Talvez isso já seja bem conhecido, mas quis compartilhar para ajudar.
Considere que você tem as seguintes definições de classes persistentes:
Uma classe Invoice (Fatura) com uma propriedade de referência para Provider (Prestador de serviço):
Esta tag está relacionada às discussões sobre o desenvolvimento de soluções de análise e inteligência de negócios, visualização, KPI e gerenciamento de outras métricas de negócios.
Talvez isso já seja bem conhecido, mas quis compartilhar para ajudar.
Considere que você tem as seguintes definições de classes persistentes:
Uma classe Invoice (Fatura) com uma propriedade de referência para Provider (Prestador de serviço):
A InterSystems está na vanguarda da tecnologia de bancos de dados desde sua criação, sendo pioneira em inovações que consistentemente superam concorrentes como Oracle, IBM e Microsoft. Ao se concentrar em um design de kernel eficiente e adotar uma abordagem intransigente em relação ao desempenho de dados, a InterSystems criou um nicho em aplicações de missão crítica, garantindo confiabilidade, velocidade e escalabilidade.
A História de Excelência Técnica
Estou animado em compartilhar que a equipe de Learning Services adicionou recentemente novo conteúdo ao nosso InterSystems Reports Learning Path. Esses vídeos mais recentes, criados por nosso parceiro, insightsoftware, fornecem instruções para desenvolver relatórios com o InterSystems Report Designer.
Nesses três vídeos curtos, você aprenderá como:
 | Como incluir dados do IRIS no seu Data Warehouse do Google Big Query e em suas explorações de dados do Data Studio. Neste artigo, vamos usar o Google Cloud Dataflow para nos conectarmos com o InterSystems Cloud SQL Service e criar um job para persistir os resultados de uma consulta do IRIS no Big Query em um intervalo. Se você teve a sorte de ganhar acesso ao Cloud SQL no Global Summit 2022, conforme mencionado em "InterSystems IRIS: What's New, What's Next", o exemplo será muito fácil. No entanto, também é possível fazer isso com qualquer listener acessível publicamente ou por VPC que você provisionar. |


jdbc:IRIS://k8s-c5ce7068-a4244044-265532e16d-2be47d3d6962f6cc.elb.us-east-1.amazonaws.com:1972/USERSQLAdmin/Testing12!com.intersystems.jdbc.IRISDrivergcloud projects create iris-2-datastudio --set-as-default
gcloud services enable bigquery.googleapis.com gcloud services enable dataflow.googleapis.com gcloud services enable storage.googleapis.com
gsutil mb gs://iris-2-datastudio
wget https://github.com/intersystems-community/iris-driver-distribution/raw/main/intersystems-jdbc-3.3.0.jar gsutil cp intersystems-jdbc-3.3.0.jar gs://iris-2-datastudio
bq --location=us mk \ --dataset \ --description "sqlaas to big query" \ iris-2-datastudio:irisdata
Aqui, uma vantagem superpoderosa se torna meio incômoda para nós. O Big Query pode criar tabelas dinamicamente se você fornecer um esquema com sua carga útil. Isso é ótimo dentro de pipelines e soluções, mas, em nosso caso, precisamos estabelecer a tabela com antecedência. O processo é simples, já que você pode exportar um CSV do banco de dados do IRIS facilmente com algo como o DBeaver, depois invocar a caixa de diálogo "criar tabela" abaixo do conjunto de dados criado e usar o CSV para criar sua tabela. Verifique se "gerar esquema automaticamente" está marcado na parte inferior da caixa de diálogo. Isso conclui a configuração do Google Cloud Platform, e deve estar tudo pronto para configurar e executar o job do Dataflow.
Isso conclui a configuração do Google Cloud Platform, e deve estar tudo pronto para configurar e executar o job do Dataflow.
Job do Google Dataflow
Se você seguiu as etapas acima, deverá ter o seguinte no seu inventário para executar o job de ler os dados do InterSystems IRIS e ingeri-los no Google Big Query usando o Google Dataflow.
No Console do Google Cloud, acesse o Dataflow e selecione "Criar job a partir do modelo"
Essa é uma ilustração um tanto desnecessária/exaustiva sobre como preencher um formulário com os pré-requisitos gerados, mas indica a origem dos componentes...
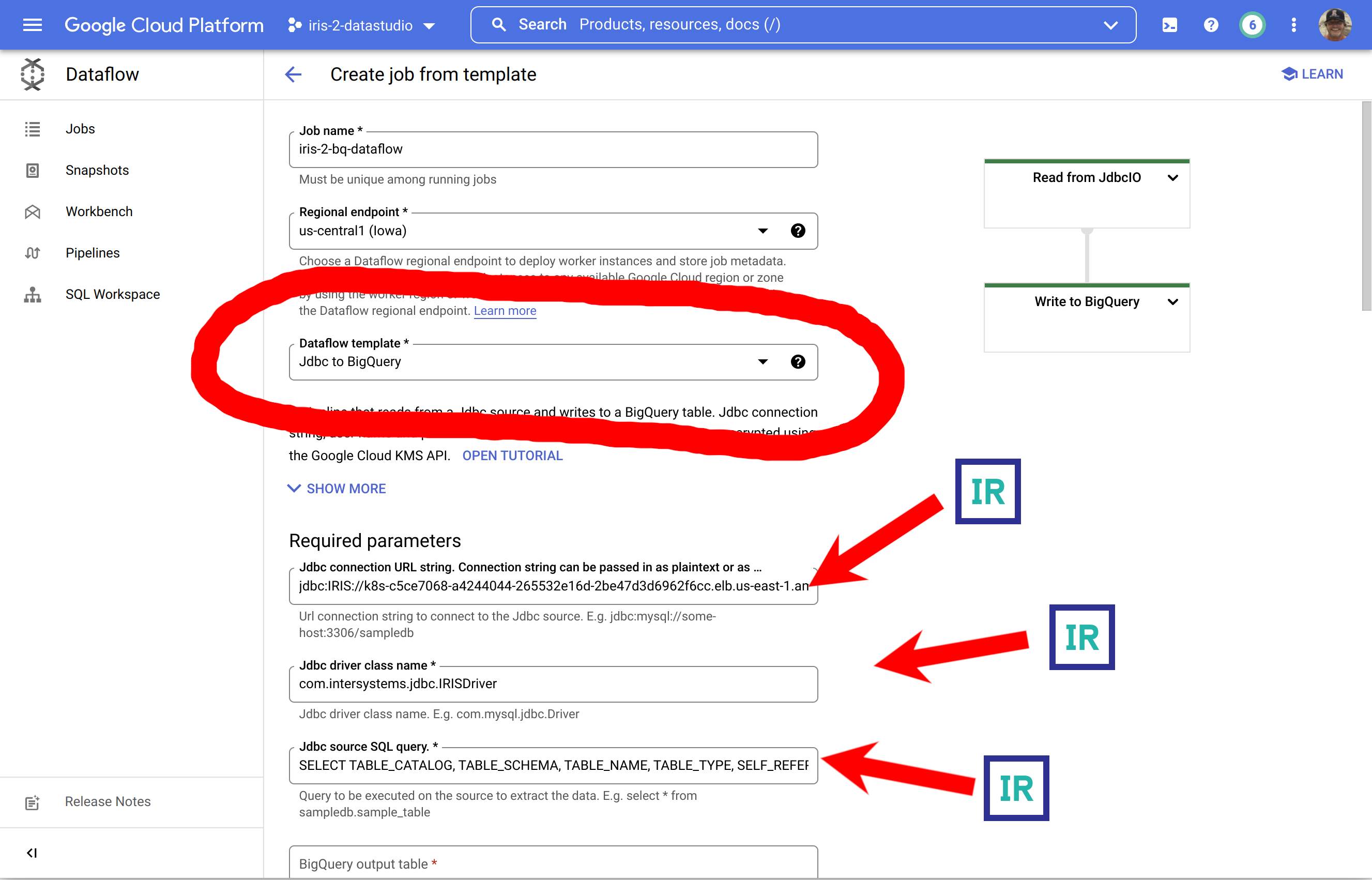
... para completar, abra a seção inferior e forneça suas credenciais do IRIS.
