Power BI
Conectando a uma origem de dados
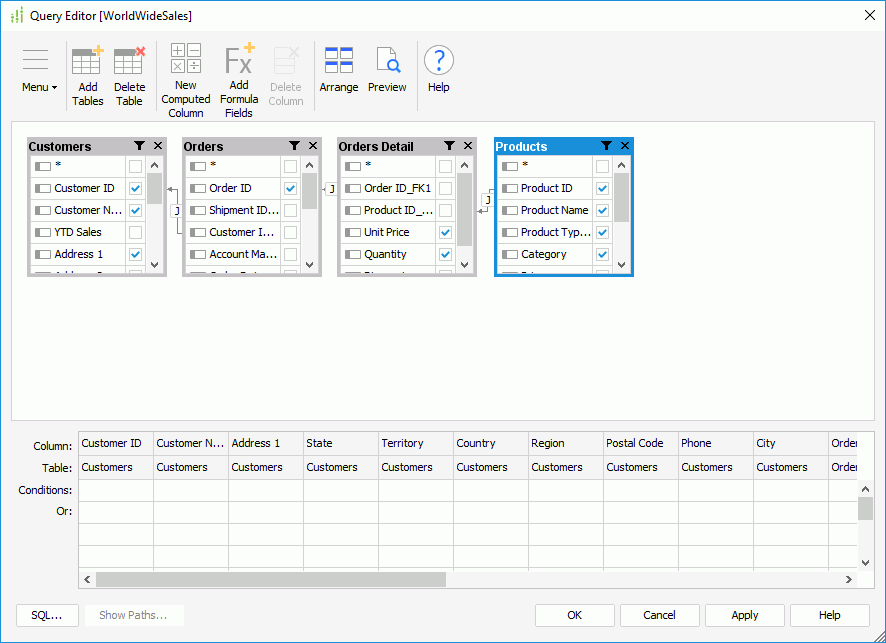
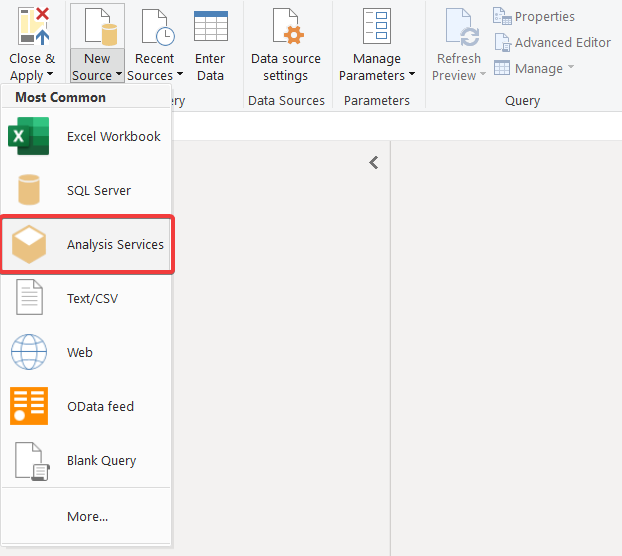
Para conectar a AtScale, vamos usar o banco de dados do SQL Server Analysis Services. Vamos abri-lo no editor do Power Query. Para fazer isso, selecione Transform Data (Transformar dados) em Home.

Na janela exibida, acesse Home, abra New Source (Nova origem) e selecione Analysis Services.
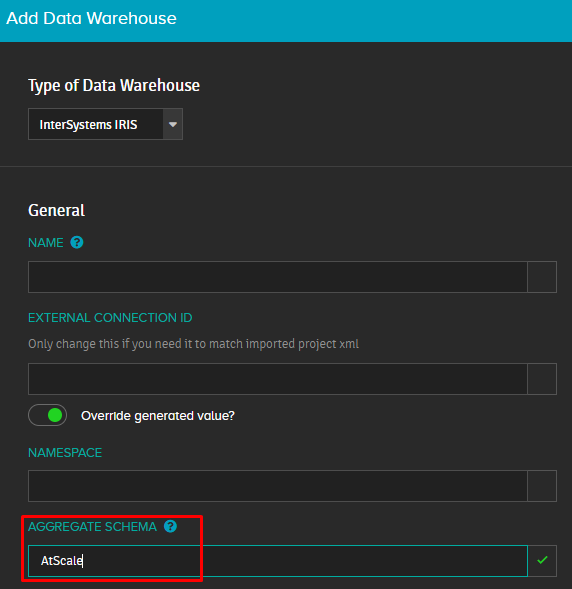
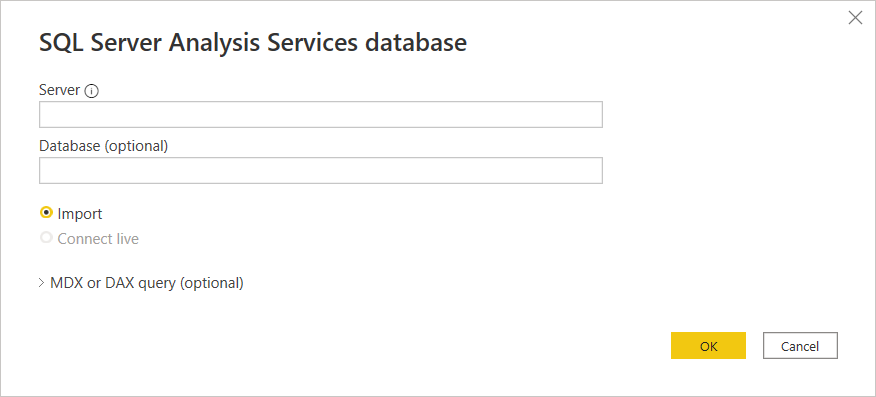
Na linha do Server, você precisa especificar o link MADX para o projeto publicado na AtScale. Você também pode indicar imediatamente o nome do projeto na linha do banco de dados se quiser.

Em seguida, selecione o tipo de autorização Basic e especifique o login/senha da AtScale.

