr/irissys/bin/irispython -m pip install grongier_pex-1.2.4-py3-none-any.whl
Em seguida, carregue as classes ObjectScript:
do $System.OBJ.LoadDir("/opt/irisapp/src","cubk","*.cls",1)
4.3. Com ZPM
zpm "install pex-embbeded-python"
4.4. Com PyPI
pip3 install iris_pex_embedded_python
Importe as classes ObjectScript, abra um shell do embedded python e execute:
from grongier.pex import Utils
Utils.setup()
4.4.1. Problemas conhecidos
Se o módulo não estiver atualizado, remova a versão antiga:
pip3 uninstall iris_pex_embedded_python
ou remova manualmente a pasta grongier em <iris_installation>/lib/python/
ou force a instalação com o pip:
pip3 install --upgrade iris_pex_embedded_python --target <iris_installation>/lib/python/
5. Como executar a amostra
5.1. Contêineres Docker
Para ter acesso às imagens da InterSystems, é necessário acessar o seguinte URL: http://container.intersystems.com. Depois de se conectar com as credenciais da InterSystems, obtenha a senha para se conectar ao registro. No complemento VSCode do docker, na guia de imagens, ao pressionar "connect registry" e inserir o mesmo url de antes (http://container.intersystems.com) como um registro genérico, será solicitado as credenciais. O login é o habitual, mas a senha é a obtida do site.
Em seguida, será possível criar e compor os contêineres (com os arquivos docker-compose.yml e Dockerfile fornecidos).
5.2. Portal de Gerenciamento e VSCode
Esse repositório está pronto para o VS Code.
Abra a pasta interoperability-embedeed-python clonada localmente no VS Code.
Se solicitado (canto inferior direito), instale as extensões recomendadas.
IMPORTANTE: quando solicitado, reabra a pasta dentro do contêiner, para que você possa usar os componentes do python dentro dele. Na primeira vez que você fizer isso, o contêiner pode levar vários minutos para ficar pronto.
Ao abrir a pasta remota, você permite que o VS Code e quaisquer terminais abertos dentro dele usem os componentes do python dentro do contêiner. Configure-os para usar /usr/irissys/bin/irispython

5.3. Abra a produção
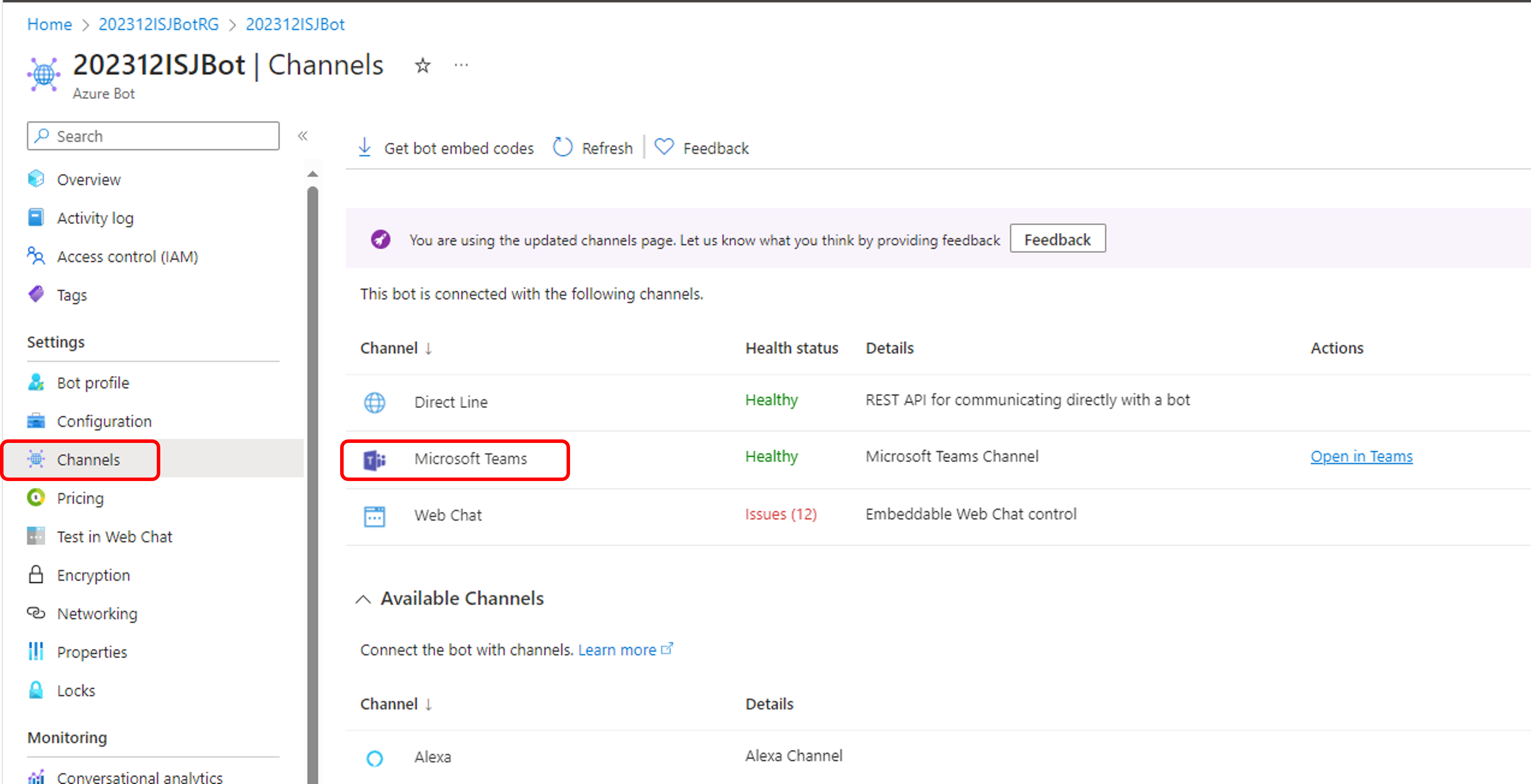
Para abrir a produção, você pode acessar a [produção]
(http://localhost:52773/csp/irisapp/EnsPortal.ProductionConfig.zen?PRODUCTION=PEX.Production).
