Talvez isso já seja bem conhecido, mas quis compartilhar para ajudar.
Considere que você tem as seguintes definições de classes persistentes:
Uma classe Invoice (Fatura) com uma propriedade de referência para Provider (Prestador de serviço):
Um modelo de banco de dados é um tipo de modelo de dados que determina a estrutura lógica de um banco de dados e, fundamentalmente, determina como os dados podem ser armazenados, organizados e manipulados. O exemplo mais popular de um modelo de banco de dados é o modelo relacional, que usa um formato baseado em tabela.
Talvez isso já seja bem conhecido, mas quis compartilhar para ajudar.
Considere que você tem as seguintes definições de classes persistentes:
Uma classe Invoice (Fatura) com uma propriedade de referência para Provider (Prestador de serviço):
A InterSystems está na vanguarda da tecnologia de bancos de dados desde sua criação, sendo pioneira em inovações que consistentemente superam concorrentes como Oracle, IBM e Microsoft. Ao se concentrar em um design de kernel eficiente e adotar uma abordagem intransigente em relação ao desempenho de dados, a InterSystems criou um nicho em aplicações de missão crítica, garantindo confiabilidade, velocidade e escalabilidade.
A História de Excelência Técnica
Interessados entrar em contato no email msantos.ekan@iamspe.sp.gov.br e bsantori.ekan@iamspe.sp.gov.br
No cenário de dados atual, as empresas enfrentam vários desafios diferentes. Um deles é fazer análises sobre uma camada de dados unificada e harmonizada disponível para todos os consumidores. Uma camada que possa oferecer as mesmas respostas às mesmas perguntas, independentemente do dialeto ou da ferramenta usada. A Plataforma de Dados InterSystems IRIS responde a isso com um complemento de Análise Adaptativa que pode fornecer essa camada semântica unificada. Há muitos artigos no DevCommunity sobre como usá-lo por ferramentas de BI. Este artigo abordará como consumi-lo com IA e também como recuperar alguns insights. Vamos ir por etapas...
Você pode facilmente encontrar uma definição [no site developer community] (https://community.intersystems.com/tags/adaptive-analytics) Resumindo, ela pode fornecer dados de forma estruturada e harmonizada para diversas ferramentas de sua escolha para consumo e análise posterior. Ela oferece as mesmas estruturas de dados a várias ferramentas de BI. Mas... Ela também pode oferecer as mesmas estruturas de dados para suas ferramentas de IA/ML!
A Análise Adaptativa tem um componente adicional chamado AI-LINK que constrói essa ponte entre a IA e a BI.
É um componente Python criado para permitir a interação programática com a camada semântica para os fins de otimizar os principais estágios do fluxo de trabalho do aprendizado de máquina (ML) (por exemplo, engenharia de características).
Com o AI-Link, você pode:
Como é uma biblioteca Python, ela pode ser usada em qualquer ambiente Python. Incluindo Notebooks. Neste artigo, darei um exemplo simples de como alcançar a solução de Análise Adaptativa a partir do Jupyter Notebook com a ajuda do AI-Link.
Aqui está o repositório git com o Notebook completo como exemplo: https://github.com/v23ent/aa-hands-on
Para os passos a seguir, presume-se que você concluiu os pré-requisitos:
Primeiro, vamos instalar os componentes necessários em nosso ambiente. Isso baixará alguns pacotes que são necessários para que as próximas etapas funcionem. 'atscale' - nosso pacote principal para a conexão 'prophet' - pacote de que precisaremos para fazer previsões
pip install atscale prophet
Em seguida, precisamos importar as principais classes que representam alguns conceitos importantes da nossa camada semântica. Client - classe que usaremos para estabelecer uma conexão com a Análise Adaptativa; Project - classe para representar projetos dentro da Análise Adaptativa; DataModel - classe que representará nosso cubo virtual;
from atscale.client import Client
from atscale.data_model import DataModel
from atscale.project import Project
from prophet import Prophet
import pandas as pd
Agora, deve estar tudo pronto para estabelecer uma conexão com nossa origem de dados.
client = Client(server='http://adaptive.analytics.server', username='sample')
client.connect()
Vá em frente e especifique os detalhes de conexão da sua instância da Análise Adaptativa. Quando for solicitada a organização, responda na caixa de diálogo e insira sua senha da instância da AtScale.