Em Navigator, você precisa especificar as medidas e dimensões necessárias (se não houver conexão entre os campos, você não conseguirá criar uma consulta correta). Também é recomendável dividir o cubo em várias tabelas, dependendo da tarefa. Isso ajudará você a melhorar o desempenho e evitar erros.
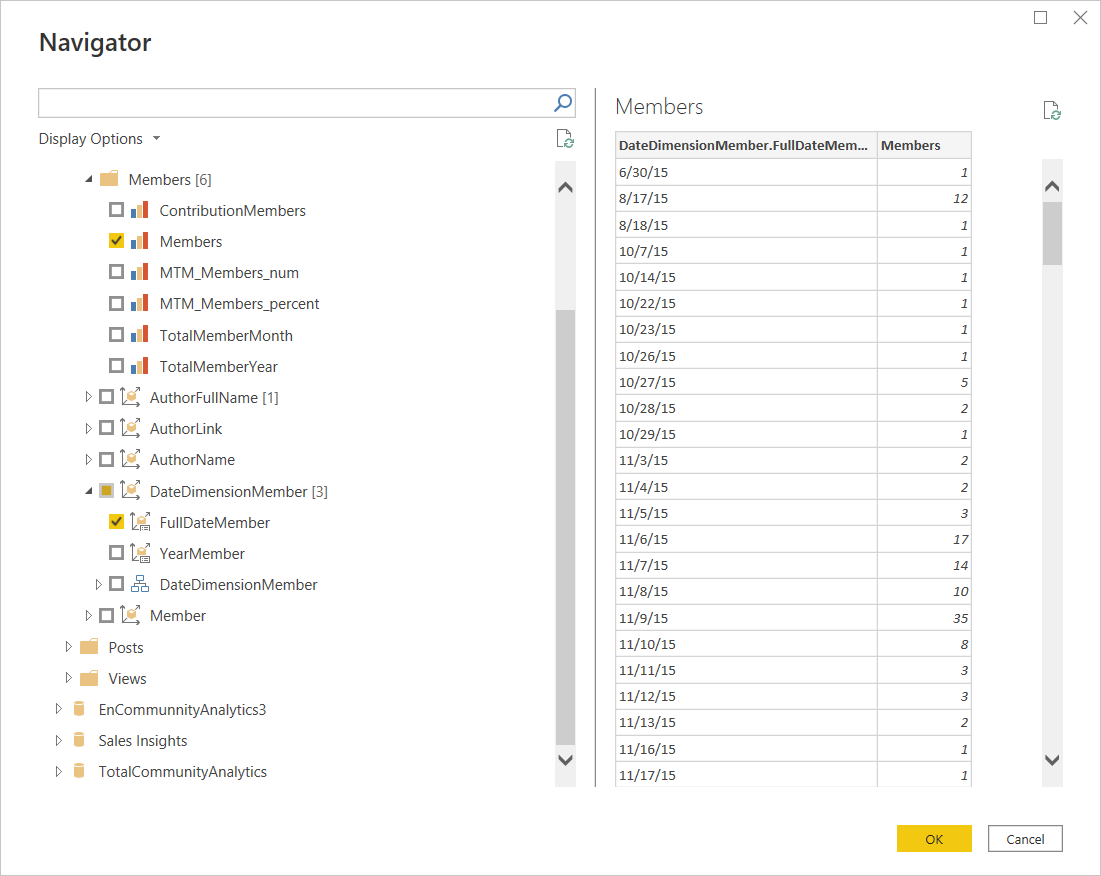
Para configurar atualizações automáticas, você precisa usar o Gateway do Power BI e a autorização do Windows. Neste artigo, vamos pular essas etapas.
No entanto, você pode ler mais sobre esse assunto na documentação da AtScale.
Recursos da criação de consultas no Power Query.
Depois de adicionar as colunas, você pode fazer alterações na tabela (modificar o nome da coluna, o tipo de dados, adicionar/alterar colunas, substituir valores etc.).
Por exemplo, você pode alterar o nome de uma coluna. Para fazer isso, clique duas vezes no nome da coluna. É recomendável verificar se não há campos em branco nos valores numéricos. Todos os valores em branco precisam ser marcados como null. Se você tiver campos vazios, basta sobrepor o tipo de campo. Para isso, clique no ícone de tipo à esquerda do nome da coluna e escolha o tipo necessário.
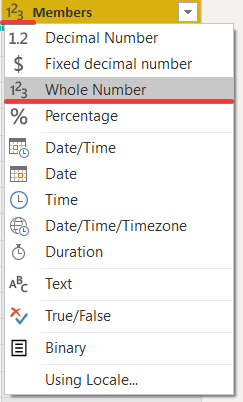
O Power Query pode não identificar corretamente o tipo de dados. Neste exemplo, ele reconheceu incorretamente o formato de dados.
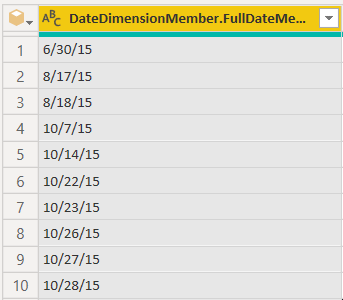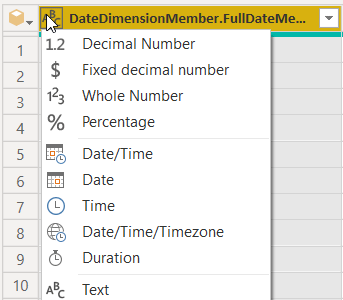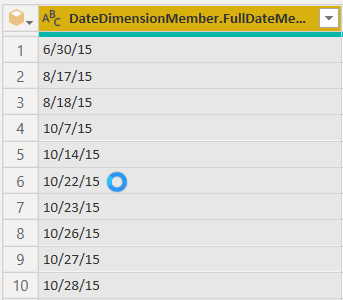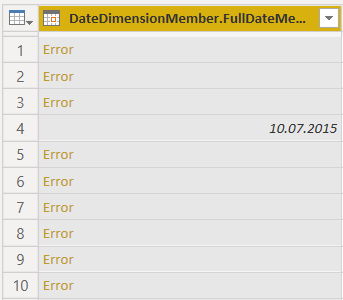
Para corrigir isso, apontamos um formato de dados específico. Para fazer isso, clique no íconede tipo de dados, Use Locale…

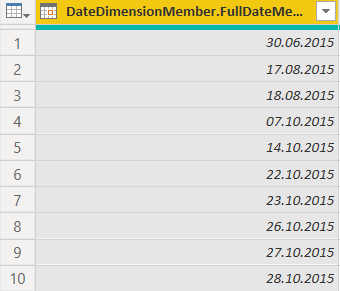
Em nosso caso, vamos escolher Date e a localidade English (United States).

Agora os dados são exibidos corretamente.
Você pode saber mais sobre como trabalhar no Power Query na documentação oficial.
Trabalhando no Power BI e criando visualizações.
Criando uma tabela de dados usando funções DAX.
Para que nossas tabelas sejam relatadas por data, vamos criar um calendário com base nas datas disponíveis usando a linguagem DAX integrada.
Uma forma de criar uma tabela de dados é usando a função DAX integrada recomendada, já que pode haver datas adicionais de início e término, como aniversários de funcionários, então é melhor configurá-las manualmente no CALENDAR. Essas funções retornam todos os dias entre as datas mínima e máxima.
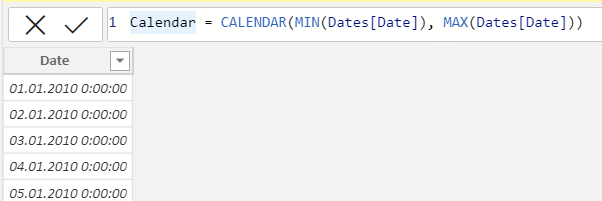
Calendar = CALENDAR(<start_date>, <end_date>))
Agora vamos adicionar uma coluna com o ano e o nome do mês desejado. Você pode usar uma hierarquia de datas para obter o ano e o nome do mês. Em Column Tools, clique no botão New Column e escreva a fórmula.
Month = 'Calendar'[Date].[Year]