Você também pode clicar na parte inferior no botão 127.0.0.1:52773[IRISAPP], selecionar Open Management Portal(Abrir Portal de Gerenciamento), clicar nos menus [Interoperability] e [Configure] e, depois, em [productions] e [Go].
A produção já tem uma amostra de código.
Aqui podemos ver a produção e nossos serviços e operações de python puro:

Novo trace json para mensagens nativas do python:
6. O que está dentro do repositório
6.1. Dockerfile
Um dockerfile que instala algumas dependências do python (pip, venv) e sudo no contêiner para conveniência.
Em seguida, ele cria o diretório dev e copia nele esse repositório git.
Ele inicia o IRIS e ativa %Service_CallIn para o Shell do Python.
Use o docker-compose.yml relacionado para configurar facilmente parâmetros adicionais, como número da porta e onde você mapeia chaves e hospeda pastas.
Esse dockerfile termina com a instalação dos requisitos para os módulos do python.
Use o arquivo .env/ para ajustar o dockerfile usado em docker-compose.
6.2. .vscode/settings.json
Arquivo de configurações para você programar imediatamente no VSCode com o [plugin ObjectScript do VSCode] (https://marketplace.visualstudio.com/items?itemName=daimor.vscode-objectscript)
6.3. .vscode/launch.json
Arquivo de configurações se você quiser depurar com o ObjectScript do VSCode
Leia sobre todos os arquivos neste artigo
6.4. .vscode/extensions.json
Arquivo de recomendação para adicionar extensões se você quiser executar com o VSCode no contêiner.
Mais informações aqui

Isso é muito útil para trabalhar com o embedded python.
6.5. src folder
src
├── Grongier
│ └── PEX // Classes ObjectScript que envolvem código em python
│ ├── BusinessOperation.cls
│ ├── BusinessProcess.cls
│ ├── BusinessService.cls
│ ├── Common.cls
│ ├── Director.cls
│ ├── InboundAdapter.cls
│ ├── Message.cls
│ ├── OutboundAdapter.cls
│ ├── Python.cls
│ ├── Test.cls
│ └── _utils.cls
├── PEX // Alguns exemplos de classes envolvidas
│ └── Production.cls
└── python
├── demo // código em python real para executar essa demonstração
| `-- reddit
| |-- adapter.py
| |-- bo.py
| |-- bp.py
| |-- bs.py
| |-- message.py
| `-- obj.py
├── dist // Wheel usado para implementar componentes de interoperabilidade do python
│ └── grongier_pex-1.2.4-py3-none-any.whl
├── grongier
│ └── pex // Classes helper para implementar componentes de interoperabilidade
│ ├── _business_host.py
│ ├── _business_operation.py
│ ├── _business_process.py
│ ├── _business_service.py
│ ├── _common.py
│ ├── _director.py
│ ├── _inbound_adapter.py
│ ├── _message.py
│ ├── _outbound_adapter.py
│ ├── __init__.py
│ └── _utils.py
└── setup.py // configuração para criar o wheel
7. Como funciona
7.1. Arquivo __init__.py
Esse arquivo nos permite criar as classes para importar no código.
Ele obtém as classes de vários arquivos vistos antes e as transforma em classes callable.
Assim, quando você quiser criar uma operação de negócios, por exemplo, pode só executar:
from grongier.pex import BusinessOperation
7.2. Classe common
A classe common não deve ser chamada pelo usuário. Ela define quase todas as outras classes.
Essa classe define:
on_init: esse método é chamado quando o componente é inicializado.
Use o método on_init() para inicializar qualquer estrutura necessária para o componente.
on_tear_down: é chamado antes de encerrar o componente.
Use para liberar qualquer estrutura.
on_connected: esse método é chamado quando o componente é conectado ou reconectado após ser desconectado.