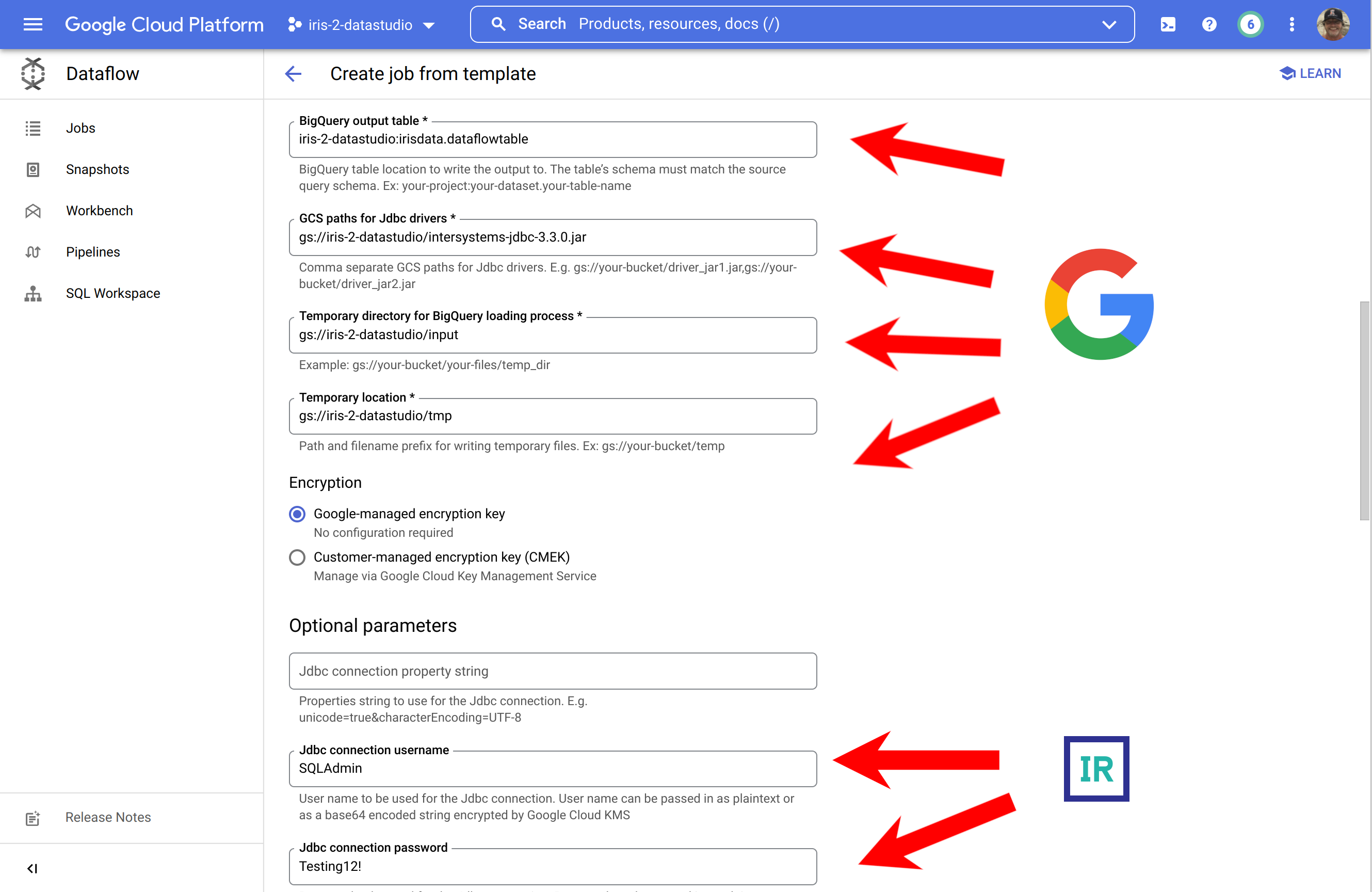
Para quem achou essas capturas de tela ofensivas à própria inteligência, aqui está o caminho alternativo para deixar você dentro da sua zona de conforto na CLI para executar o job:
gcloud dataflow jobs run iris-2-bq-dataflow \ --gcs-location gs://dataflow-templates-us-central1/latest/Jdbc_to_BigQuery \ --region us-central1 --num-workers 2 \ --staging-location gs://iris-2-datastudio/tmp \ --parameters connectionURL=jdbc:IRIS://k8s-c5ce7068-a4244044-265532e16d-2be47d3d6962f6cc.elb.us-east-1.amazonaws.com:1972/USER,driverClassName=com.intersystems.jdbc.IRISDriver,query=SELECT TABLE_CATALOG, TABLE_SCHEMA, TABLE_NAME, TABLE_TYPE, SELF_REFERENCING_COLUMN_NAME, REFERENCE_GENERATION, USER_DEFINED_TYPE_CATALOG, USER_DEFINED_TYPE_SCHEMA, USER_DEFINED_TYPE_NAME, IS_INSERTABLE_INTO, IS_TYPED, CLASSNAME, DESCRIPTION, OWNER, IS_SHARDED FROM INFORMATION_SCHEMA.TABLES;,outputTable=iris-2-datastudio:irisdata.dataflowtable,driverJars=gs://iris-2-datastudio/intersystems-jdbc-3.3.0.jar,bigQueryLoadingTemporaryDirectory=gs://iris-2-datastudio/input,username=SQLAdmin,password=Testing12!
Após iniciar o job, aproveite a glória de uma execução de job bem-sucedida:

Resultados
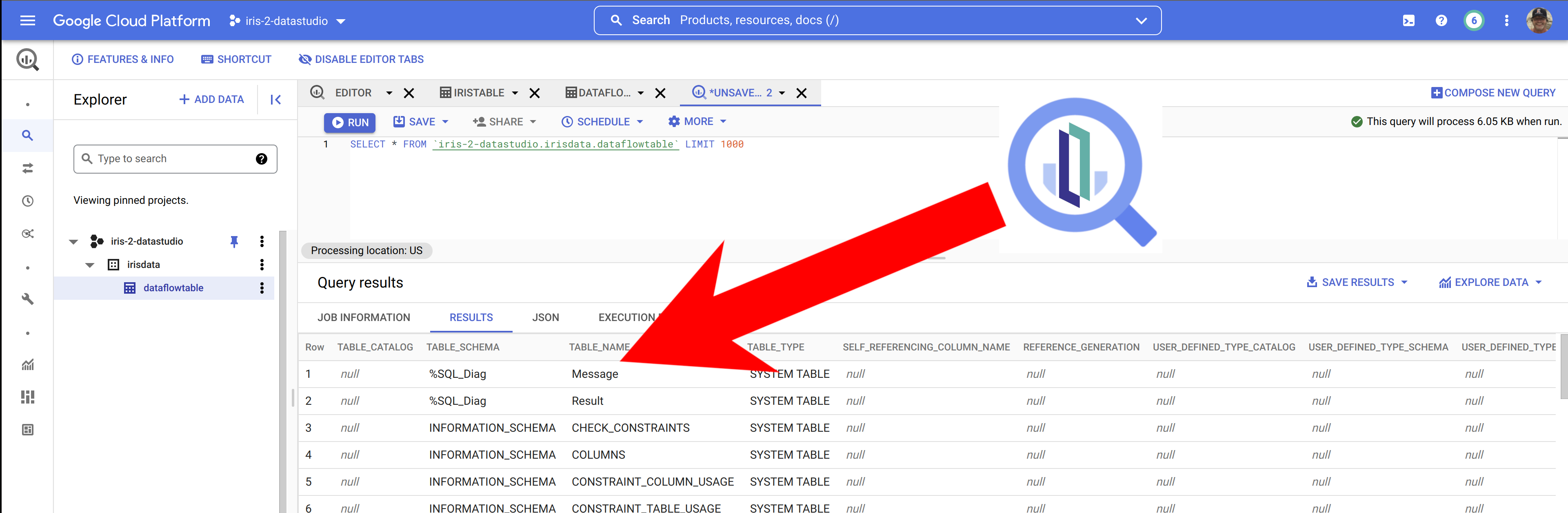
Observando a consulta e os dados de origem no InterSystems Cloud SQL...
... e inspecionando os resultados no Big Query, parece que realmente temos os dados do InterSystems IRIS no Big Query.
Depois de ter os dados no Big Query, é simples incluir nossos dados do IRIS no Data Studio ao selecionar o Big Query como fonte de dados... o exemplo abaixo não é muito elegante, mas você pode ver rapidamente os dados do IRIS prontos para manipulação no seu projeto do Data Studio.

No cenário de dados atual, as empresas enfrentam vários desafios diferentes. Um deles é fazer análises sobre uma camada de dados unificada e harmonizada disponível para todos os consumidores. Uma camada que possa oferecer as mesmas respostas às mesmas perguntas, independentemente do dialeto ou da ferramenta usada. A Plataforma de Dados InterSystems IRIS responde a isso com um complemento de Análise Adaptativa que pode fornecer essa camada semântica unificada. Há muitos artigos no DevCommunity sobre como usá-lo por ferramentas de BI. Este artigo abordará como consumi-lo com IA e também como recuperar alguns insights. Vamos ir por etapas...
Você pode facilmente encontrar uma definição [no site developer community] (https://community.intersystems.com/tags/adaptive-analytics) Resumindo, ela pode fornecer dados de forma estruturada e harmonizada para diversas ferramentas de sua escolha para consumo e análise posterior. Ela oferece as mesmas estruturas de dados a várias ferramentas de BI. Mas... Ela também pode oferecer as mesmas estruturas de dados para suas ferramentas de IA/ML!
A Análise Adaptativa tem um componente adicional chamado AI-LINK que constrói essa ponte entre a IA e a BI.
É um componente Python criado para permitir a interação programática com a camada semântica para os fins de otimizar os principais estágios do fluxo de trabalho do aprendizado de máquina (ML) (por exemplo, engenharia de características).