Em DAX, a fórmula é precedida pelo nome da coluna. O = indica o início de uma fórmula. Em seguida, a própria fórmula é escrita. Em nosso caso, simplesmente tiramos o [Year] da data do calendário. É sempre recomendável escrever o nome da tabela, mas você pode só escrever [Date].[Year]. O Power BI consultará a coluna Date existente dentro da tabela.
Vamos adicionar uma coluna no formato (MMM-AAAA). Para fazer isso, vamos escrever a função FORMAT .
Month-Year = FORMAT('Calendar'[Date], "MMM-YYYY").
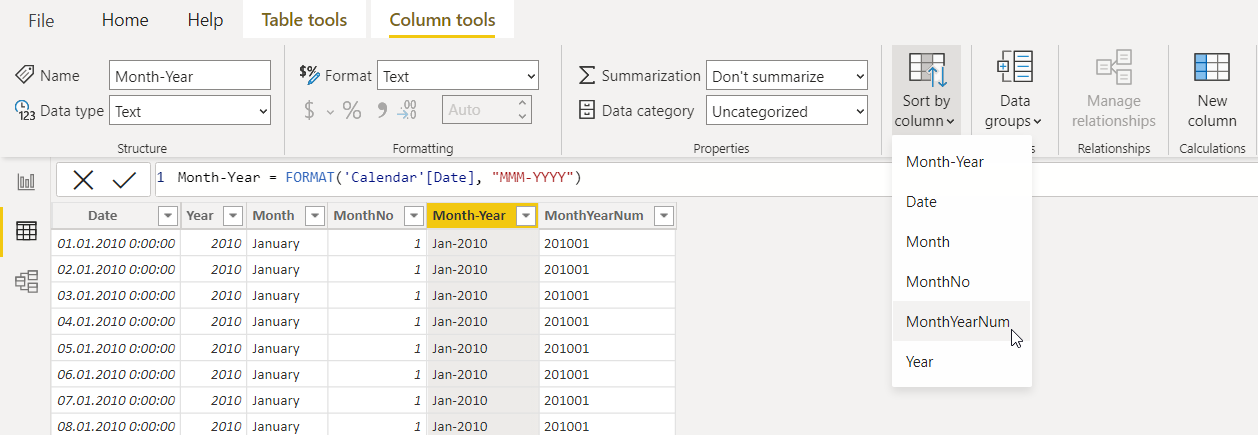
No entanto, como Month e Month-Year são campos de texto, eles serão colocados em ordem alfabética. Vamos criar colunas para a classificação correta: MonthNum com o valor numérico do mês para a coluna Month, e MonthYearNum para a coluna Month-Year.
MonthYearNum = FORMAT('Calendar'[Date], "YYYYMM")
Agora precisamos definir a coluna de ordenação. Acesse Column Tools selecione Sort by e selecione a coluna necessária. Vamos realizar a mesma manipulação para o resto das colunas com texto.
Para entender melhor as fórmulas DAX, você pode fazer aulas no site oficial da Microsoft.
Gerenciando dados
A visualização Model no Power BI Desktop permite que você defina a relação entre as tabelas ou os itens visualmente. Nesse caso, duas ou mais tabelas serão vinculadas, porque elas contêm dados relacionados. Assim, os usuários podem acessar dados relacionados em vários tablets. Na visualização Model, você pode ver uma representação esquemática dos dados.
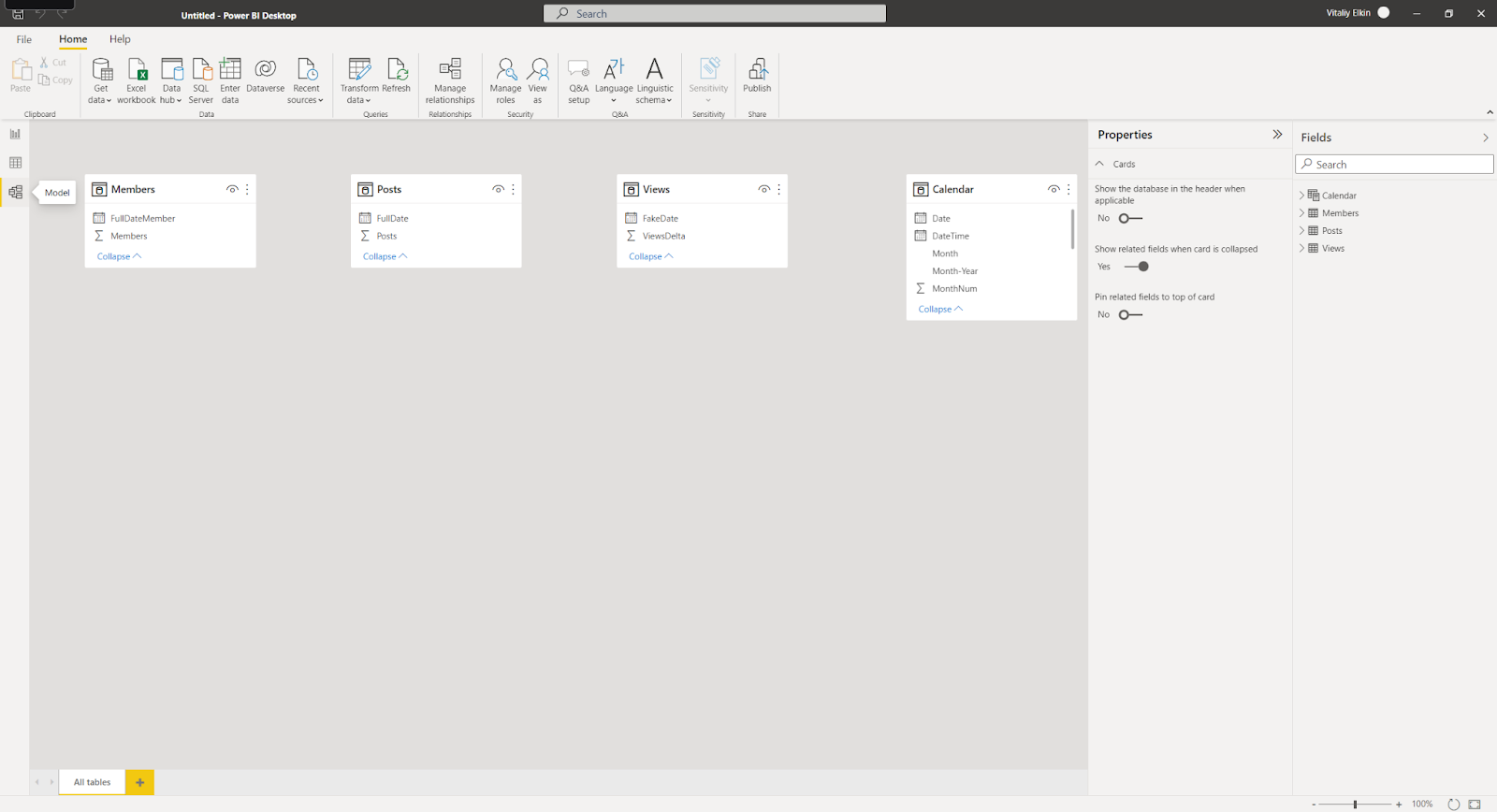
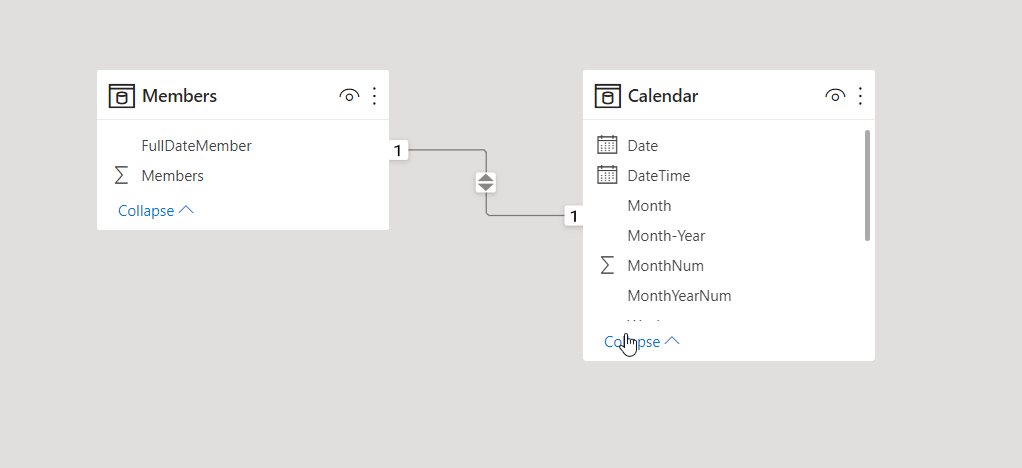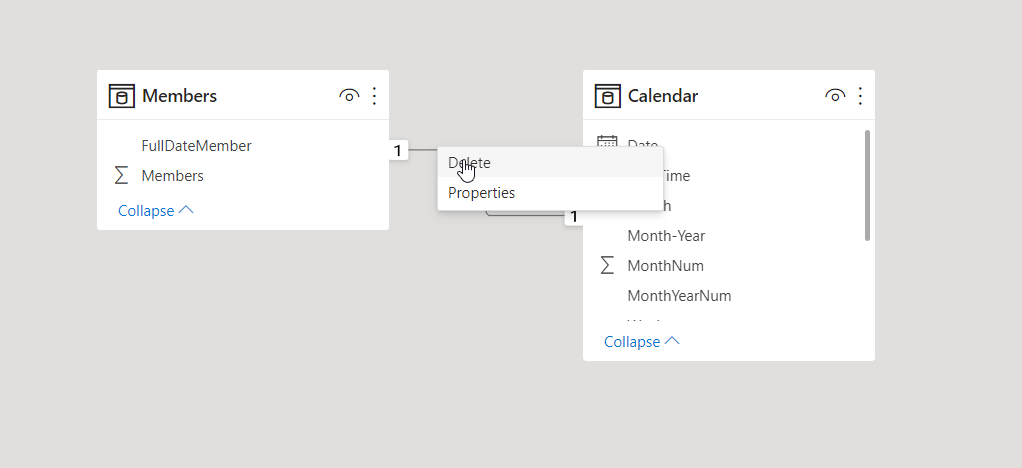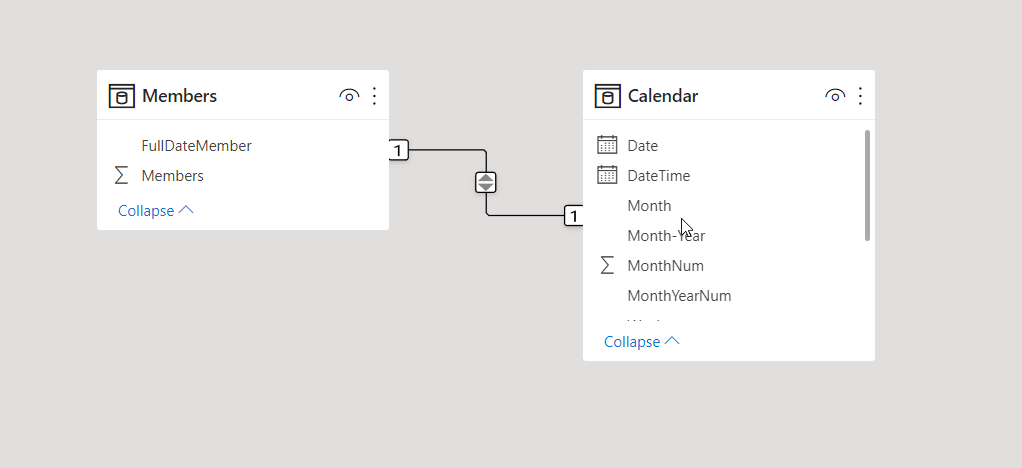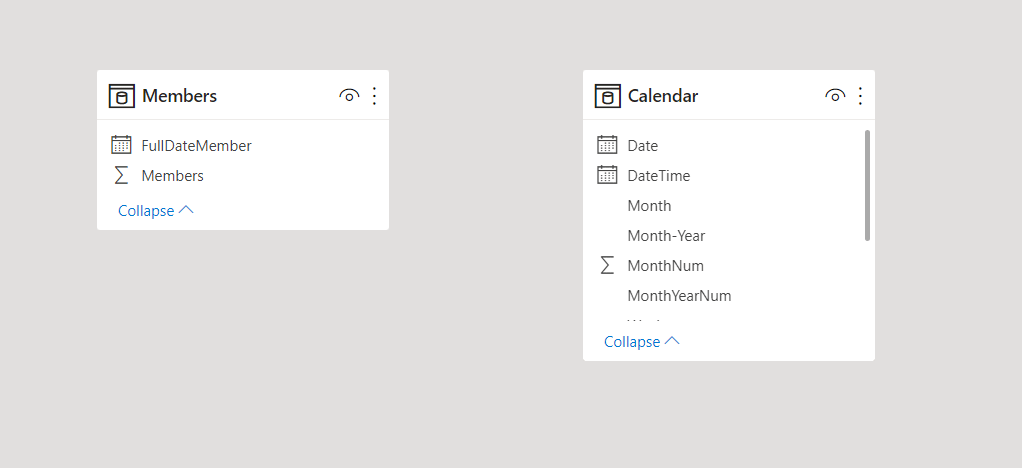
É muito fácil adicionar e remover associações. Para criar uma associação, arraste os campos que você quer associar entre as tabelas. Para remover uma associação, clique com o botão direito e selecione Delete.
Para entender as associações de dados em mais detalhes, em Home, acesse Manage relationships (Gerenciar relações). A caixa de diálogo Manage mostra as associações como uma lista, em vez de um diagrama visual. Nessa caixa de diálogo, você pode selecionar Autodiscover (Descoberta automática) para encontrar relações entre dados novos ou atualizados. Selecione Edit para modificar as associações manualmente. A seção de edição contém parâmetros adicionais que permitem definir a multiplicidade e direção da filtragem cruzada para associações.