Use o método on_connected() para inicializar qualquer estrutura necessária para o componente.
log_info: grava uma entrada de log do tipo "info". As entradas de log podem ser visualizadas no portal de gerenciamento.
log_alert: grava uma entrada de log do tipo "alert". As entradas de log podem ser visualizadas no portal de gerenciamento.
log_warning: grava uma entrada de log do tipo "warning". As entradas de log podem ser visualizadas no portal de gerenciamento.
log_error: grava uma entrada de log do tipo "error". As entradas de log podem ser visualizadas no portal de gerenciamento.
7.3. Classe business_host
A classe de host de negócios não deve ser chamada pelo usuário. É a classe base para todas as classes de negócios.
Essa classe define:
send_request_sync: envia a mensagem específica à operação ou ao processo de negócios alvo de maneira síncrona.
Parâmetros:
- target: uma string que especifica o nome da operação ou do processo de negócios a receber a solicitação.
O alvo é o nome do componente conforme especificado na propriedade Item Name na definição da produção, e não o nome da classe do componente. - request: especifica a mensagem a enviar ao alvo. A solicitação é uma instância de uma classe que é IRISObject ou subclasse da classe Message.
Se o alvo é um componente ObjectScript integrado, você deve usar a classe IRISObject. A classe IRISObject permite que o framework PEX converta a mensagem para uma classe compatível com o alvo. - timeout: um inteiro opcional que especifica o número de segundos de espera antes de tratar a solicitação de envio como uma falha. O valor padrão é -1, que significa "esperar para sempre".
description: um parâmetro de string opcional que define uma propriedade da descrição no cabeçalho da mensagem. O padrão é None.
Retorna:
o objeto de resposta do alvo.
Gera:
TypeError: se a solicitação não é do tipo Message ou IRISObject.
send_request_async: envia a mensagem específica ao processo ou operação de negócios alvo de maneira assíncrona.
Parâmetros:
- target: uma string que especifica o nome da operação ou do processo de negócios a receber a solicitação.
O alvo é o nome do componente conforme especificado na propriedade Item Name na definição da produção, e não o nome da classe do componente. - request: especifica a mensagem a enviar ao alvo. A solicitação é uma instância de IRISObject ou de uma subclasse de Message.
Se o alvo é um componente ObjectScript integrado, você deve usar a classe IRISObject. A classe IRISObject permite que o framework PEX converta a mensagem para uma classe compatível com o alvo. - description: um parâmetro de string opcional que define uma propriedade da descrição no cabeçalho da mensagem. O padrão é None.
Gera:
TypeError: se a solicitação não é do tipo Message ou IRISObject.
get_adapter_type: nome do adaptador registrado.
7.4. Classe inbound_adapter
Inbound Adapter no Python é uma subclasse de grongier.pex.InboundAdapter no Python, que herda de todas as funções da classe common.
Essa classe é responsável por receber os dados do sistema externo, validar os dados e enviá-los ao serviço de negócios ao chamar o método process_input de BusinessHost.
Essa classe define:
on_task: é chamado pelo framework de produção a intervalos determinados pela propriedade CallInterval do serviço de negócios.
A mensagem pode ter qualquer estrutura que esteja de acordo com o inbound adapter e serviço de negócios.
Exemplo de um inbound adapter (localizado no arquivo src/python/demo/reddit/adapter.py):
from grongier.pex import InboundAdapter
import requests
import iris
import json
class RedditInboundAdapter(InboundAdapter):
"""
Esse adaptador usa solicitações para buscar postagens self.limit como dados da API Reddit
antes de chamar o process_input para cada postagem.
"""
def on_init(self):
if not hasattr(self,'feed'):
self.feed = "/new/"
if self.limit is None:
raise TypeError('no Limit field')
self.last_post_name = ""
return 1
def on_task(self):
self.log_info(f"LIMIT:{self.limit}")
if self.feed == "" :
return 1
tSC = 1
# Solicitação HTTP
try:
server = "https://www.reddit.com"
request_string = self.feed+".json?before="+self.last_post_name+"&limit="+self.limit
self.log_info(server+request_string)
response = requests.get(server+request_string)
response.raise_for_status()
data = response.json()
updateLast = 0
for key, value in enumerate(data['data']['children']):
if value['data']['selftext']=="":
continue
post = iris.cls('dc.Reddit.Post')._New()
post._JSONImport(json.dumps(value['data']))
post.OriginalJSON = json.dumps(value)
if not updateLast:
self.LastPostName = value['data']['name']
updateLast = 1
response = self.BusinessHost.ProcessInput(post)
except requests.exceptions.HTTPError as err:
if err.response.status_code == 429:
self.log_warning(err.__str__())
else:
raise err
except Exception as err:
self.log_error(err.__str__())
raise err
return tSC
7.5. Classe outbound_adapter
Outbound Adapter no Python é uma subclasse de grongier.pex.OutboundAdapter no Python, que herda de todas as funções da classe common.
Essa classe é responsável por enviar os dados para o sistema externo.