Com a conexão estabelecida, você precisará selecionar seu projeto da lista de projetos publicados no servidor. Você verá a lista de projetos como um prompt interativo, e a resposta deve ser o ID inteiro do projeto. O modelo de dados será selecionado automaticamente se for o único.
project = client.select_project()
data_model = project.select_data_model()
Há vários métodos preparados pela AtScale na biblioteca de componentes do AI-Link. Eles permitem explorar seu catálogo de dados, consultar dados e até ingerir alguns dados de volta. A documentação da AtScale tem uma vasta referência da API, descrevendo tudo o que está disponível. Primeiro, vamos ver qual é o nosso conjunto de dados ao chamar alguns métodos de "data_model":
data_model.get_features()
data_model.get_all_categorical_feature_names()
data_model.get_all_numeric_feature_names()
A saída será algo assim

Depois de olhar um pouco, podemos consultar os dados em que realmente temos interesse usando o método "get_data". Ele retornará um DataFrame do pandas com os resultados da consulta.
df = data_model.get_data(feature_list = ['Country','Region','m_AmountOfSale_sum'])
df = df.sort_values(by='m_AmountOfSale_sum')
df.head()
Que mostrará seu dataframe:
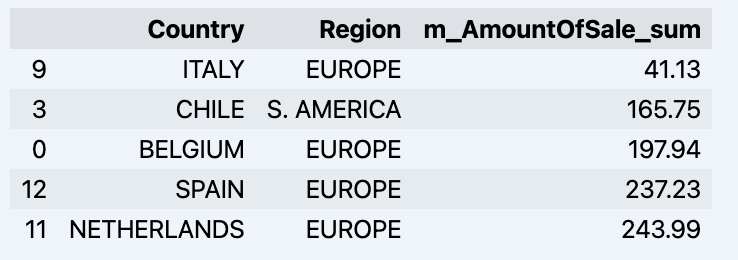
Vamos preparar um conjunto de dados e exibi-lo rapidamente no gráfico
import matplotlib.pyplot as plt
# Estamos pegando as vendas para cada data
dataframe = data_model.get_data(feature_list = ['Date','m_AmountOfSale_sum'])
# Crie um gráfico de linhas
plt.plot(dataframe['Date'], dataframe['m_AmountOfSale_sum'])
# Adicione rótulos e um título
plt.xlabel('Days')
plt.ylabel('Sales')
plt.title('Daily Sales Data')
# Exiba o gráfico
plt.show()
Saída:

A próxima etapa seria obter um valor da ponte do AI-Link - vamos fazer algumas previsões simples!
# Carregue os dados históricos para treinar o modelo
data_train = data_model.get_data(
feature_list = ['Date','m_AmountOfSale_sum'],
filter_less = {'Date':'2021-01-01'}
)
data_test = data_model.get_data(
feature_list = ['Date','m_AmountOfSale_sum'],
filter_greater = {'Date':'2021-01-01'}
)
Obtemos 2 conjuntos de dados diferentes aqui: para treinar e testar nosso modelo.
# Para a ferramenta, escolhemos fazer a previsão "Prophet", em que precisamos especificar 2 colunas: "ds" e "y"
data_train['ds'] = pd.to_datetime(data_train['Date'])
data_train.rename(columns={'m_AmountOfSale_sum': 'y'}, inplace=True)
data_test['ds'] = pd.to_datetime(data_test['Date'])
data_test.rename(columns={'m_AmountOfSale_sum': 'y'}, inplace=True)
# Inicialize e ajuste o modelo Prophet
model = Prophet()
model.fit(data_train)
Em seguida, criamos outro dataframe para acomodar nossa previsão e exibi-la no gráfico
# Crie um dataframe futuro para previsão
future = pd.DataFrame()
future['ds'] = pd.date_range(start='2021-01-01', end='2021-12-31', freq='D')
# Faça previsões
forecast = model.predict(future)
fig = model.plot(forecast)
fig.show()
Saída:

Depois de obter a previsão, podemos colocá-la de volta no armazém de dados e adicionar uma agregação ao nosso modelo semântico para que reflita para outros consumidores. A previsão estaria disponível por qualquer outra ferramenta de BI para usuários empresariais e analistas de BI. A previsão em si será colocada em nosso armazém de dados e armazenada lá.