Suas opções de cardinalidade são explicadas na tabela a seguir.
Geralmente, recomendamos reduzir o uso de relações bidirecionais. Elas podem ter um impacto negativo no desempenho de consultas do modelo e, possivelmente, oferecer experiências confusas para os usuários dos relatórios.
A definição de relações precisas entre seus dados permite que você crie cálculos complexos em vários elementos de dados.
Veja mais informações sobre modelos de dados aqui.
Slicers
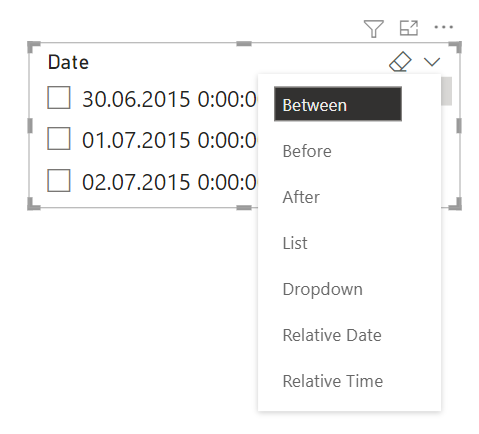
Um filtro simples que pode ser usado diretamente na página de um relatório é chamado de slicer. Os slicers oferecem dicas de como você pode filtrar os resultados em elementos visuais na página de um relatório. Há diferentes tipos de slicers: numéricos, por categoria e por data. Os slicers ajudam você a filtrar facilmente todos os elementos visuais em uma página de uma só vez.

Esse GIF mostra o trabalho de uma segmentação padrão. Você pode configurar várias seleções para selecionar várias opções sem Ctrl.
Para fazer isso, selecione slicer. Em seguida, no painel Visualizations, escolha a guia Format visual . Abra Selection, e ative a Seleção múltipla com Ctrl.