O Outbound Adapter possibilita à operação ter uma noção dos batimentos cardíacos.
Para ativar essa opção, o parâmetro CallInterval do adaptador precisa ser estritamente maior que 0.

Exemplo de um outbound adapter (localizado no arquivo src/python/demo/reddit/adapter.py):
class TestHeartBeat(OutboundAdapter):
def on_keepalive(self):
self.log_info('beep')
def on_task(self):
self.log_info('on_task')
7.6. Classe business_service
Essa classe é responsável por receber os dados do sistema externo e enviá-los aos processos ou operações de negócios na produção.
O serviço de negócios pode usar um adaptador para acessar o sistema externo, que é especificado sobrescrevendo o método get_adaptar_type.
Há três maneiras de implementar um serviço de negócios:
Serviço de negócios de sondagem com um adaptador - O framework de produção chama a intervalos regulares o método OnTask() do adaptador,
que envia os dados recebidos ao método ProcessInput() do serviço de negócios, que, por sua vez, chama o método OnProcessInput com seu código.
Serviço de negócios de sondagem que usa o adaptador padrão - Nesse caso, o framework chama o método OnTask do adaptador padrão sem dados.
Em seguida, o método OnProcessInput() realiza o papel do adaptador e é responsável por acessar o sistema externo e receber os dados.
Serviço de negócios sem sondagem - O framework de produção não inicia o serviço de negócios. Em vez disso, o código personalizado em um processo longo
ou um que é inicializado a intervalos regulares inicia o serviço de negócios ao chamar o método Director.CreateBusinessService().
O serviço de negócios no Python é uma subclasse de grongier.pex.BusinessService no Python, que herda de todas as funções do host de negócios.
Essa classe define:
on_process_input: recebe a mensagem do inbound adapter pelo método ProcessInput e é responsável por encaminhá-la aos processos ou operações de negócios alvo.
Se o serviço de negócios não especifica um adaptador, o adaptador padrão chama esse método sem mensagem e o serviço de negócios é responsável por receber os dados do sistema externo e validá-los.
Parâmetros:
- message_input: uma instância de IRISObject ou subclasse de Message com os dados que o inbound adapter transmite.
A mensagem pode ter qualquer estrutura que esteja de acordo com o inbound adapter e serviço de negócios.
Exemplo de um serviço de negócios (localizado no arquivo src/python/demo/reddit/bs.py):
from grongier.pex import BusinessService
import iris
from message import PostMessage
from obj import PostClass
class RedditServiceWithPexAdapter(BusinessService):
"""
This service use our python Python.RedditInboundAdapter to receive post
from reddit and call the FilterPostRoutingRule process.
"""
def get_adapter_type():
"""
Name of the registred Adapter
"""
return "Python.RedditInboundAdapter"
def on_process_input(self, message_input):
msg = iris.cls("dc.Demo.PostMessage")._New()
msg.Post = message_input
return self.send_request_sync(self.target,msg)
def on_init(self):
if not hasattr(self,'target'):
self.target = "Python.FilterPostRoutingRule"
return
7.7. Classe business_process
Geralmente, contém a maior parte da lógica em uma produção.
Um processo de negócios pode receber mensagens de um serviço, processo ou operação de negócios.
Ele pode modificar a mensagem, convertê-la para um formato diferente ou roteá-la com base no conteúdo dela.
O processo de negócios pode rotear uma mensagem para uma operação ou outro processo de negócios.
Os processos de negócios no Python são uma subclasse de grongier.pex.BusinessProcess no Python, que herda de todas as funções do host de negócios.
Essa classe define:
on_request: processa as solicitações enviadas ao processo de negócios. Uma produção chama esse método quando uma solicitação inicial de um processo de negócios específico chega na fila apropriada e é atribuída a um trabalho em que deve ser executada.
Parâmetros:
- request: uma instância de IRISObject ou subclasse de Message que contém a mensagem de solicitação enviada ao processo de negócios.
Retorna:
Uma instância de IRISObject ou subclasse de Message que contém a mensagem de resposta que esse processo de negócios pode retornar
ao componente de produção que enviou a mensagem inicial.
on_response: processa as respostas enviadas ao processo de negócios em resposta às mensagens ele que enviou ao alvo.
Uma produção chama esse método sempre que uma resposta a um processo de negócios específico chega na fila apropriada e é atribuída a um trabalho em que deve ser executada.
Geralmente, isso é uma resposta a uma solicitação assíncrona feita pelo processo de negócios onde o parâmetro responseRequired tem um valor "true".
Parâmetros:
- request: uma instância de IRISObject ou subclasse de Message que contém a mensagem de solicitação inicial enviada ao processo de negócios.
- response: uma instância de IRISObject ou subclasse de Message que contém a mensagem de resposta que esse processo de negócios pode retornar ao componente de produção que enviou a mensagem inicial.
- callRequest: uma instância de IRISObject ou subclasse de Message que contém a solicitação que o processo de negócios enviou ao seu alvo.
- callResponse: uma instância de IRISObject ou subclasse de Message que contém a resposta de entrada.