Com o AI-Link, você pode:
Como é uma biblioteca Python, ela pode ser usada em qualquer ambiente Python. Incluindo Notebooks. Neste artigo, darei um exemplo simples de como alcançar a solução de Análise Adaptativa a partir do Jupyter Notebook com a ajuda do AI-Link.
Aqui está o repositório git com o Notebook completo como exemplo: https://github.com/v23ent/aa-hands-on
Para os passos a seguir, presume-se que você concluiu os pré-requisitos:
Primeiro, vamos instalar os componentes necessários em nosso ambiente. Isso baixará alguns pacotes que são necessários para que as próximas etapas funcionem. 'atscale' - nosso pacote principal para a conexão 'prophet' - pacote de que precisaremos para fazer previsões
pip install atscale prophet
Em seguida, precisamos importar as principais classes que representam alguns conceitos importantes da nossa camada semântica. Client - classe que usaremos para estabelecer uma conexão com a Análise Adaptativa; Project - classe para representar projetos dentro da Análise Adaptativa; DataModel - classe que representará nosso cubo virtual;
from atscale.client import Client
from atscale.data_model import DataModel
from atscale.project import Project
from prophet import Prophet
import pandas as pd
Agora, deve estar tudo pronto para estabelecer uma conexão com nossa origem de dados.
client = Client(server='http://adaptive.analytics.server', username='sample')
client.connect()
Vá em frente e especifique os detalhes de conexão da sua instância da Análise Adaptativa. Quando for solicitada a organização, responda na caixa de diálogo e insira sua senha da instância da AtScale.
Com a conexão estabelecida, você precisará selecionar seu projeto da lista de projetos publicados no servidor. Você verá a lista de projetos como um prompt interativo, e a resposta deve ser o ID inteiro do projeto. O modelo de dados será selecionado automaticamente se for o único.
project = client.select_project()
data_model = project.select_data_model()
Há vários métodos preparados pela AtScale na biblioteca de componentes do AI-Link. Eles permitem explorar seu catálogo de dados, consultar dados e até ingerir alguns dados de volta. A documentação da AtScale tem uma vasta referência da API, descrevendo tudo o que está disponível. Primeiro, vamos ver qual é o nosso conjunto de dados ao chamar alguns métodos de "data_model":
data_model.get_features()
data_model.get_all_categorical_feature_names()
data_model.get_all_numeric_feature_names()
A saída será algo assim

Depois de olhar um pouco, podemos consultar os dados em que realmente temos interesse usando o método "get_data". Ele retornará um DataFrame do pandas com os resultados da consulta.
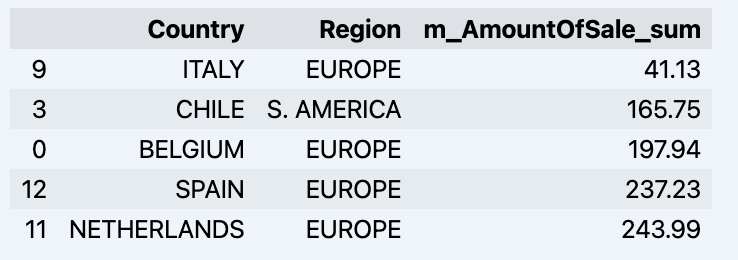
df = data_model.get_data(feature_list = ['Country','Region','m_AmountOfSale_sum'])
df = df.sort_values(by='m_AmountOfSale_sum')
df.head()
Que mostrará seu dataframe:
Vamos preparar um conjunto de dados e exibi-lo rapidamente no gráfico
import matplotlib.pyplot as plt
# Estamos pegando as vendas para cada data
dataframe = data_model.get_data(feature_list = ['Date','m_AmountOfSale_sum'])
# Crie um gráfico de linhas
plt.plot(dataframe['Date'], dataframe['m_AmountOfSale_sum'])
# Adicione rótulos e um título
plt.xlabel('Days')
plt.ylabel('Sales')
plt.title('Daily Sales Data')
# Exiba o gráfico
plt.show()
Saída:

A próxima etapa seria obter um valor da ponte do AI-Link - vamos fazer algumas previsões simples!
# Carregue os dados históricos para treinar o modelo
data_train = data_model.get_data(
feature_list = ['Date','m_AmountOfSale_sum'],
filter_less = {'Date':'2021-01-01'}
)
data_test = data_model.get_data(
feature_list = ['Date','m_AmountOfSale_sum'],
filter_greater = {'Date':'2021-01-01'}
)
Obtemos 2 conjuntos de dados diferentes aqui: para treinar e testar nosso modelo.
# Para a ferramenta, escolhemos fazer a previsão "Prophet", em que precisamos especificar 2 colunas: "ds" e "y"
data_train['ds'] = pd.to_datetime(data_train['Date'])
data_train.rename(columns={'m_AmountOfSale_sum': 'y'}, inplace=True)
data_test['ds'] = pd.to_datetime(data_test['Date'])
data_test.rename(columns={'m_AmountOfSale_sum': 'y'}, inplace=True)
# Inicialize e ajuste o modelo Prophet
model = Prophet()
model.fit(data_train)
Em seguida, criamos outro dataframe para acomodar nossa previsão e exibi-la no gráfico
# Crie um dataframe futuro para previsão
future = pd.DataFrame()
future['ds'] = pd.date_range(start='2021-01-01', end='2021-12-31', freq='D')
# Faça previsões
forecast = model.predict(future)
fig = model.plot(forecast)
fig.show()
Saída:

Depois de obter a previsão, podemos colocá-la de volta no armazém de dados e adicionar uma agregação ao nosso modelo semântico para que reflita para outros consumidores. A previsão estaria disponível por qualquer outra ferramenta de BI para usuários empresariais e analistas de BI. A previsão em si será colocada em nosso armazém de dados e armazenada lá.
from atscale.db.connections import Iris
db = Iris(
username,
host,
host,
driver,
schema,
schema,
password=None,
warehouse_id=None
)
data_model.writeback(dbconn=db,
table_name= 'SalesPrediction',
DataFrame = forecast)
data_model.create_aggregate_feature(dataset_name='SalesPrediction',
column_name='SalesForecasted',
name='sum_sales_forecasted',
aggregation_type='SUM')
É isso! Boa sorte com suas previsões!
Alguns meses atrás, enfrentei um desafio importante: otimizar o tratamento da lógica de negócios em nosso aplicativo. Meu objetivo era extrair a lógica de negócios do código e passar para analistas. Lidar com várias regras pode resultar facilmente em um código desorganizado com uma infinidade de instruções "if", especialmente se o programador não entende a complexidade ciclomática. Esse código vira uma dor de cabeça para quem trabalha com ele — difícil de escrever, testar e desenvolver.
Depois de explorar várias opções, incluindo tentar ensinar Python a analistas 😀, me deparei com a técnica Decision Model Notation (DMN) para descrever a lógica de negócios. Ela se mostrou um sucesso — analistas poderiam agora articular a lógica de negócios sozinhos, reduzindo mais de mil linhas de código a apenas três + arquivo de descrição DMN.
Agora, vamos nos aprofundar na solução.
O DMN, concebido em 2015 pelos criadores do BPMN, interage bem com o último, mas também pode ser usado de maneira independente.
O principal conceito do DMN é a capacidade de gerenciar decisões semelhantes a outros aspectos dos seus aplicativos. Por exemplo, considere uma solução para calcular bônus — você pode modificá-la de maneira independente sem afetar outros elementos do aplicativo.