Você também pode mudar a aparência do slicer. Para isso, selecione a seta para baixo no canto superior direito do elemento do slicer.
Adicionando um elemento visual à página
Para adicionar um elemento visual, selecione-o em Visualizations.
Vamos adicionar um gráfico de colunas empilhadas.
Agora, precisamos selecionar os campos que queremos exibir. Vamos adicionar o campo Month-Year de Calendar e outro valor numérico da sua tabela.
Este deve ser o resultado.
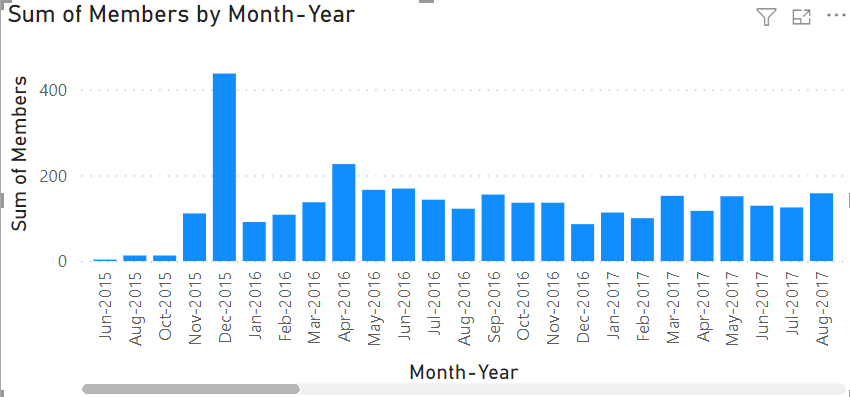
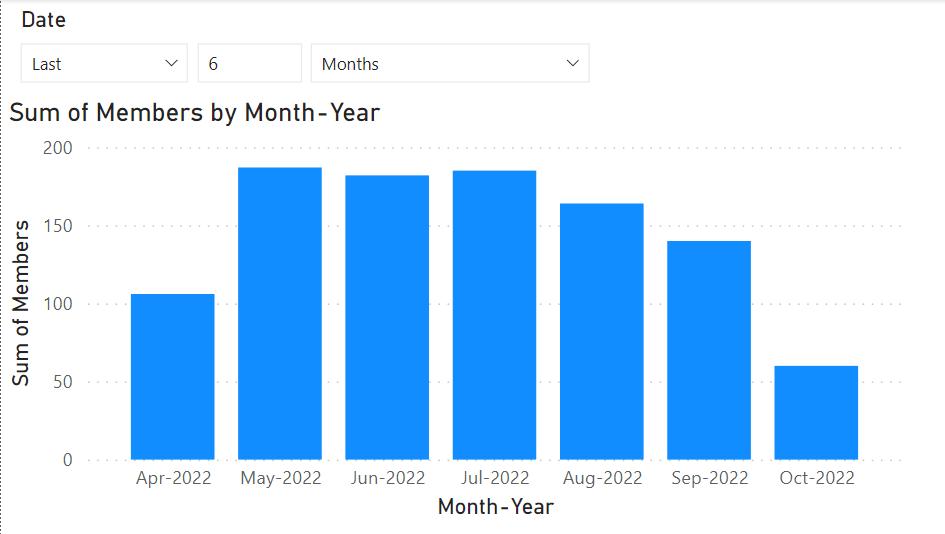
Para truncar os dados, vamos adicionar um filtro por data. Vamos extrair o campo Date de Calendar e mudar o tipo de visualização para slicer. Em seguida, vamos remover a hierarquia padrão e usar o formato de dados comum. Depois, devemos mudar imediatamente o tipo de visualização para uma data relativa.

Agora, podemos aplicar um filtro para exibir os últimos 6 meses.
Você pode mudar a visualização na guia de formatação. Cada elemento visual tem parâmetros especiais. Leia mais sobre isso aqui.

Também há uma guia com opções gerais, como título e plano de fundo.

Vamos adicionar mais algumas visualizações e mudar o visual delas um pouco.
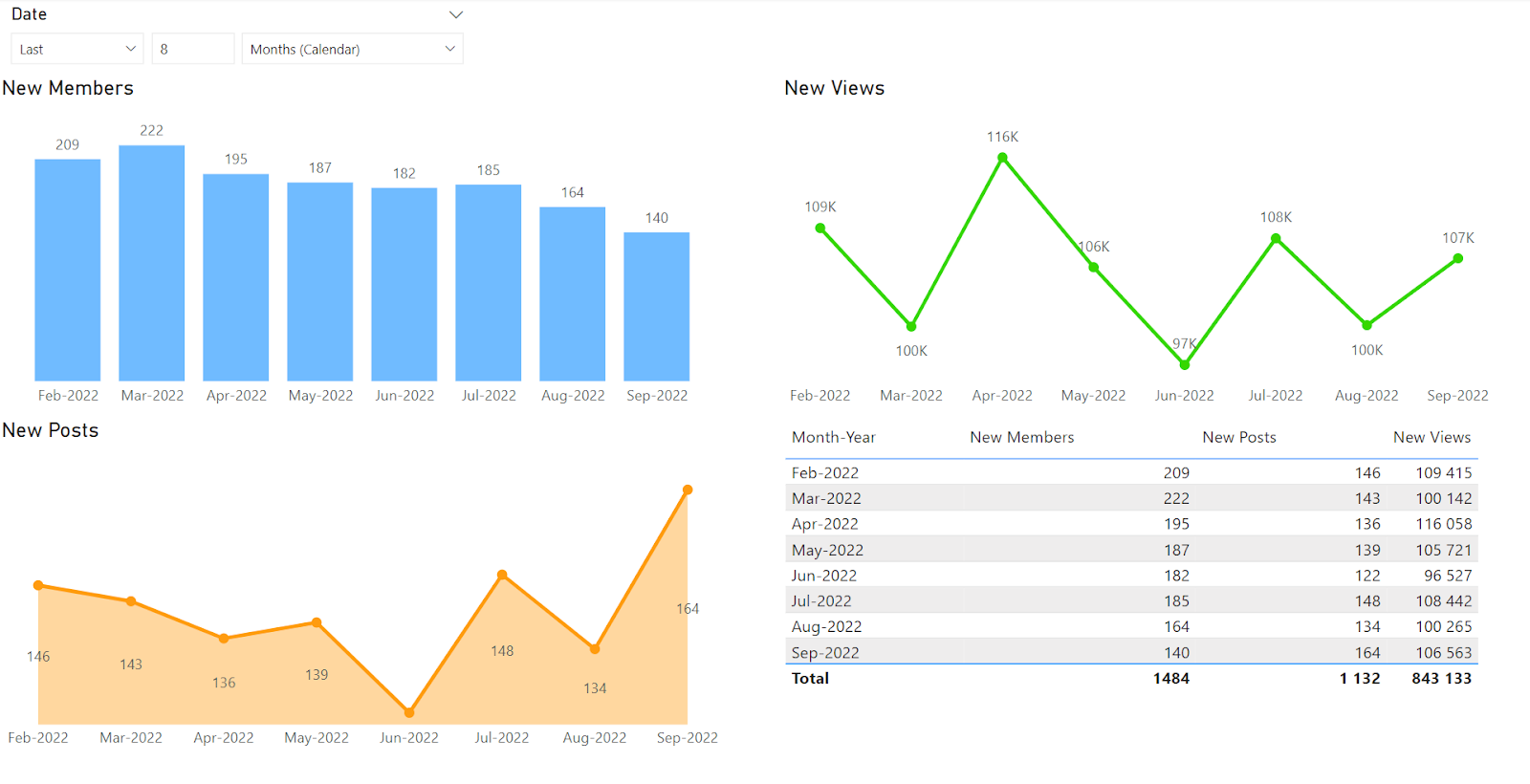
Agora, temos um exemplo de painel de controle simples.
Publicando um relatório em app.powerbi.com
Os relatórios são sempre publicados no portal https://app.powerbi.com/home.
Portanto, você precisa ter uma conta e estar autorizado no Power BI Desktop.
Para publicar, você precisa selecionar Publish e, se necessário, selecionar um espaço de trabalho.