from atscale.db.connections import Iris
db = Iris(
username,
host,
host,
driver,
schema,
schema,
password=None,
warehouse_id=None
)
data_model.writeback(dbconn=db,
table_name= 'SalesPrediction',
DataFrame = forecast)
data_model.create_aggregate_feature(dataset_name='SalesPrediction',
column_name='SalesForecasted',
name='sum_sales_forecasted',
aggregation_type='SUM')
É isso! Boa sorte com suas previsões!
Olá membros da Comunidade de Desenvolvedores,
Por favor, dêem as boas-vindas ao novo vídeo no YouTube de Desenvolvedores InterSystems:
⏯ Consultas dez vezes mais rápidas com armazenamento em colunas@ Global Summit 2022
A interoperabilidade é um dos assuntos mais discutidos nos últimos anos. Notamos cada vez mais que nossos dados de saúde estão sendo compartilhados entre vários sistemas, com o propósito de trazer para mais próximo o conceito de saúde do paciente em primeiro lugar.
Olá Desenvolvedores!
Aqui estão os bonus tecnológicos para o Concurso de Globais InterSystems 2022 que irão lhes dar pontos extra na votação:
Vejam os detalhes abaixo.
Olá desenvolvedores!
Algumas vezes precisamos inserir ou fazer referência aos dados de classes persistentes diretamente através das globais.
E talvez muitos de vocês estejam esperando que a estrutura de dados da global com os registros seja:
^Sample.Person(Id)=$listbuild("",col1,col,2,...,coln).Este artigo é um aviso que nem sempre isso é verdade. Não espere que sempre seja assim!
Olá Desenvolvedores!
Como você provavelmente percebeu, no IRIS 2021 os nomes das globais são randômicos.
E, se você criar classes do IRIS classes com DDL e quiser se certificar qual global foi criada, você provavelmente gostaria de escolher seu nome.
E, de fato, você consegue fazê-lo.
Utilize WITH %CLASSPARAMETER DEFAULTGLOBAL='^GLobalName' na instrução CREATE Table para fazê-lo. Documentação. Veja o exemplo abaixo:
Fala pessoal, tudo bem?
Espero que todos estejam bem, saudáveis e que tenham um excelente 2022!
Ao longo dos anos, eu trabalhei nos mais diferentes projetos e acabei me deparando com dataset super interessantes.
Mas, na maioria das vezes, os datasets utilizados para o trabalhar eram datasets dos clientes. Quando eu comecei a participar das competições nos últimos anos, eu comecei a vasculhar na web por datasets que eu possa chamar de meu 😄
Eu acabei coletando alguns dados, mas eu estava pensando, "Esses datasets são o suficiente para ajudar as outras pessoas?"
Então, trocando ideias com o @José Pereira para essa competição, nós decidimos por uma abordagem utilizando uma perspectiva diferente.
Nós pensamos em oferecer uma variedade de datasets de qualquer espécie de 2 fonte de dados famosas. Dessa forma, nós podemos empoderar vocês para encontrarem e instalarem o dataset desejado de uma forma rápido, fácil e indolor.
Socrata Open Data API permite que você de forma programática possa acessar uma variedade de dados abertos de governos, organizações sem fins lucrativos e ONGs de todo o mundo.
Para esse release inicial, nós estamos usando as APIs Socrata para pesquisar e fazer download de um dataset específico.