O DMN opera de duas formas:
Portanto, nosso código é parecido com isto
 | 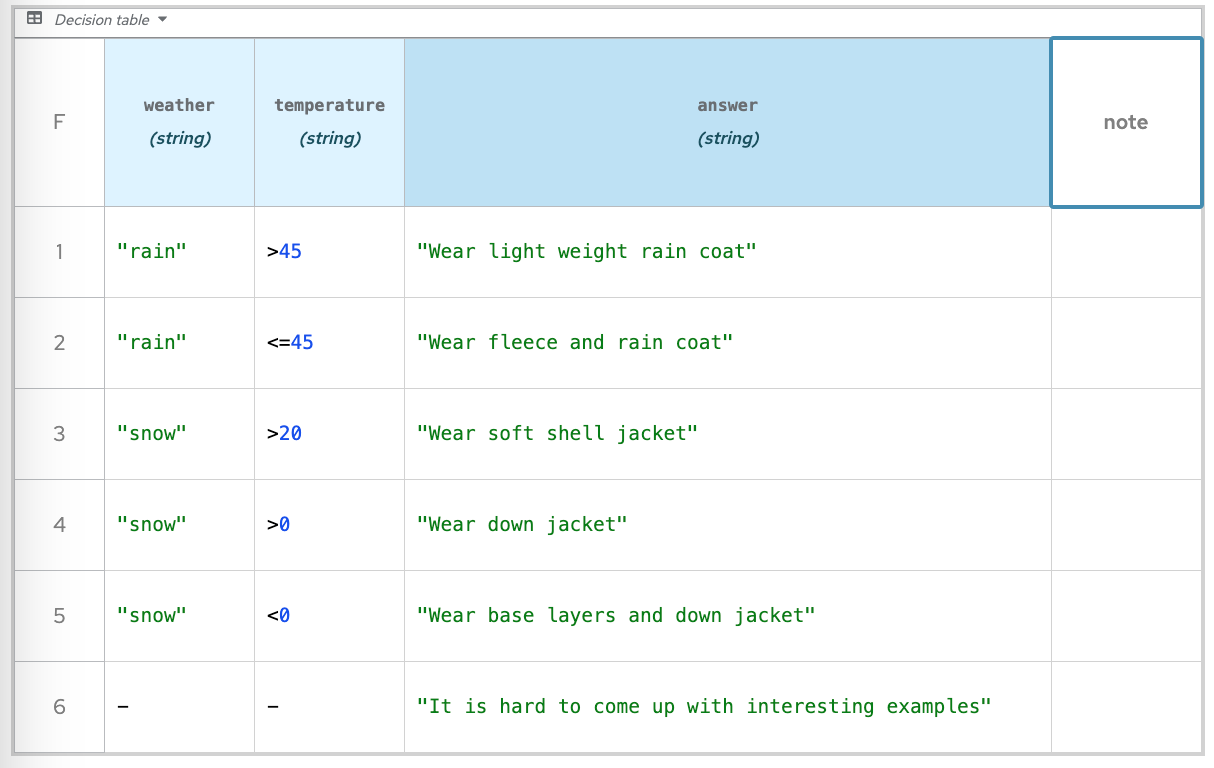 |
Será uma tabela simples
Basicamente, é uma tabela em que os seguintes itens são definidos:
Em conclusão, o uso do Decision Model and Notation (DMN) oferece vários benefícios para a gestão da lógica de negócios:
E sim, depois de tudo isso, você pode usar seus esquemas do DMN com os dados armazenados no seu banco de dados do IRIS - https://openexchange.intersystems.com/package/iris-dmn
Se você tiver interesse em saber mais sobre o DMN, a linguagem FEEL e o motivo pelo qual a solução foi criada em JAVA, envie suas perguntas, vou responder nos comentários em mais detalhes
Informações adicionais sobre o DMN
https://docs.drools.org/latest/drools-docs/drools/DMN/index.html - a documentação mais detalhada
https://sandbox.kie.org/ - sandbox online onde você tentar desenhar seu próprio diagrama
https://learn-dmn-in-15-minutes.com/ - tutorial interativo
Ao analisar dados, geralmente é preciso procurar indicadores específicos com mais atenção e destacar seções de informações de especial interesse para um usuário.
Por exemplo, examinar as dinâmicas dos dados para regiões ou datas específicas pode nos ajudar a descobrir tendências e padrões ocultos que permitem a tomada de decisões conscientes sobre nosso projeto no futuro.
Para conduzir uma análise de dados detalhada assim, é mais eficaz usar o método de análise fracionária ou detalhamento. Esse método permite "mergulhar" nos dados, saindo do quadro geral para pequenos fragmentos.
Neste artigo, vamos dar uma visão clara sobre como organizar a navegação com a ajuda de técnicas de detalhamento entre relatórios na DSW (DeepSeeWeb) e do InterSystems Reports (com a tecnologia do Logi Reports) usando filtros em links.
Ao realizar nossas tarefas, nos deparamos com a necessidade de simplificar a navegação dos relatórios gerais para os dados mais detalhados, considerando diferentes categorias, como datas, regiões ou participantes. Por esse motivo, decidimos encontrar uma maneira de migrar de um relatório geral para um detalhado com uma data específica ou outras características em apenas um clique.
Uma solução que usa filtros em links mostrou ser a opção mais adequada para essa tarefa. A plataforma DSW oferece uma ampla variedade de ferramentas que permite configurar parâmetros de filtros com flexibilidade e passar esses filtros de links de URLs para relatórios. Por sua vez, ela deixa a navegação entre relatórios mais confortável e preserva o contexto para uma análise de dados mais complexa.