Depois de publicar, visite o portal e encontre nosso relatório.
Um relatório desse tipo pode ser ajustado, mas está sujeito a restrições. Elas são principalmente relacionadas ao fato de que você não pode adicionar novas colunas ou medidas. No entanto, isso não impede você de adicionar visualizações com base nas colunas existentes.
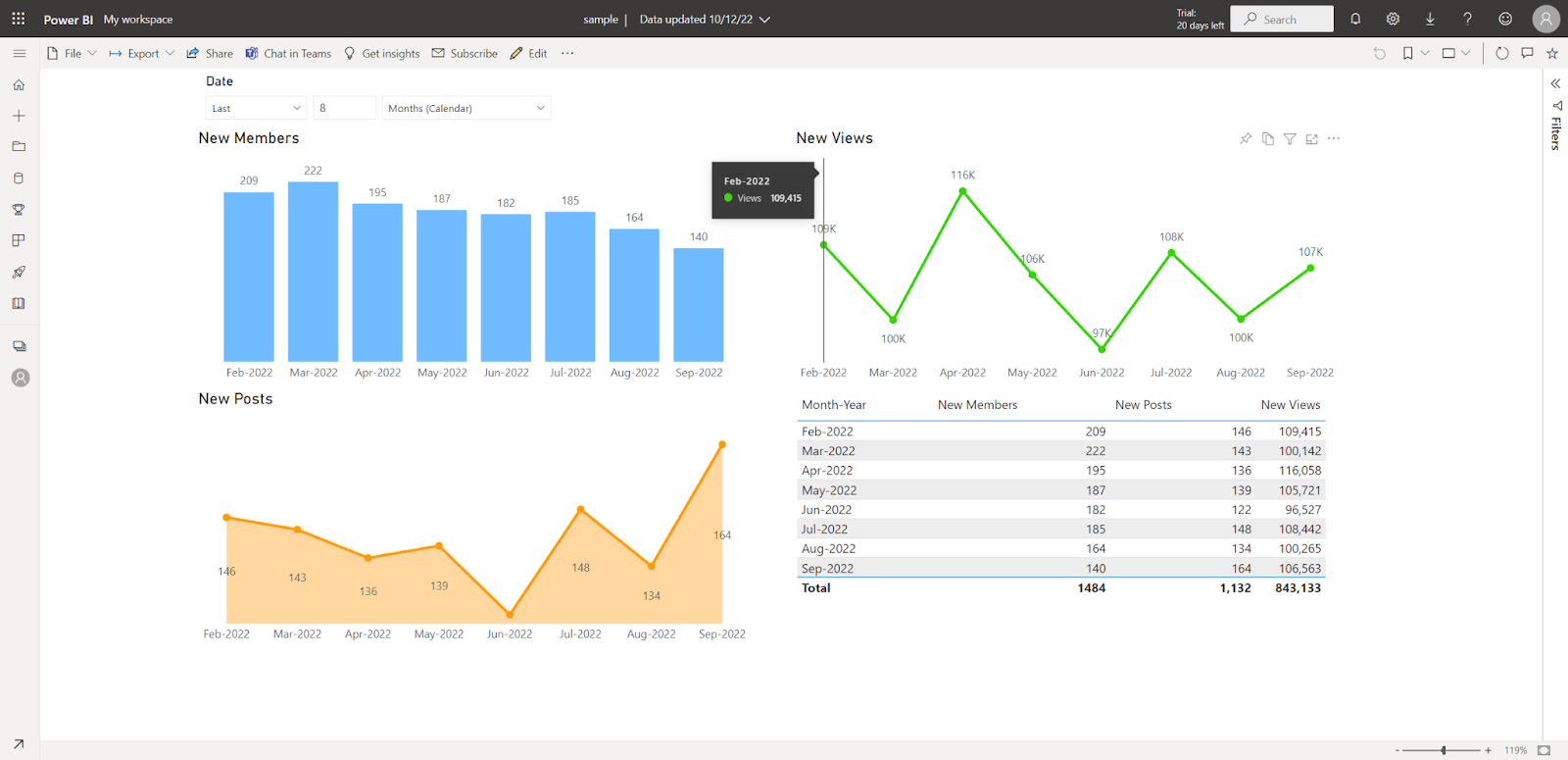
Esse relatório só está disponível para usuários do Power BI a que você deu acesso. Para compartilhar seu relatório com outras pessoas, você pode publicá-lo na Web ao selecionar Publish it to web (public).
Atualização de dados
Como não configuramos o Gateway do Power BI, a atualização automática não está ativada. Você só pode atualizar os dados manualmente. Para fazer isso, você precisa abrir o relatório, clicar no botão Refresh e publicá-lo novamente.

Tableau
Preparação preliminar.
Você precisará de um driver para a conexão. Usamos Cloudera Hive. É possível baixar no site oficial (é necessário se inscrever). Você precisa conhecer o SO e a profundidade de bit para escolher a versão mais adequada para download. A instalação é simples (não exige explicação).
Conexão a cubos.
Para conectar um cubo a um relatório do Tableau, faça o download do arquivo de conexão. Para isso, selecione o projeto publicado desejado na página do projeto, acesse a guia de conexão e selecione a opção Tableau.
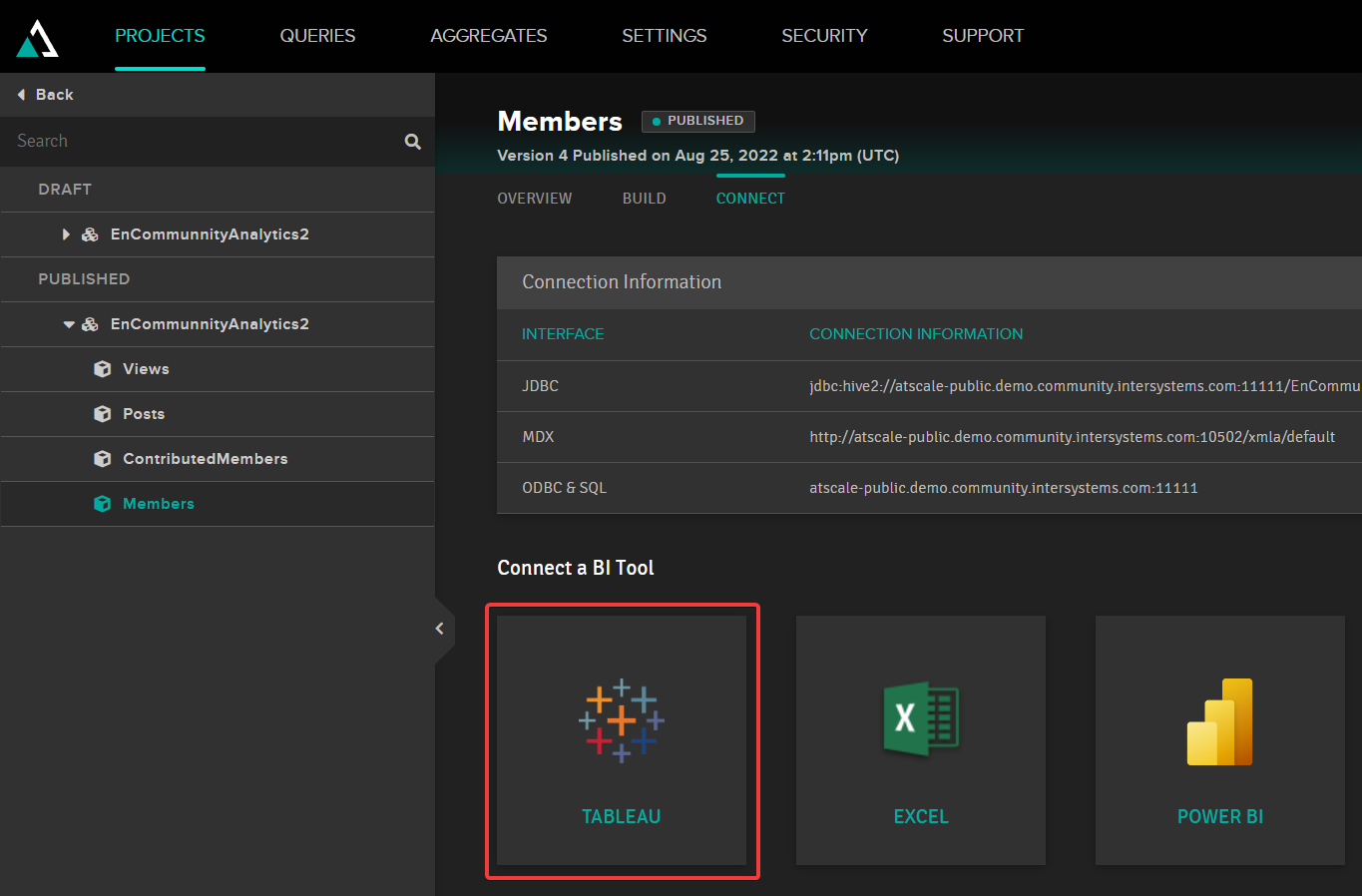
Na janela exibida, selecione DOWNLOAD TDS