Pode utilizar a ferramenta para API da sua preferência Postman, Hoppscotch
GET> https://api.us.socrata.com/api/catalog/v1?only=dataset&q=healthcare
This endpoint will return all healthcare related datasets, like the image below:
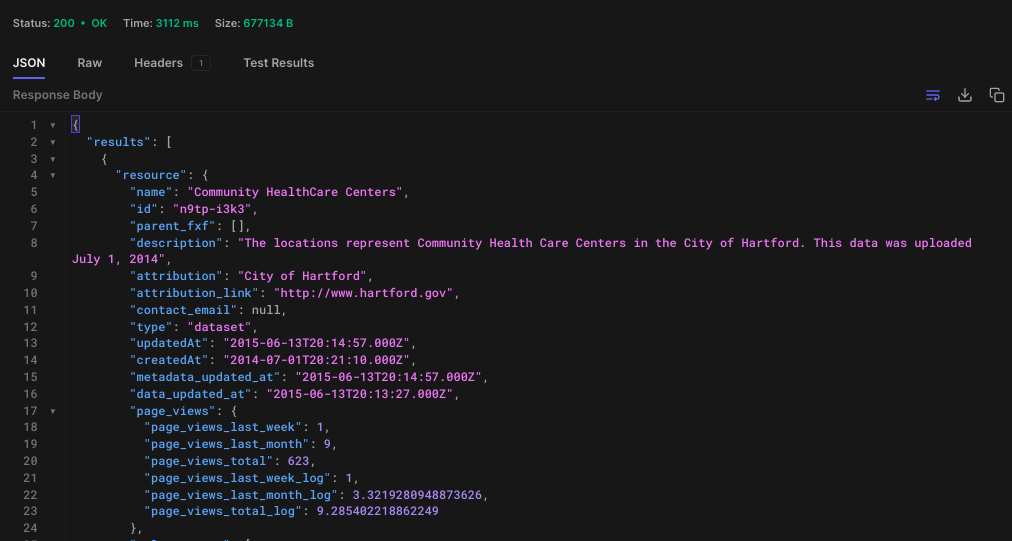
Agora, basta pegar o ID. Neste caso o ID é: "n9tp-i3k3"
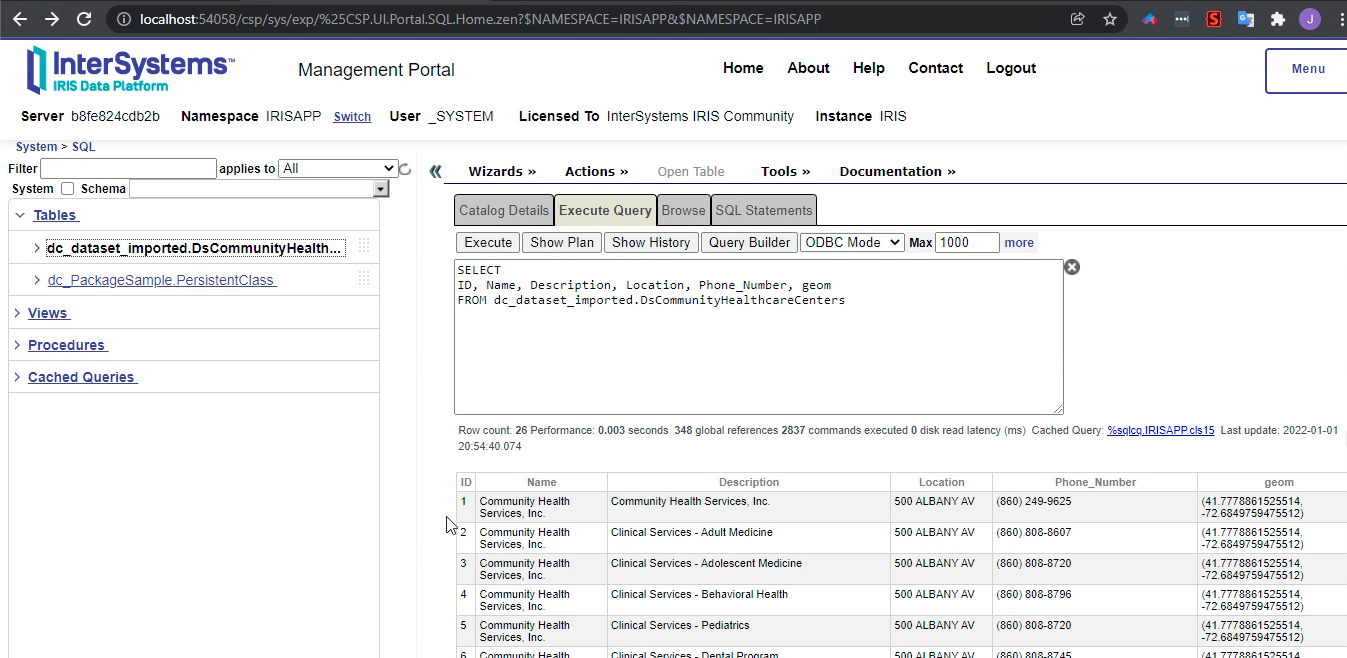
Vamos para o terminal
IRISAPP>set api = ##class(dc.dataset.importer.service.socrata.SocrataApi).%New()
IRISAPP>do api.InstallDataset({"datasetId": "n9tp-i3k3", "verbose":true})
Compilation started on 01/07/2022 01:01:28 with qualifiers 'cuk'
Compiling class dc.dataset.imported.DsCommunityHealthcareCenters
Compiling table dc_dataset_imported.DsCommunityHealthcareCenters
Compiling routine dc.dataset.imported.DsCommunityHealthcareCenters.1
Compilation finished successfully in 0.108s.
Class name: dc.dataset.imported.DsCommunityHealthcareCenters
Header: Name VARCHAR(250),Description VARCHAR(250),Location VARCHAR(250),Phone_Number VARCHAR(250),geom VARCHAR(250)
Records imported: 26
Depois do comando acima, você pode conferir o seu dataset prontinho para uso!
Kaggle, uma subsidiária do Google LLC, é uma comunidade online de cientistas de dados e profissionais de aprendizado de máquina. O Kaggle permite que os usuários encontrem e publiquem conjuntos de dados, explorem e construam modelos em um ambiente de ciência de dados baseado na Web, trabalhem com outros cientistas de dados e engenheiros de aprendizado de máquina e participem de competições para resolver desafios de ciência de dados.
Em junho de 2017, Kaggle anunciou que ultrapassou 1 milhão de usuários registrados, ou Kagglers, e em 2021 tem mais de 8 milhões de usuários registrados. A comunidade abrange 194 países. É uma comunidade diversificada, desde aqueles que estão começando até muitos dos pesquisadores mais conhecidos do mundo.
Comunidade pequenininha hein!? 😂
Para usar os conjuntos de dados do Kaggle, você precisa se registrar no site. Depois disso, você precisa criar um token para usar a API do Kaggle.
Agora, da mesma forma que fizemos com o Socrata, você pode utilizar a API para fazer a pesquisa e download do dataset.