- completionKey: uma string que contém a completionKey especificada no parâmetro completionKey do método SendAsync() de saída.
Retorna:
Uma instância de IRISObject ou subclasse de Message que contém a mensagem de resposta que esse processo de negócios pode retornar
ao componente de produção que enviou a mensagem inicial.
on_complete: é chamado depois que o processo de negócios recebeu e processou todas as respostas às solicitações que enviou aos alvos.
Parâmetros:
- request: uma instância de IRISObject ou subclasse de Message que contém a mensagem de solicitação inicial enviada ao processo de negócios.
- response: uma instância de IRISObject ou subclasse de Message que contém a mensagem de resposta que esse processo de negócios pode retornar ao componente de produção que enviou a mensagem inicial.
Retorna:
Uma instância de IRISObject ou subclasse de Message que contém a mensagem de resposta que esse processo de negócios pode retornar ao componente de produção que enviou a mensagem inicial.
Exemplo de um processo de negócios (localizado no arquivo src/python/demo/reddit/bp.py):
from grongier.pex import BusinessProcess
from message import PostMessage
from obj import PostClass
class FilterPostRoutingRule(BusinessProcess):
"""
This process receive a PostMessage containing a reddit post.
It then understand if the post is about a dog or a cat or nothing and
fill the right infomation inside the PostMessage before sending it to
the FileOperation operation.
"""
def on_init(self):
if not hasattr(self,'target'):
self.target = "Python.FileOperation"
return
def on_request(self, request):
if 'dog'.upper() in request.post.selftext.upper():
request.to_email_address = 'dog@company.com'
request.found = 'Dog'
if 'cat'.upper() in request.post.selftext.upper():
request.to_email_address = 'cat@company.com'
request.found = 'Cat'
if request.found is not None:
return self.send_request_sync(self.target,request)
else:
return
7.8. Classe business_operation
Essa classe é responsável por enviar os dados a um sistema externo ou local como um banco de dados do iris.
A operação de negócios pode usar opcionalmente um adaptador para processar a mensagem de saída que é especificada sobrescrevendo o método get_adapter_type.
Se a operação de negócios tiver um adaptador, ela usa o adaptador para enviar a mensagem ao sistema externo.
O adaptador pode ser um adaptador PEX, ObjectScript ou python.
A operação de negócios no Python é uma subclasse de grongier.pex.BusinessOperation no Python, que herda de todas as funções do host de negócios.
7.8.1. Sistema de despacho
Em uma operação de negócios, é possível criar qualquer número de funções semelhante ao método on_message que aceitam como argumento uma solicitação tipada como esse my_special_message_method(self,request: MySpecialMessage).
O sistema de despacho analisará automaticamente qualquer solicitação que chegar à operação e despachará as solicitações dependendo do tipo delas. Se o tipo de solicitação não for reconhecido ou não estiver especificado em qualquer função semelhante a on_message, o sistema de despacho a enviará para a função on_message.
7.8.2. Métodos
Essa classe define:
on_message: é chamado quando a operação de negócios recebe uma mensagem de outro componente da produção que não pode ser despachada a outra função.
Geralmente, a operação envia a mensagem ao sistema externo ou a encaminha para um processo ou outra operação de negócios.
Se a operação tiver um adaptador, ela usa o método Adapter.invoke() para chamar o método no adaptador que envia a mensagem ao sistema externo.
Se a operação estiver encaminhando a mensagem a outro componente da produção, ela usa o método SendRequestAsync() ou SendRequestSync().
Parâmetros:
- request: uma instância de IRISObject ou subclasse de Message que contém a mensagem de entrada para a operação de negócios.
Retorna:
O objeto de resposta
Exemplo de uma operação de negócios (localizada no arquivo src/python/demo/reddit/bo.py):
from grongier.pex import BusinessOperation
from message import MyRequest,MyMessage
import iris
import os
import datetime
import smtplib
from email.mime.text import MIMEText
class EmailOperation(BusinessOperation):
"""
This operation receive a PostMessage and send an email with all the
important information to the concerned company ( dog or cat company )
"""
def my_message(self,request:MyMessage):
sender = 'admin@example.com'
receivers = 'toto@example.com'
port = 1025
msg = MIMEText(request.toto)
msg['Subject'] = 'MyMessage'
msg['From'] = sender
msg['To'] = receivers
with smtplib.SMTP('localhost', port) as server:
server.sendmail(sender, receivers, msg.as_string())
print("Successfully sent email")
def on_message(self, request):
sender = 'admin@example.com'
receivers = [ request.to_email_address ]
port = 1025
msg = MIMEText('This is test mail')
msg['Subject'] = request.found+" found"
msg['From'] = 'admin@example.com'
msg['To'] = request.to_email_address
with smtplib.SMTP('localhost', port) as server:
# server.login('username', 'password')
server.sendmail(sender, receivers, msg.as_string())
print("Successfully sent email")
Se essa operação for chamada usando uma mensagem MyRequest, a função my_message será chamada graças ao dispatcher. Caso contrário, a função on_message será chamada.