Ao iniciar o Tableau, no menu à esquerda, selecione Connect, To a File e More… na lista e abra o arquivo .tds baixado anteriormente.
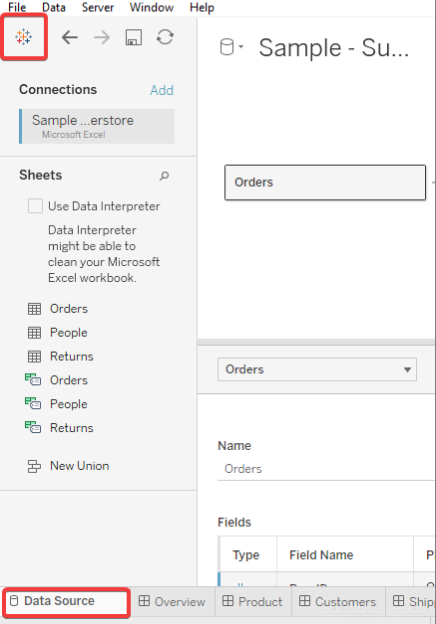
O Tableau pedirá para você inserir seu nome de usuário e senha da AtScale. Após a autorização, seu cubo aparecerá nas origens de dados, permitindo que você comece a trabalhar.
Criando visualizações.
Ao contrário do Power BI, cada visual é criado em uma página separada. However, you can later group them on the worksheet. O Tableau tem linhas e colunas, mas a interface depende de onde as dimensões e medidas estão localizadas.


Para selecionar o tipo de visualização, você precisa clicar em "Show Me" (Me mostre) no canto superior direito da tela (quando você modifica o tipo de visualização, a localização dos valores selecionados pode mudar).

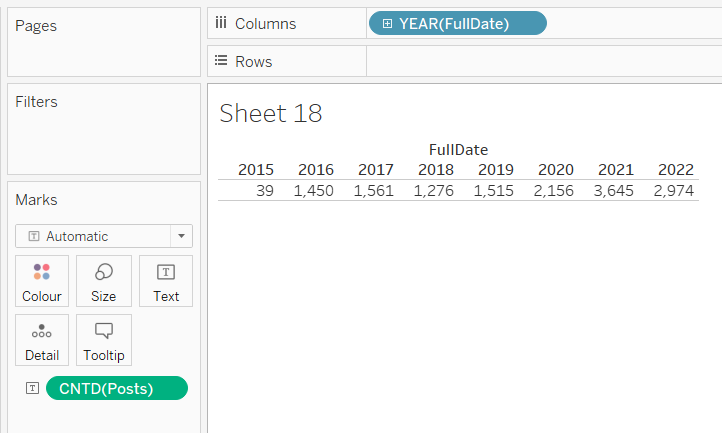
O campo para filtrar dados por padrão está localizado no cartão à esquerda.
Os valores podem ser filtrados manualmente, por curinga, condição ou top (bottom). Você também pode combinar esses tipos de filtros.
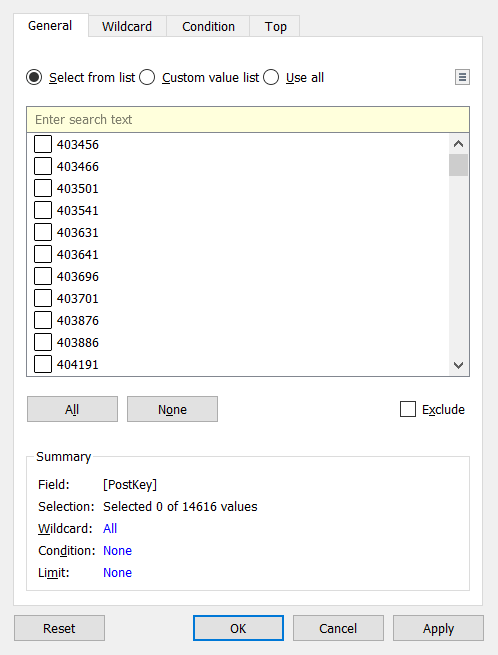
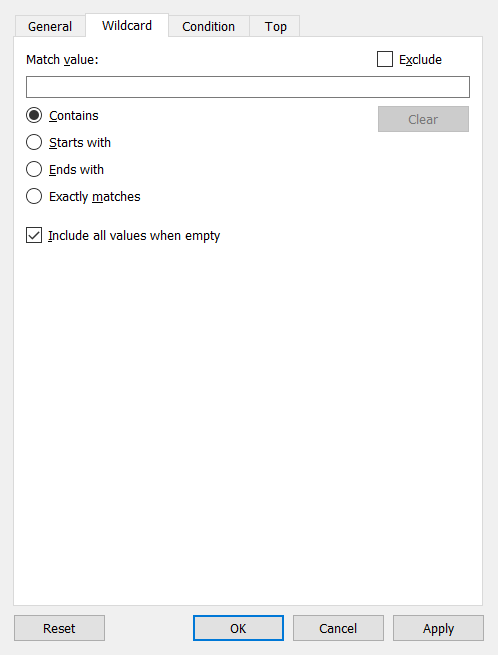
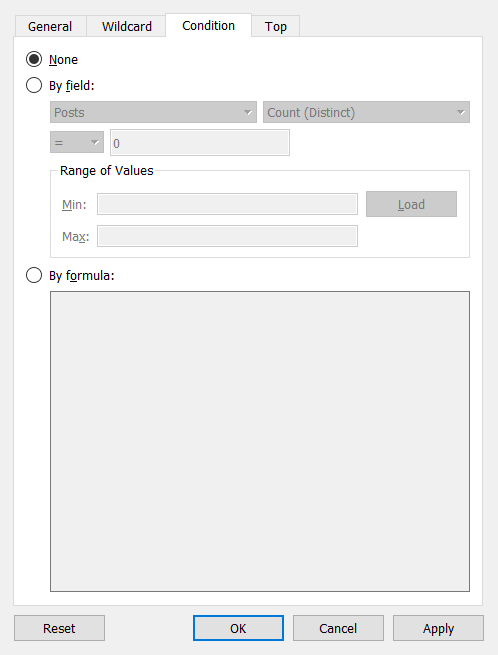
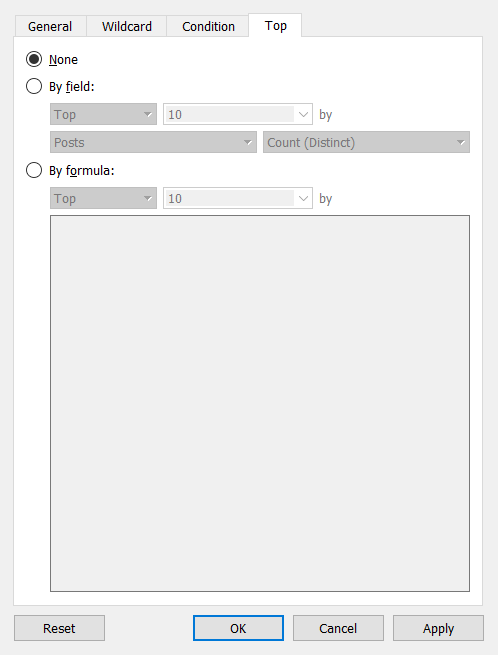
É possível alterar o formato de visualização em Marks.