Para organizar a análise de dados de detalhamento na DSW utilizando filtros, seguimos estas etapas:
No início do processo, criamos relatórios que ofereciam informações mais explícitas sobre vários aspectos dos dados. Em nosso caso, criamos relatórios que detalham os dados por data, incluindo em meses e dias individuais.
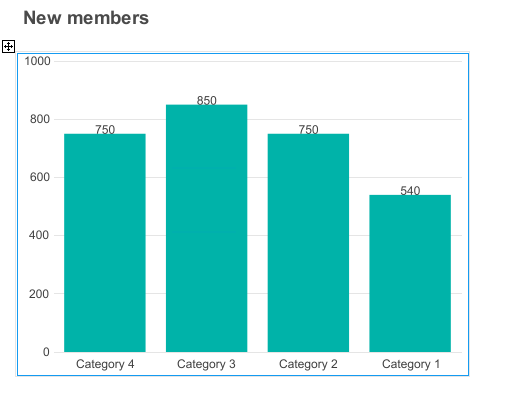
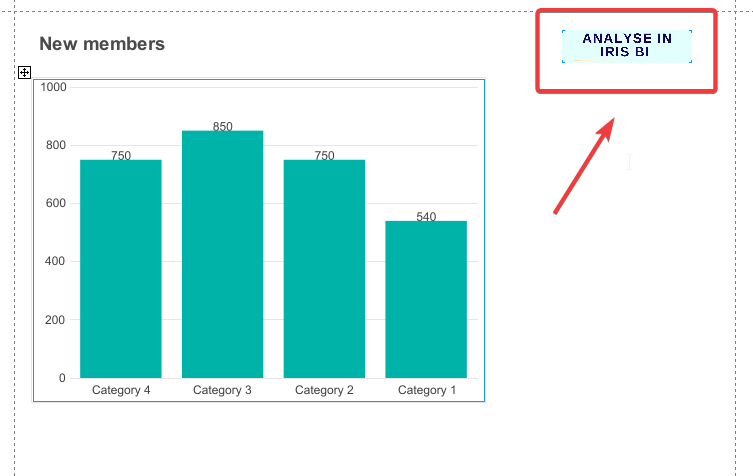
Em seguida, criamos um painel de controle com o gráfico "Novos membros" na DSW:
Para cada nível de detalhe, configuramos relatórios correspondentes no InterSystems Reports. Por exemplo, para o relatório do gráfico "Novos membros" no nível do mês, fizemos o seguinte:
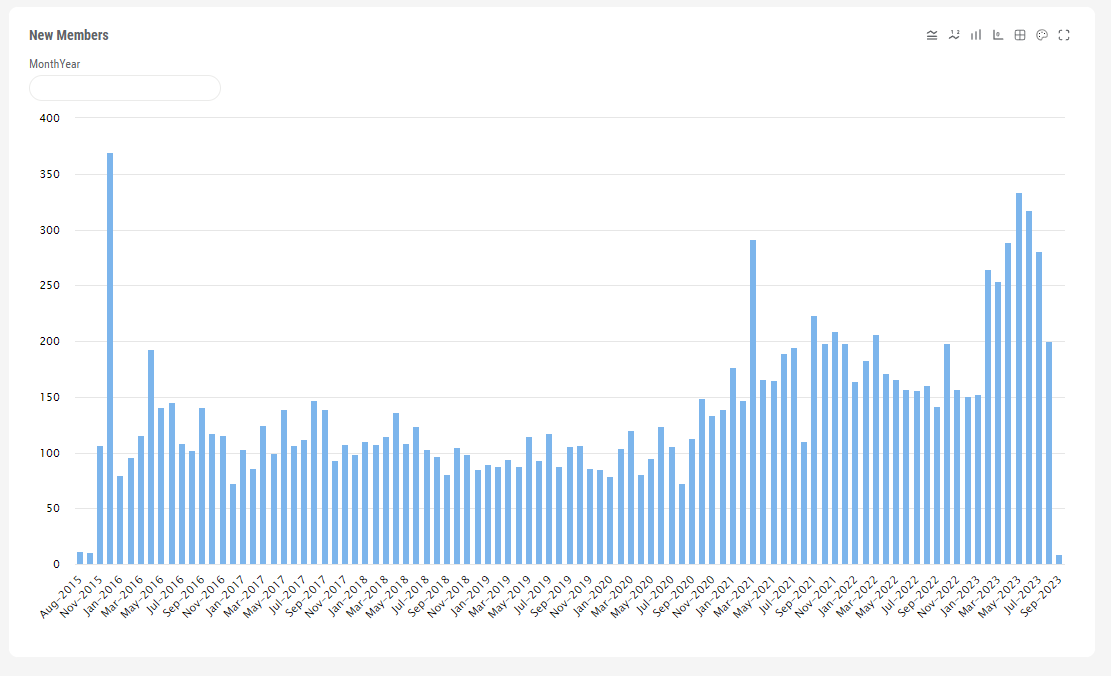
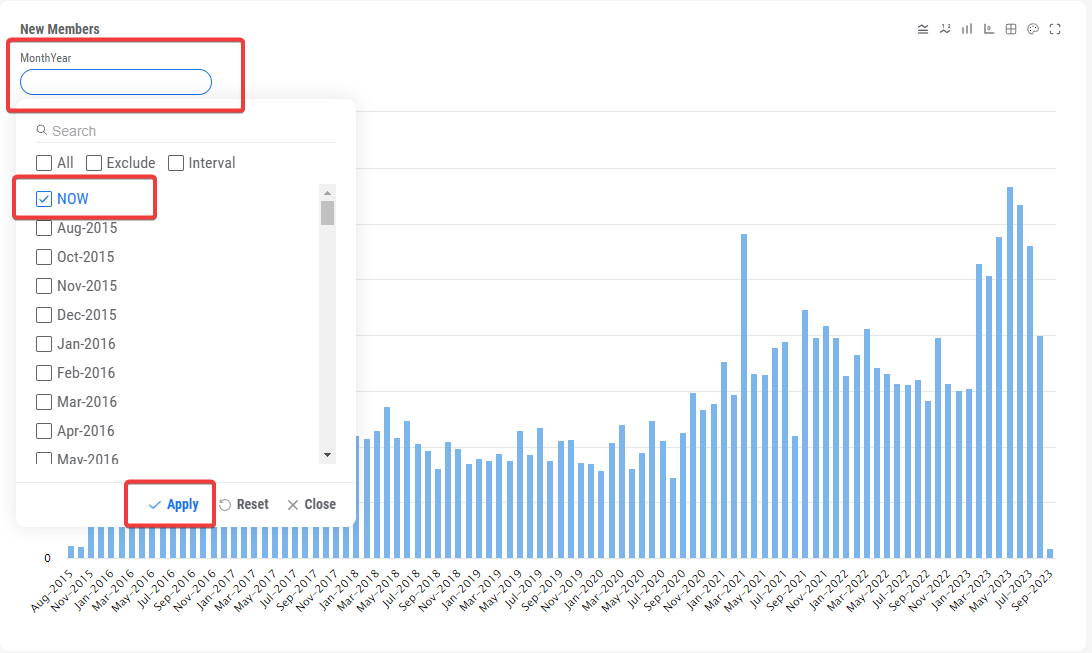
Nessa etapa, precisamos configurar filtros na DSW que serão aplicados ao clicar nos links. Em nosso exemplo, o filtro deve selecionar data por data. Para ajustá-lo, siga as etapas mencionadas abaixo:
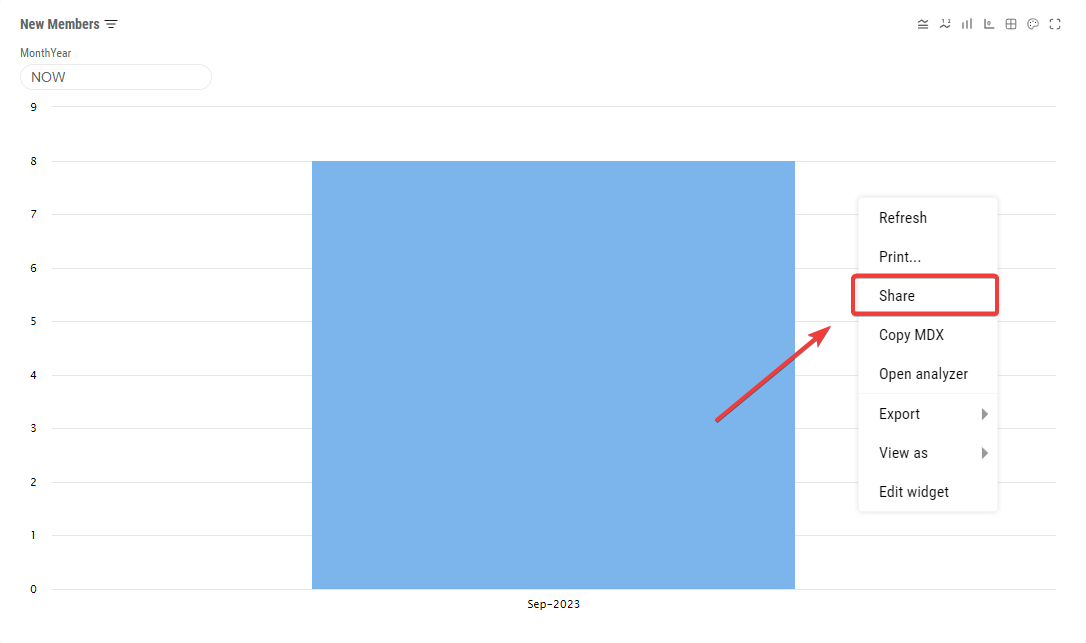
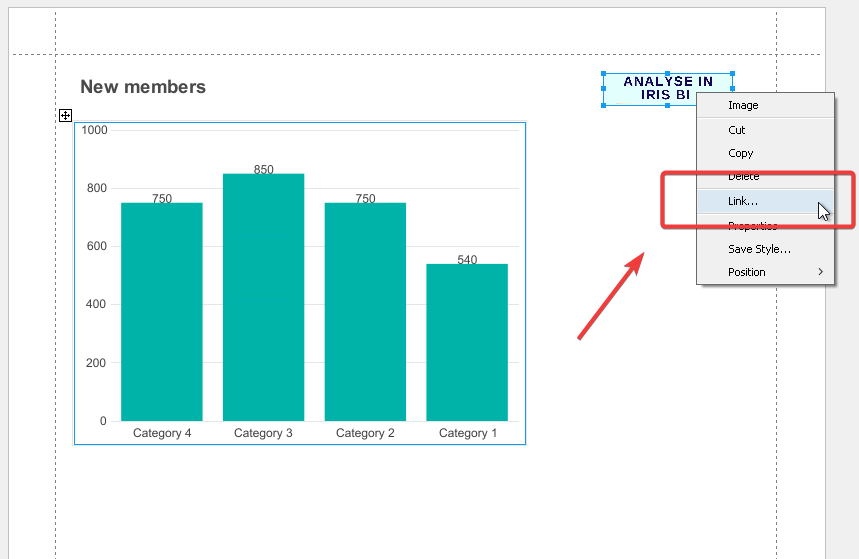
Depois de clicar no gráfico com o botão direito do mouse e selecionar o campo "Share" (Compartilhar) no menu, será exibida a janela abaixo:
Na janela aberta com o link, copie o link ao clicar no botão "Copy" (Copiar):
Até agora, configuramos os filtros na DSW. Eles serão aplicados ao clicar nos links dos relatórios gerais e detalhados. Por exemplo, para selecionar os dados de uma data específica, realizamos as seguintes etapas:
Para proporcionar ainda mais flexibilidade e confiança ao passar parâmetros de filtro em links de URL, podemos usar a codificação Base64. É uma adição conveniente que permite evitar conflitos com caracteres como "&" ou "=" que podem aparecer dentro dos dados do filtro.
Como funciona?
Na janela com o link, marque a caixa de seleção "Filters as Base64" (Filtros como Base64):
Ao usar Base64, os valores dos parâmetros de filtro são convertidos em um formato específico que não contém caracteres que interferem no link de URL. Assim, obtemos uma maneira segura e confiável de transferir dados entre relatórios.
A próxima etapa será adicionar links a relatórios detalhados na DSW e Logi Reports em geral, que abrirá com os filtros desejados.
Por exemplo, em nosso relatório com novos participantes, vamos adicionar uma imagem com um link para nosso gráfico na DSW com um filtro de data.