7.9. Classe director
A classe Director é usada para serviços de negócios sem sondagem, ou seja, serviços de negócios que não são chamados automaticamente pelo framework da produção (pelo inbound adapter) no intervalo da chamada.
Em vez disso, esses serviços de negócios são criados por um aplicativo personalizado ao chamar o método Director.create_business_service().
Essa classe define:
create_business_service: esse método inicia o serviço de negócios especificado.
Parâmetros:
- connection: um objeto IRISConnection que especifica a conexão a uma instância IRIS para Java.
- target: uma string que especifica o nome do serviço de negócios na definição da produção.
Retorna:
um objeto que contém uma instância de IRISBusinessService
start_production: esse método inicia a produção.
Parâmetros:
- production_name: uma string que especifica o nome da produção a iniciar.
stop_production: esse método interrompe a produção.
Parâmetros:
- production_name: uma string que especifica o nome da produção a interromper.
restart_production: esse método reinicia a produção.
Parâmetros:
- production_name: uma string que especifica o nome da produção a reiniciar.
list_productions: esse método retorna um dicionário de nomes das produções que estão sendo executadas no momento.
7.10. Os objects
Vamos usar dataclass para armazenar informações em nossas mensagens em um arquivo obj.py.
Exemplo de um objeto (localizado no arquivo src/python/demo/reddit/obj.py):
from dataclasses import dataclass
@dataclass
class PostClass:
title: str
selftext : str
author: str
url: str
created_utc: float = None
original_json: str = None
7.11. As messages
As mensagens conterão um ou mais objetos, localizados no arquivo obj.py.
Mensagens, solicitações e respostas herdam da classe grongier.pex.Message.
Essas mensagens nos permitem transferir informações entre qualquer serviço/processo/operação de negócios.
Exemplo de uma mensagem (localizada no arquivo src/python/demo/reddit/message.py):
from grongier.pex import Message
from dataclasses import dataclass
from obj import PostClass
@dataclass
class PostMessage(Message):
post:PostClass = None
to_email_address:str = None
found:str = None
WIP Vale destacar que é necessário usar tipos ao definir um objeto ou uma mensagem.
7.12. Como registrar um componente
Você pode registrar um componente no iris de várias formas:
- Somente um componente com
register_component - Todos os componentes em um arquivo com
register_file - Todos os componentes em um arquivo com
register_folder
7.12.1. register_component
Inicie um shell do embedded python:
/usr/irissys/bin/irispython
Em seguida, use esse método de classe para adicionar um novo arquivo py à lista de componentes para interoperabilidade.
from grongier.pex import Utils
Utils.register_component(<ModuleName>,<ClassName>,<PathToPyFile>,<OverWrite>,<NameOfTheComponent>)
Por exemplo:
from grongier.pex import Utils
Utils.register_component("MyCombinedBusinessOperation","MyCombinedBusinessOperation","/irisdev/app/src/python/demo/",1,"PEX.MyCombinedBusinessOperation")
7.12.2. register_file
Inicie um shell do embedded python:
/usr/irissys/bin/irispython
Em seguida, use esse método de classe para adicionar um novo arquivo py à lista de componentes para interoperabilidade.
from grongier.pex import Utils
Utils.register_file(<File>,<OverWrite>,<PackageName>)
Por exemplo:
from grongier.pex import Utils
Utils.register_file("/irisdev/app/src/python/demo/bo.py",1,"PEX")
7.12.3. register_folder
Inicie um shell do embedded python:
/usr/irissys/bin/irispython
Em seguida, use esse método de classe para adicionar um novo arquivo py à lista de componentes para interoperabilidade.
from grongier.pex import Utils
Utils.register_folder(<Path>,<OverWrite>,<PackageName>)
Por exemplo:
from grongier.pex import Utils
Utils.register_folder("/irisdev/app/src/python/demo/",1,"PEX")
7.12.4. migrate
Inicie um shell do embedded python:
/usr/irissys/bin/irispython
Em seguida, use esse método estático para migrar o arquivo de configurações para o framework iris.
from grongier.pex import Utils
Utils.migrate()
7.12.4.1. Arquivo setting.py
Esse arquivo é usado para armazenar as configurações dos componentes de interoperabilidade.
Ele tem duas seções:
CLASSES: essa seção é usada para armazenar as classes dos componentes de interoperabilidade.PRODUCTIONS: essa seção é usada para armazenar as classes dos componentes de interoperabilidade.
Por exemplo:
import bp
from bo import *
from bs import *
CLASSES = {
'Python.RedditService': RedditService,
'Python.FilterPostRoutingRule': bp.FilterPostRoutingRule,
'Python.FileOperation': FileOperation,
'Python.FileOperationWithIrisAdapter': FileOperationWithIrisAdapter,
}
PRODUCTIONS = [
{
'dc.Python.Production': {
"@Name": "dc.Demo.Production",
"@TestingEnabled": "true",
"@LogGeneralTraceEvents": "false",
"Description": "",
"ActorPoolSize": "2",
"Item": [
{
"@Name": "Python.FileOperation",
"@Category": "",
"@ClassName": "Python.FileOperation",
"@PoolSize": "1",
"@Enabled": "true",
"@Foreground": "false",
"@Comment": "",
"@LogTraceEvents": "true",
"@Schedule": "",
"Setting": {
"@Target": "Host",
"@Name": "%settings",
"#text": "path=/tmp"
}
},
{
"@Name": "Python.RedditService",
"@Category": "",
"@ClassName": "Python.RedditService",
"@PoolSize": "1",
"@Enabled": "true",
"@Foreground": "false",
"@Comment": "",
"@LogTraceEvents": "false",
"@Schedule": "",
"Setting": [
{
"@Target": "Host",
"@Name": "%settings",
"#text": "limit=10\nother<10"
}
]
},
{
"@Name": "Python.FilterPostRoutingRule",
"@Category": "",
"@ClassName": "Python.FilterPostRoutingRule",
"@PoolSize": "1",
"@Enabled": "true",
"@Foreground": "false",
"@Comment": "",
"@LogTraceEvents": "false",
"@Schedule": ""
}
]
}
}
]
7.12.4.1.1. Seção CLASSES
Essa seção é usada para armazenar as produções dos componentes de interoperabilidade.
Ela visa ajudar a registrar os componentes.
Esse dicionário tem a seguinte estrutura:
- Chave: nome do componente
- Valor:
- Classe do componente (você precisa importar antes)
- Módulo do componente (você precisa importar antes)
- Outro dicionário com a seguinte estrutura:
module : nome do módulo do componente (opcional)class : nome da classe do componente (opcional)path : caminho do componente (obrigatório)
Por exemplo:
Quando o valor é uma classe ou módulo:
import bo
import bp
from bs import RedditService
CLASSES = {
'Python.RedditService': RedditService,
'Python.FilterPostRoutingRule': bp.FilterPostRoutingRule,
'Python.FileOperation': bo,
}
Quando o valor é um dicionário:
CLASSES = {
'Python.RedditService': {
'module': 'bs',
'class': 'RedditService',
'path': '/irisdev/app/src/python/demo/'
},
'Python.Module': {
'module': 'bp',
'path': '/irisdev/app/src/python/demo/'
},
'Python.Package': {
'path': '/irisdev/app/src/python/demo/'
},
}
7.12.4.1.2. Seção de produções
Essa seção é usada para armazenar as produções dos componentes de interoperabilidade.
Ela visa ajudar a registrar uma produção.
Essa lista tem a seguinte estrutura:
- Uma lista do dicionário com a seguinte estrutura:
dc.Python.Production: nome da produção
@Name: nome da produção@TestingEnabled: enabled de teste da produção@LogGeneralTraceEvents: eventos de rastreamento gerais do log da produçãoDescription: descrição da produçãoActorPoolSize: tamanho do pool de atores da produçãoItem: lista dos itens da produção
@Name: nome do item@Category: categoria do item@ClassName: nome da classe do item@PoolSize: tamanho do pool do item@Enabled: enabled do item@Foreground: foreground do item@Comment: comentário do item@LogTraceEvents: eventos de rastreamento do log do item@Schedule: programação do itemSetting: lista de configurações do item
@Target: alvo da configuração@Name: nome da configuração#text: valor da configuração
A estrutura mínima de uma produção é:
PRODUCTIONS = [
{
'UnitTest.Production': {
"Item": [
{
"@Name": "Python.FileOperation",
"@ClassName": "Python.FileOperation",
},
{
"@Name": "Python.EmailOperation",
"@ClassName": "UnitTest.Package.EmailOperation"
}
]
}
}
]
Você também pode definir em @ClassName um item da seção CLASSES.
Por exemplo:
from bo import FileOperation
PRODUCTIONS = [
{
'UnitTest.Production': {
"Item": [
{
"@Name": "Python.FileOperation",
"@ClassName": FileOperation,
}
]
}
}
]
Como a produção é um dicionário, você pode adicionar no valor do dicionário de produção uma variável de ambiente.
Por exemplo:
import os
PRODUCTIONS = [
{
'UnitTest.Production': {
"Item": [
{
"@Name": "Python.FileOperation",
"@ClassName": "Python.FileOperation",
"Setting": {
"@Target": "Host",
"@Name": "%settings",
"#text": os.environ['SETTINGS']
}
}
]
}
}
]
7.13. Uso direto de Grongier.PEX
Se você não quiser usar o utilitário register_component, é possível adicionar um componente Grongier.PEX.BusinessService diretamente no portal de gerenciamento e configurar as propriedades:
- %module:
- Nome do módulo do seu código em python
- %classname:
- Nome da classe do seu componente
- %classpaths:
- Caminho onde está seu componente.
- Pode ser um ou mais caminhos de classe (separados pelo caractere '|') necessários além de PYTHON_PATH
Por exemplo:

8. Linha de comando
Desde a versão 2.3.1, você pode usar a linha de comando para registrar seus componentes e produções.
Para usá-la, você precisa utilizar o seguinte comando:
iop
saída:
usage: python3 -m grongier.pex [-h] [-d DEFAULT] [-l] [-s START] [-k] [-S] [-r] [-M MIGRATE] [-e EXPORT] [-x] [-v] [-L]
optional arguments:
-h, --help display help and default production name
-d DEFAULT, --default DEFAULT
set the default production
-l, --lists list productions
-s START, --start START
start a production
-k, --kill kill a production (force stop)
-S, --stop stop a production
-r, --restart restart a production
-M MIGRATE, --migrate MIGRATE
migrate production and classes with settings file
-e EXPORT, --export EXPORT
export a production
-x, --status status a production
-v, --version display version
-L, --log display log
default production: PEX.Production
8.1. help
O comando help exibe a ajuda e o nome da produção padrão.
iop -h
saída:
usage: python3 -m grongier.pex [-h] [-d DEFAULT] [-l] [-s START] [-k] [-S] [-r] [-M MIGRATE] [-e EXPORT] [-x] [-v] [-L]
...
default production: PEX.Production
8.2. default
O comando default define a produção padrão.
Sem argumento, ele exibe a produção padrão.
iop -d
saída:
default production: PEX.Production
Com argumento, ele define a produção padrão.
iop -d PEX.Production
8.3. lists
O comando lists lista produções.
iop -l
saída:
{
"PEX.Production": {
"Status": "Stopped",
"LastStartTime": "2023-05-31 11:13:51.000",
"LastStopTime": "2023-05-31 11:13:54.153",
"AutoStart": 0
}
}
8.4. start
O comando start inicia uma produção.
Para sair do comando, pressione CTRL+C.
iop -s PEX.Production
saída:
2021-08-30 15:13:51.000 [PEX.Production] INFO: Starting production
2021-08-30 15:13:51.000 [PEX.Production] INFO: Starting item Python.FileOperation
2021-08-30 15:13:51.000 [PEX.Production] INFO: Starting item Python.EmailOperation
...
8.5. kill
O comando kill encerra uma produção à força.
O comando kill é igual ao comando stop, mas força o encerramento.
O comando kill não aceita argumentos, porque só pode ser executada uma produção.
iop -k
8.6. stop
O comando stop interrompe uma produção.
O comando stop não aceita argumentos, porque só pode ser executada uma produção.
iop -S
8.7. restart
O comando restart reinicia uma produção.
O comando restart não aceita argumentos, porque só pode ser executada uma produção.
iop -r
8.8. migrate
O comando migrate migra uma produção e classes com o arquivo de configurações.
O comando migate precisa receber o caminho absoluto do arquivo de configurações.
O arquivo de configurações precisa estar na mesma pasta que o código em python.
iop -M /tmp/settings.py
8.9. export
O comando export exporta uma produção.
Se nenhum argumento for fornecido, o comando export exporta a produção padrão.
iop -e
Se um argumento for fornecido, o comando export exporta a produção indicada no argumento.
iop -e PEX.Production
saída:
{
"Production": {
"@Name": "PEX.Production",
"@TestingEnabled": "true",
"@LogGeneralTraceEvents": "false",
"Description": "",
"ActorPoolSize": "2",
"Item": [
{
"@Name": "Python.FileOperation",
"@Category": "",
"@ClassName": "Python.FileOperation",
"@PoolSize": "1",
"@Enabled": "true",
"@Foreground": "false",
"@Comment": "",
"@LogTraceEvents": "true",
"@Schedule": "",
"Setting": [
{
"@Target": "Adapter",
"@Name": "Charset",
"#text": "utf-8"
},
{
"@Target": "Adapter",
"@Name": "FilePath",
"#text": "/irisdev/app/output/"
},
{
"@Target": "Host",
"@Name": "%settings",
"#text": "path=/irisdev/app/output/"
}
]
}
]
}
}
8.10. status
O comando status dá o status de uma produção.
O comando status não aceita argumentos, porque só pode ser executada uma produção.
iop -x
saída:
{
"Production": "PEX.Production",
"Status": "stopped"
}
O status pode ser:
- stopped (interrompido)
- running (em execução)
- suspended (suspenso)
- troubled (com problema)
8.11. version
O comando version exibe a versão.
iop -v
saída:
2.3.0
8.12. log
O comando log exibe o log.
Para sair do comando, pressione CTRL+C.
iop -L
saída:
2021-08-30 15:13:51.000 [PEX.Production] INFO: Starting production
2021-08-30 15:13:51.000 [PEX.Production] INFO: Starting item Python.FileOperation
2021-08-30 15:13:51.000 [PEX.Production] INFO: Starting item Python.EmailOperation
...
9. Créditos
A maior parte do código foi retirada do PEX para Python, de Mo Cheng e Summer Gerry.
Funciona somente a partir do IRIS 2021.2
 .
.









































.png)

.png)
.png)
.png)
.png)