Uma planilha é usada para o agrupamento. À esquerda, há uma lista com todas as planilhas disponíveis que podem ser arrastadas e agrupadas como você quiser. Além disso, em Worksheets no card Objects, você pode selecionar e adicionar texto, imagens etc.
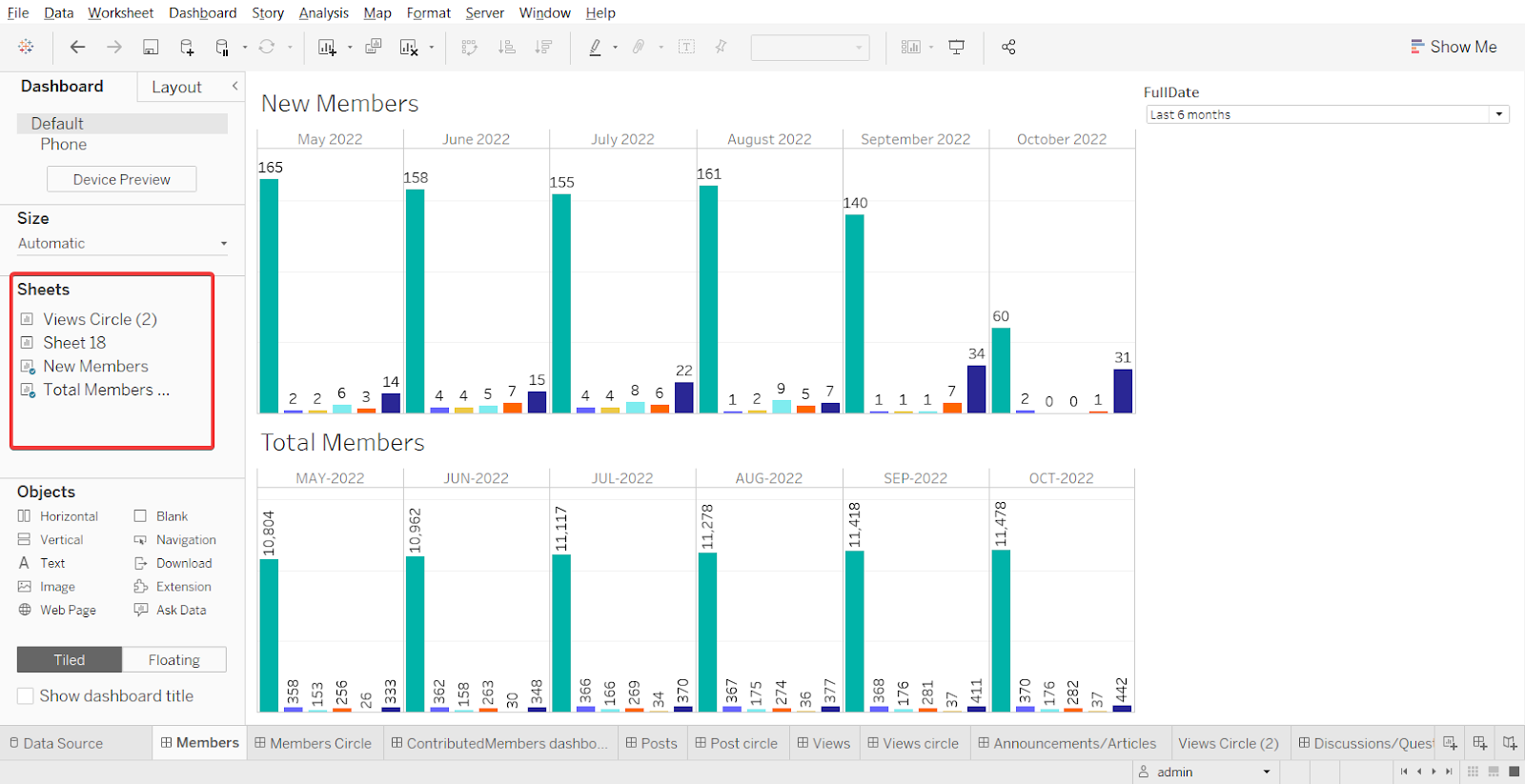
Publicando no servidor.
No Tableau, você pode publicar seus relatórios no Tableau Public, Tableau Online e Tableau Server. A funcionalidade dos dois últimos programas é idêntica. A única diferença é que o Tableau Online é mantido pelo próprio Tableau, enquanto o Tableau Server será mantido no lado da sua organização. Você pode publicar seus relatórios nele com uma conexão em tempo real, modificar relatórios publicados sem limitar a funcionalidade ou editar um relatório publicado no Tableau Desktop. A única desvantagem dos servidores é a impossibilidade de compartilhar seus relatórios com alguém que não está registrado no servidor. Em outras palavras, esses relatórios se destinam ao uso exclusivo na organização.O Tableau Public permite que você compartilhe seus relatórios com quem tem um link, mas não deixa você usar uma conexão de dados direta.
Vamos conectar ao Tableau Server.
Primeiro, precisamos fazer login.
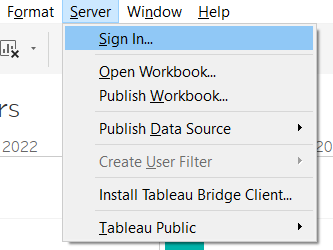
Selecione o servidor desejado e passe pela autorização. Em seguida, selecione Publish Workbook (Publicar pasta de trabalho).
Especifique os parâmetros necessários.Para uma visualização conveniente, recomendamos selecionarShow sheets as tabs (Mostrar planilhas como guias).

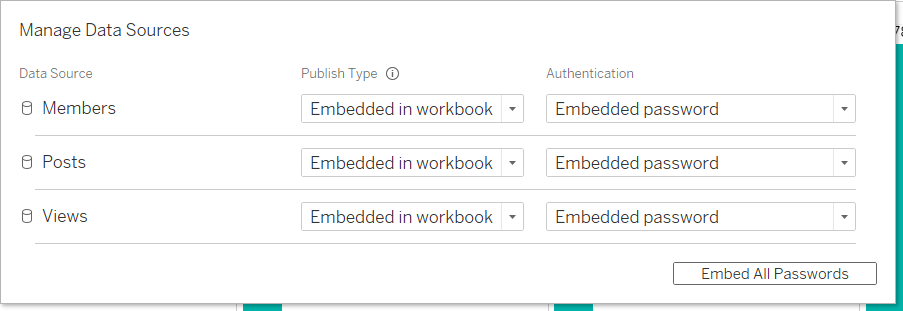
Se você quiser, é possível incorporar senhas. Caso contrário, você terá que especificar o login e a senha para nossa origem de dados sempre que entrar na sua conta. Você pode incorporar todas as senhas ao mesmo tempo clicando em Embed All Passwords.
Por fim, é hora de acessar o servidor, selecionar o item Explore e encontrar nossa pasta.