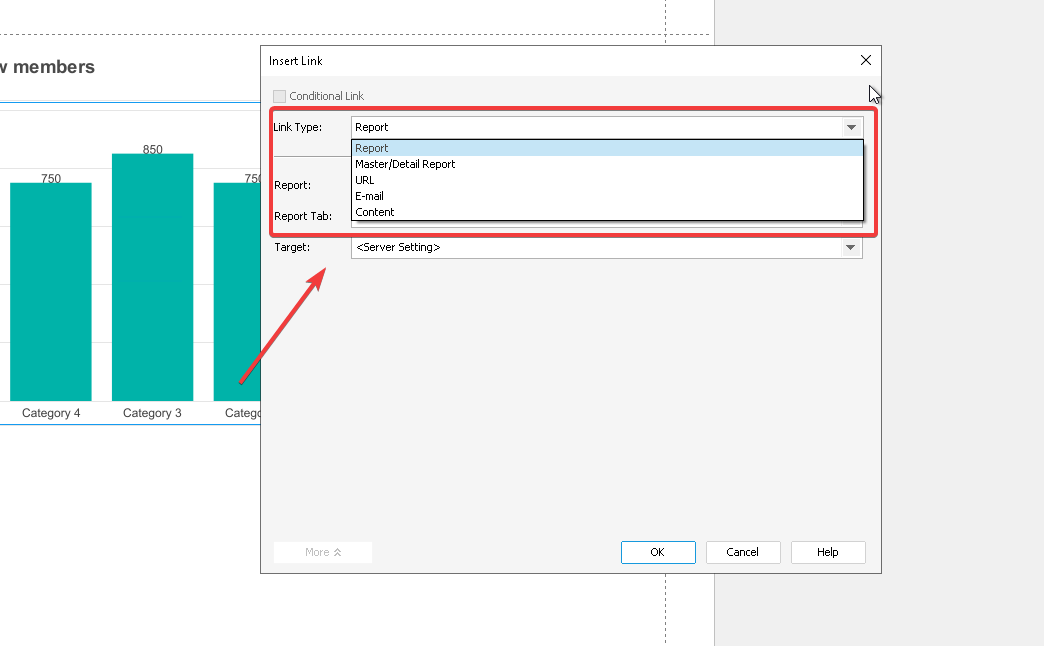
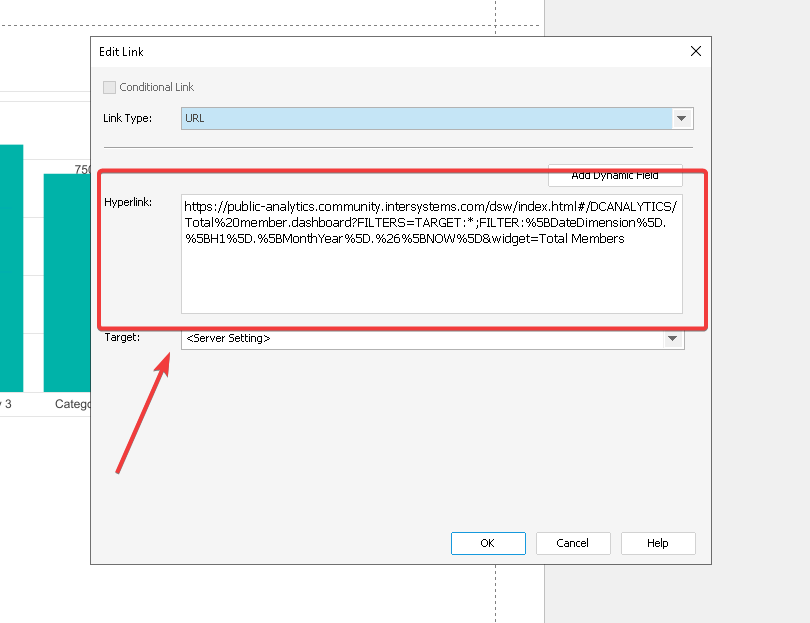
Vou decifrar o link do painel de controle na DSW para você:
Vamos dividir em partes:
https://public-analytics.community.intersystems.com/dsw/index.html#/DCANALYTICS/Total%20member.dashboard - um caminho para o painel de controle "Total de membros" no espaço DCANALYTICS
?FILTERS=TARGET:* - um comando para aplicar um filtro a todos os objetos no painel de controle (TARGET:*)
FILTER:[DateDimension].[H1].[MonthYear].&[NOW] - o filtro. Filtra os dados pelo campo [DateDimension], usando a hierarquia [H1] no nível [MonthYear]. &[NOW] - significa o mês atual.
&widget=Total Members - um comando que abre o painel de controle e foca no widget "Total de membros".
Então, esse link faz tudo isto:
Ele abre o painel de controle "Total de membros".
Ele aplica um filtro no campo "Date" (Data), selecionando o mês atual.
Ele foca no widget "Total de membros".
Portanto, o relatório mostrará dados sobre o número total de participantes para o mês atual. O filtro é aplicado automaticamente quando o painel de controle é aberto.
Os links podem ser colocados no relatório diretamente como texto ou você pode incluí-los como botões ou imagens.
Para possibilitar a transição entre relatórios, adicionamos os links apropriados ao InterSystems Reports. Por exemplo, inserimos uma imagem vinculada a um relatório da DSW com um filtro de data ao relatório com um gráfico de novos participantes. Para fazer o mesmo, siga estas etapas:
Agora, ao clicar na imagem, é aberto um relatório na DSW com os dados dos novos membros para o mês atual.
A abordagem descrita de organização detalhada usando filtros em referências tem as seguintes vantagens:
Com essa abordagem, conseguimos adicionar uma capacidade de detalhamento de dados conveniente para analistas. Como resultado, eles podem "mergulhar" de maneira independente nos relatórios com apenas um clique do mouse conforme necessário.
Isso acelera significativamente a análise de dados, permite a identificação mais rápida de situações fora do padrão e oferece uma compreensão das causas de desvio. Consequentemente, a gestão da tomada de decisões se torna mais justificada.
Conclusões sobre as capacidades da análise de detalhamento
Além dos benefícios descritos neste artigo, a análise de dados de detalhamento oferece diversas outras capacidades avançadas:
Detalhamento profundo: os usuários ainda podem detalhar vários níveis dos dados, analisando até mesmo os menores detalhes e identificando os padrões e as anomalias mais ocultas.
Análise comparativa: a análise de detalhamento permite que você compare dados entre diferentes níveis de dados ou fatias, o que pode ser útil ao identificar diferenças e tendências.
Interatividade: os usuários podem mudar os parâmetros de filtragem em tempo real e ver como isso afeta os resultados, deixando a análise mais interativa e adaptativa.
Estrutura hierárquica: se os dados têm uma estrutura hierárquica (por exemplo, uma hierarquia organizacional), a análise de detalhamento facilita examinar os dados em diferentes níveis dessa hierarquia.
Suporte a várias medidas: os usuários podem analisar várias medidas ao mesmo tempo, permitindo que os dados sejam vistos de várias perspectivas.
Crie relatórios na hora: a análise de detalhamento permite que os usuários criem relatórios personalizados com base no relatório de modelo ao adicionar ou remover parâmetros de detalhamento como quiserem.
Gerencie níveis de acesso: você pode gerenciar o acesso do usuário a diferentes níveis de granularidade, garantindo a segurança dos dados.
Automação do processo: algumas ferramentas de análise de detalhamento permitem que você automatize a filtragem e as transições entre relatórios, poupando bastante tempo dos analistas.
Compatíveis com dados diversos: a análise de detalhamento pode ser aplicada a uma variedade de origens de dados, incluindo bancos de dados, planilhas e serviços da Web.
Monitoramento e alertas: alguns sistemas de análise de detalhamento permitem que você personalize o monitoramento de dados e receba alertas quando ocorrerem mudanças importantes.
Todos os recursos mencionados acima fazem com que a análise de detalhamento seja uma ferramenta poderosa para analisar dados e tomar decisões de gestão informadas. Com ela, é possível explorar dados em um nível profundo, descobrir novos insights e, por fim, melhorar a eficiência dos processos de negócios.
Olá Comunidade!
Quero compartilhar com vocês uma nova abordagem para solucionar os desafios de otimizar o gerenciamento de dados da InterSystems: o InterSystems TotalView™ For Asset Management, que oferece uma maneira melhor de integrar e transformar dados, criando uma fonte única, confiável e oportuna, para impulsionar decisões críticas.
Olá Comunidade,
Clique no play e mergulhe em nosso novo vídeo no InterSystems Developers YouTube:
⏯ Adaptive Analytics in Action - Two Customer Use Cases @ Global Summit 2023
Com o InterSystems IRIS 2022.2, apresentamos o armazenamento colunar como uma nova opção para a persistência das suas tabelas SQL do IRIS que pode otimizar suas consultas analíticas por ordem de magnitude. O recurso está marcado como experimental em 2022.2 e 2022.3, mas se tornará um recurso de produção totalmente compatível no próximo lançamento de 2023.1.
A documentação do produto e este vídeo introdutório já descrevem as diferenças entre o armazenamento em linhas, que ainda é o padrão no IRIS e é usado pela nossa base de clientes, e o armazenamento de tabela colunar, além de fornecer orientações de alta qualidade para a escolha do layout de armazenamento adequado para seu caso de uso. Neste artigo, vamos falar sobre esse tema e compartilhar algumas recomendações com base nos princípios de modelagem do setor, testes internos e feedback dos participantes do Programa de Acesso Antecipado.
Em geral, nossas orientações para escolher um layout de tabela adequado para seu esquema SQL do IRIS são as seguintes:
O proveito variará com base nos parâmetros ambientais e relacionados a dados. Portanto, recomendamos enfaticamente que os clientes testem os diferentes layouts em uma configuração representativa. Os índices colunares são fáceis de adicionar a uma tabela regular organizada por linhas e fornecerão rapidamente uma perspectiva realista dos benefícios do desempenho da consulta. Isso, com a flexibilidade de layouts de tabela mistos, é um diferencial importante do InterSystems IRIS que ajuda os clientes a obter uma melhoria de desempenho de ordem de magnitude.
Pretendemos tornar essas recomendações mais concretas conforme tivermos mais experiência real com a versão de produção completa. Obviamente, podemos fornecer conselhos mais concretos com base no esquema real e na carga de trabalho dos clientes pelo Programa de Acesso Antecipado e compromissos com POCs, e aguardamos o feedback de clientes e membros da comunidade. O armazenamento colunar faz parte da licença do InterSystems IRIS Advanced Server e também está habilitado na Community Edition do InterSystems IRIS e IRIS for Health. Para um ambiente de demonstração com script completo, consulte este repositório do GitHub.
De acordo com o relatório Global Fraud and Identity Report 2020 da Experian, as fraudes no setor financeiro globalmente ultrapassaram a marca de US$ 42 bilhões em 2020, com destaque para fraudes de identidade, bancárias, em cartões de crédito e débito, em empréstimos e em aplicativos móveis bancários. A pandemia do COVID-19 impulsionou o crescimento de fraudes relacionadas à saúde, como fraudes em benefícios de seguro-saúde e em programas de ajuda financeira do governo. Considerando tais dados, fica claro que é essencial que as instituições financeiras adotem soluções eficientes para detectar
Apache Superset é uma plataforma moderna de exploração e visualização de dados. O Superset pode substituir ou trazer ganhos para as ferramentas proprietárias de business intelligence para muitas equipes. O Superset integra-se bem com uma variedade de fontes de dados.
E agora é possível usar também com o InterSystems IRIS.
Uma demo online está disponível e usa IRIS Cloud SQL como sua fonte de dados.
.png)
Oi Comunidade,
Divirta-se assistindo ao novo vídeo no InterSystems Developers YouTube:
⏯ Consultando 6 terabytes de informações de saúde protegidas na Northwell @ Global Summit 2022
Boa tarde,
Utilizo o Caché COS e estou com dificuldade para fazer um POP3 no servidor de e-mail da Microsoft, utilizando a autenticação OAuth 2.0.
Estou utilizando o seguinte programa para realizar essa tarefa:
No nosso último episódio do Data Points, tive uma conversa com @Thomas Dyar sobre AI Link, que ajuda a preencher a lacuna entre cientistas de dados e analistas de negócios. Nossa conversa fala sobre como o AI Link se encaixa com IntegratedML e Adaptive Analytics, bem como quais novos recursos estão no horizonte para IntegratedML. Ouça!
Olá desenvolvedores!
Convidamos você para um novo webinar em espanhol: "Análise de dados em FHIR. Do paciente à população", na quinta-feira, 17 de novembro, às 11h (horário de Brasília).
O webinar será transmitido ao vivo do Congresso "Iberia Summit" que a InterSystems realizará em Valência na próxima semana.

Análise do InterSystems Developer Community. Projeto criado com o BI do InterSystems IRIS (DeepSee), Power BI e Logi Report Designer para visualizar e analisar membros, artigos, perguntas, respostas, visualizações e outros conteúdos e atividades no InterSystems Developer Community.
Você pode ver sua própria atividade, artigos e perguntas. Monitore a forma como sua contribuição muda a comunidade de desenvolvedores.
Analise estatísticas sobre você e seus amigos usando BI do IRIS, Análise Adaptativa, Relatórios da InterSystems, Tableau e Power BI.
Esse projeto contém implantação IRIS e Atscale pré-configurada em contêineres Docker e arquivos de projeto para sistemas de BI.
Veja mais informações detalhadas no README do aplicativo correspondente.
Esse projeto também foi implantado online e você pode conferir aqui.
Olá Desenvolvedores,
Este novo vídeo já se encontra no Canal YouTube dos Desenvolvedores InterSystems:
⏯ Solução Analítica InterSystems HealthShare: Crie e Entregue Análises em Tempo Real em Escala
A interoperabilidade é um dos assuntos mais discutidos nos últimos anos. Notamos cada vez mais que nossos dados de saúde estão sendo compartilhados entre vários sistemas, com o propósito de trazer para mais próximo o conceito de saúde do paciente em primeiro lugar.
A plataforma de dados InterSystems IRIS © agora apresenta suporte nativo completo para Python, liberando o poder da linguagem de programação mais popular do mundo para criar aplicativos de missão crítica com uso intensivo de dados.
Essa decisão estratégica leva em consideração vários fatores:
A seguir iremos explorar esses pontos.
.png)
Oi comunidade,
Em um trabalho intenso de curadoria e qualidade de dados, a aplicação "health dataset" entrega os conjuntos de dados acima.
Esses conjuntos de dados podem ser utilizados no seu modelo ou aplicação de Machine Learning, AutoML e de aplicações analíticas. Veja mais detalhes aqui:
1. Clone/git pull no repositório em qualquer diretório local
$ git clone https://github.com/yurimarx/automl-heart.git
2. Abra o terminal no diretório da aplicação e execute:
$ docker-compose build
3. Execute o IRIS container:
$ docker-compose up -d
4. Faça um select no HeartDisease dataset:
Você já ouviu falar sobre algumas restrições em cookies para rastrear visitantes em seus sites?
Um de nossos clientes me perguntou como saber realmente a contagem de visitantes.
Seu site funciona no framework WordPress, hospedado na clássica hospedagem NAMP.
Eles podem ver algumas estatísticas do Yandex Metrika conter, mas não tínhamos certeza sobre a cobertura completa.
Demos a ele o AWStats, ele pega dados de arquivos de log do Apache na hospedagem.
Mas não havia nenhum filtro de robôs e sistemas de pulsação, como UptimeRobot ou robôs de indexação de motores de busca.
Olá Comunidade,
Não percam a oportunidade de participar em mais um webinar com Odilon Almeida, Executivo de Vendas InterSystems, sobre como a InterSystems se posiciona para a modernização do legado de Data Warehouse no mercado.
Dia 06/10 às 11h! Inscreva-se já, vagas limitadas!

Sou apaixonado por documentários! No último final de semana estava assistindo um documentário da Netflix chamado This is Pop, como está na época do concurso InterSystems IRIS Analytics, pensei: Por que não criar um analítico da música Pop com InterSystems Iris?
O primeiro desafio era a base. Encontrei no Data World project um arquivo CSV com a lista dos top 100 da Billboard de 2000 à 2018, criado por "Michael Tauberg" @typhon, que encaixava perfeitamente.
Estava conversando com o @Henrique Dias e ele me deu a ideia de usar o Microsoft Power BI para criar um relatório com gráficos bonitos.
Vamos analisar a base de dados, com ajuda do csvgen importamos o arquivo CSV.
A base contém:
Title — nome da música
Artist — nome do Artista
Energy — a energia da música — maior o valor, mais energia
Danceability — maior o valor, mais fácil de dançar a música
Loudness..dB.. — maior o valor, mais alta é a música
Liveness — maior o valor, mais provável que a música é uma gravação ao vivo.
Valence. — maior o valor, mais positiva é o estado de espírito da música.
Duration_ms. — a duração da música em milisegundos.
Acousticness.. maior o valor, mais acústica é a música
Speechiness. — maior o valor, mais palavras a música contém
Lyrics — Letra da música.
Genre — Gênero musical
No arquivo CSV o gênero é um array como este: [u'dance pop', u'hip pop', u'pop', u'pop rap', u'rap']
Minha ideia é criar uma tabela Genre (Gênero) e outra para resolver o relacionamento N:N. Um simples script popula estas tabelas.
Depois disto, é só conectar o Power BI no InterSystems Iris (aqui tem um passo-a-passo de como fazer isto).
Próximo passo: Infograficos legais.
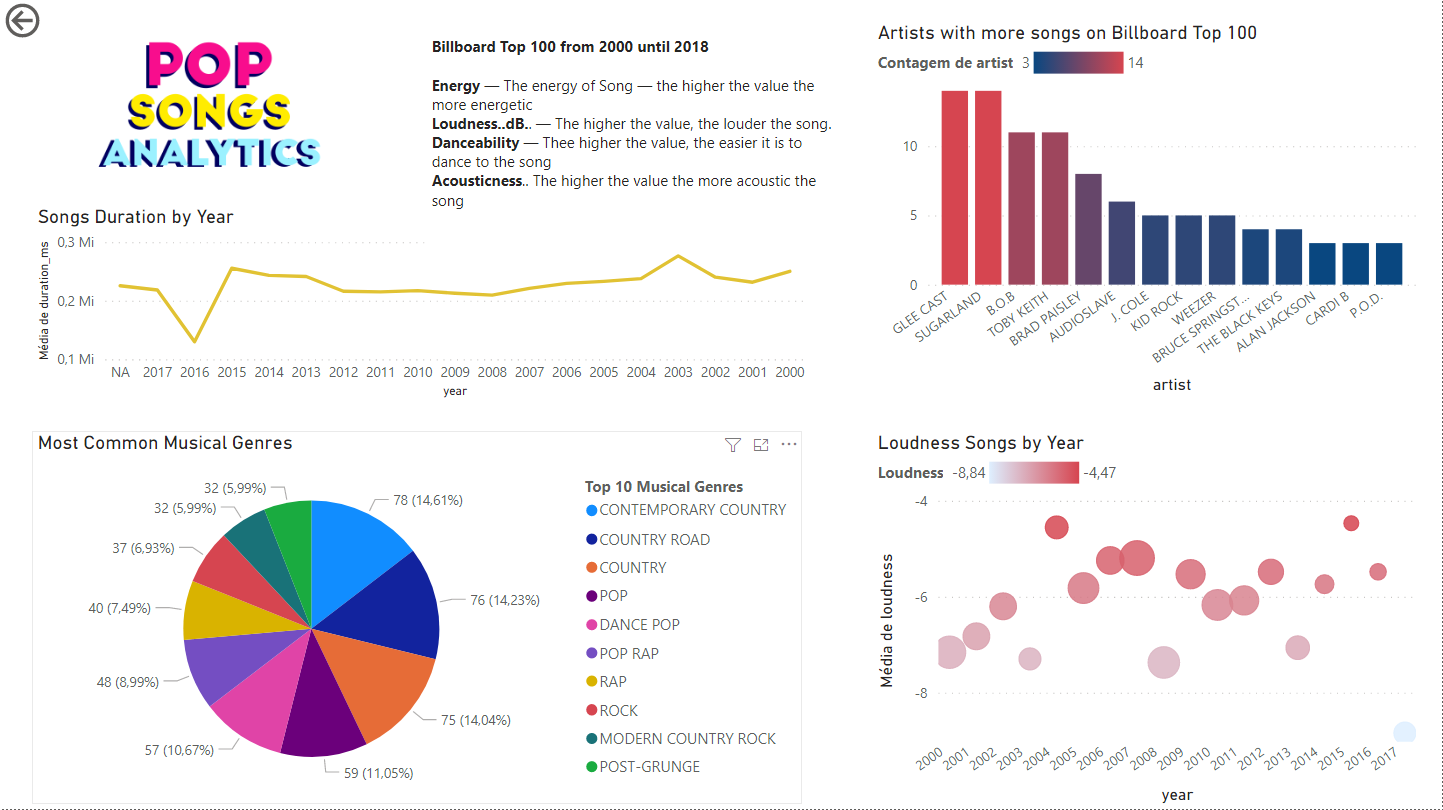
Um gráfico de barras mostra a quantidade de artistas com mais músicas na Billboard e um gráfico de linha exibe a duração média das músicas por ano.
Um gráfico de pizza mostra os gêneros mais comuns, para minha surpresa, country contemporâneo é o gênero mais popular.
Música pop tem se tornado barulhenta com o passar dos anos? Para responder usei um diagrama de dispersão com a média loudness das músicas.
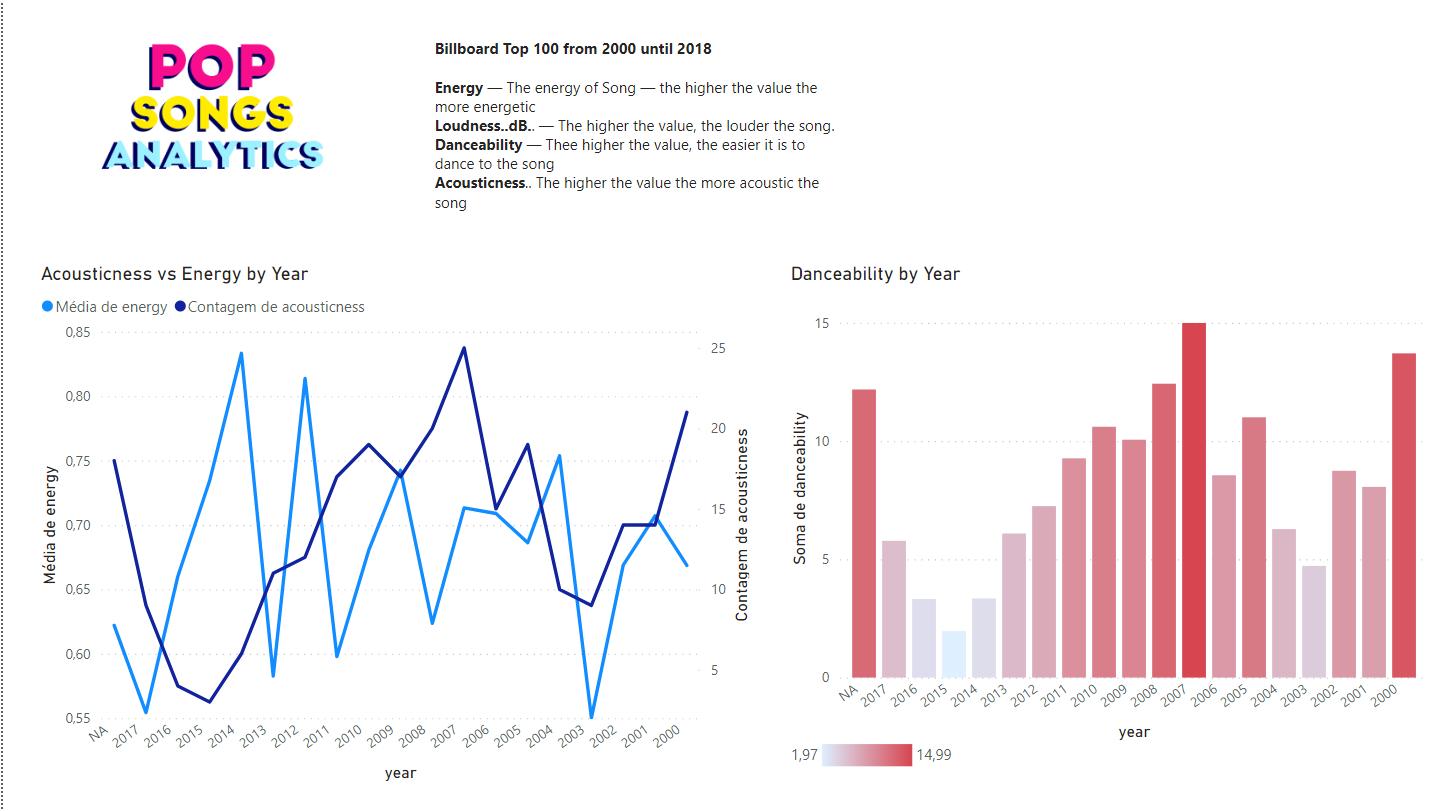
Na segunda página um gráfico de barras mostra a como a danceability mudou pelos anos e a relação entre energy versus acousticness.
https://openexchange.intersystems.com/contest/current
Agradecimento especial ao @Henrique Dias pelas boas conversas e pelo apoio.
Olá Desenvolvedores!
Aqui estão os bônus tecnológicos para o Concurso InterSystems IRIS Analytics que irão fornecer pontos extras na votação.
Uso de Cubos do Adaptive Analytics (AtScale) - 4 pontos
O InterSystems Adaptive Analytics fornece a opção de criar e utilizar cubos do AtScale em soluções analíticas.
Você pode utilizar o servidor AtScale que disponibilizamos para o concurso (a URL e as credenciais podem ser obtidas através do Canal do Discord) para utilizar os cubos ou criar o seu próprio e conectar com seu servidor IRIS através de JDBC.
A camada de visualização para sua solução analítica com o AtScale pode ser construída com o uso do Tableau, PowerBI, Excel ou Logi.
Olá Comunidade,
Estamos muito felizes em convidar todos os desenvolvedores para o Webinar de Lançamento do Concurso InterSystems IRIS Analytics! O tópico deste webinar é dedicado ao Concurso InterSystems IRIS Analytics.
Neste webinar iremos demonstrar o AtScale, o InterSystems Reports (Logi), o IRIS BI, o IRIS NLP e responder as perguntas referentes a como desenvolver, construir e implantar aplicações Analíticas utilizando a plataforma de dados InterSystems IRIS.
Data & Horário: Segunda-feira, 23 de Agosto — 12:00 horário de brasília
Palestrantes:
🗣 @Carmen Logue, Gerente de Produtos InterSystems - Analytics e Inteligência Artificial
🗣 @Evgeny Shvarov, Gerente do Ecossistema para Desenvolvedores InterSystems

Olá Desenvolvedores,
Dêem as boas vindas ao próximo concurso online de programação InterSystems:
🏆 Concurso InterSystems IRIS Analytics 🏆
Duração: 16 de Agosto a 05 de Setembro de 2021
Premiação Total: US$8.750
Página do concurso: https://contest.intersystems.com

Quando temos que prever o valor de um resultado categórico (ou discreto), usamos a regressão logística.Acredito que usamos a regressão linear para também prever o valor de um resultado, dados os valores de entrada.Então, qual é a diferença entre as duas metodologias?
Olá comunidade,
Nesta 4ª parte vamos falar de uma funcionalidade do InterSystems IRIS Reports chamada de “Bursting”. Vamos primeiro relembrar o que já vimos até o momento.
Entendemos o que é o InterSystems IRIS Reports, instalamos os ambientes: Designer e Server, verificamos os diversos tipos e formatos de relatórios que podemos desenvolver, e entendemos como distribuir um relatório em diversos formatos.
Mas afinal o que é o “Bursting”? Antes de demonstrar está funcionalidade em ação, vamos primeiro refletir sobre a sua necessidade.
Todos nós já nos deparamos com necessidade de processar relatórios com milhares de linhas, e este tipo de relatório normalmente tem um alto custo de processamento no banco de dados com milhares de linhas que não são destinadas a um único usuário, você precisa segregar as informações por região, por alguma categoria seja de produto ou um tipo de exame, ou por alguma hierarquia existente para o seu tipo de negócio. Sem o InterSystems IRIS Reports, você precisaria desenvolver uma ou mais queries aplicando técnicas para filtrar dados com as opções de “filtro” que usuário precisa ou pode ter acesso, e podem ocorrer mais de uma execução por diversos usuários ao longo do dia.