GET> https://www.kaggle.com/api/v1/datasets/list?search=appointments
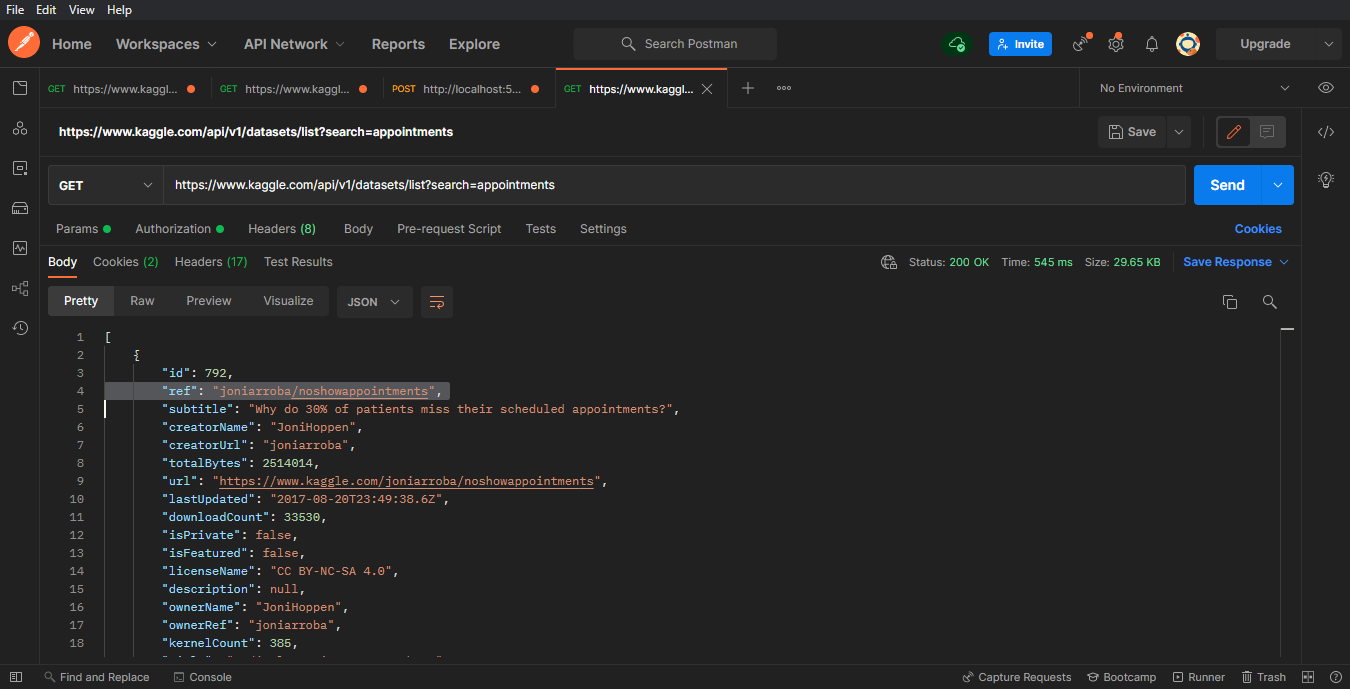
No Kaggle, ao invés de id utilizaremos o ref. Nesse exemplo o valor de ref é: "joniarroba/noshowappointments"
Os parâmetros abaixo "your-username", e "your-password" são parâmetros que o Kaggle fornece quando você cria o token para API.
IRISAPP>Set crendtials = ##class(dc.dataset.importer.service.CredentialsService).%New()
IRISAPP>Do crendtials.SaveCredentials("kaggle", "<your-username>", "<your-password>")
IRISAPP>Set api = ##class(dc.dataset.importer.service.kaggle.KaggleApi).%New()
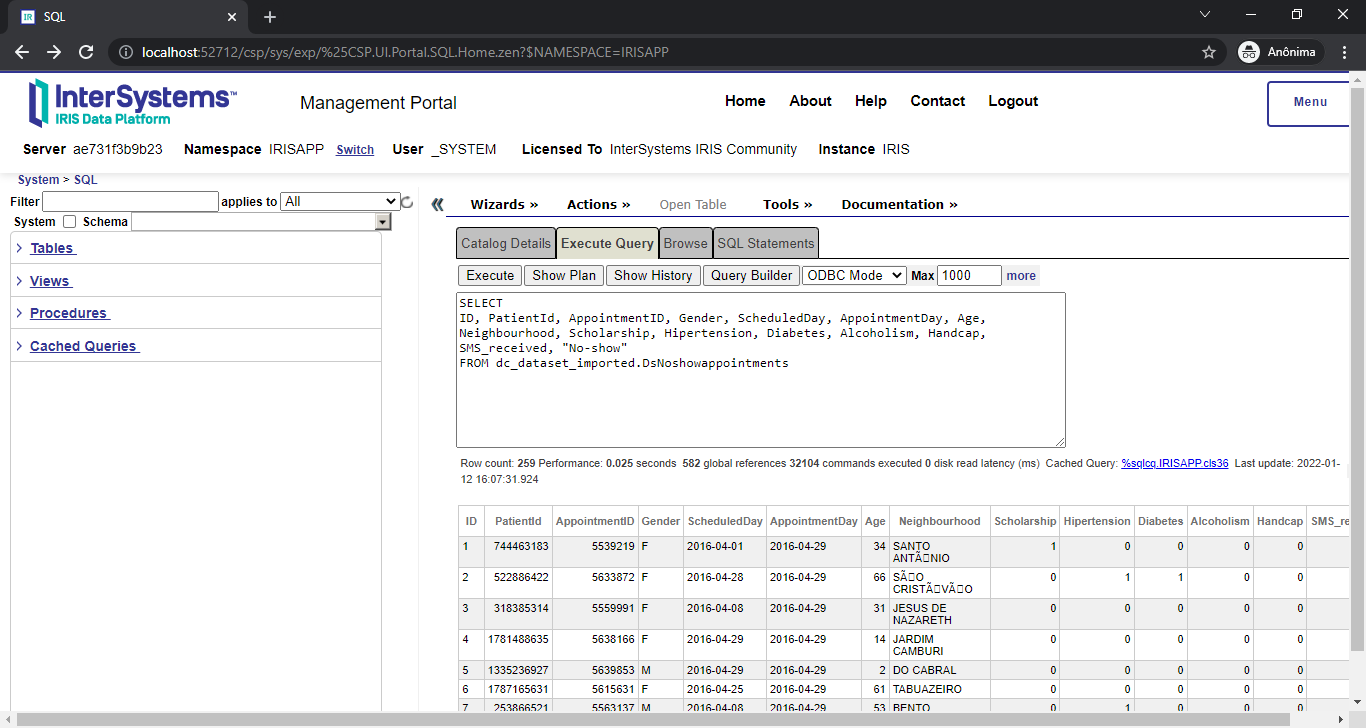
IRISAPP>Do api.InstallDataset({"datasetId":"joniarroba/noshowappointments", "credentials":"kaggle", "verbose":true})
Class name: dc.dataset.imported.DsNoshowappointments
Header: PatientId INTEGER,AppointmentID INTEGER,Gender VARCHAR(250),ScheduledDay DATE,AppointmentDay DATE,Age INTEGER,Neighbourhood VARCHAR(250),Scholarship INTEGER,Hipertension INTEGER,Diabetes INTEGER,Alcoholism INTEGER,Handcap INTEGER,SMS_received INTEGER,No-show VARCHAR(250)
Records imported: 259
Pronto! Mais um dataset prontinho para uso
Para facilitar as coisas, estamos oferecendo uma interface gráfica para instalar o dataset. Mas isso é algo que quero falar em nosso próximo artigo. Enquanto isso, você pode conferir uma prévia abaixo enquanto estamos dando aquele talento, antes do lançamento oficial:

Se você está se perguntando como é fazer o download de um dataset grande, da uma olhada nesse video mostrando como é.... Agora... se +400.000 registros não forem o suficiente, que tal 1 MILHÃO DE REGISTROS?! Assista!
<iframe width="560" height="315" src="https://www.youtube.com/embed/0T8wXRsaJso" title="YouTube video player" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture" allowfullscreen></iframe>Se você curtiu o app, por favor vote em iris-kaggle-socrata-generator!
Bom dia!!!
Vaga Especialista de Integrações.
AFIP - Associação Fundo de Incentivo à Pesquisa.
Requisitos
* Conhecimentos avançado em Ensemble/Caché
* Integração com bancos Oracle /SQL Server
Será um diferencial ter atuação na área da saúde sistemas (LIS/HIS/RIS). Profissional deve atuar como líder técnico.
- Documentar estrutura dos sistemas;
- Participar de Reuniões técnicas com fornecedores/colaboradores;
- Responsável técnico pela arquitetura de integrações entre sistemas;
- Responsável pela homologação de sistemas de terceiros;
- Responsável por manter catálogo de serviços de integração de dado;
Se você precisar escrever a Arquitetura de Dados de sua organização e mapear para o IRIS da InterSystems, considere o seguinte Diagrama de Arquitetura de Dados e referências à documentação da íris entre sistemas, consulte: