O Google Cloud Platform (GCP) fornece um ambiente rico em recursos para Infraestrutura como um Serviço (IaaS) como uma oferta em nuvem totalmente capaz de oferecer suporte a todos os produtos da InterSystems, incluindo a mais recente plataforma de dados InterSystems IRIS . Deve-se ter cuidado, como com qualquer plataforma ou modelo de implantação, para garantir que todos os aspectos de um ambiente sejam considerados, como desempenho, disponibilidade, operações e procedimentos de gerenciamento. As especificidades de cada uma dessas áreas serão abordadas neste artigo.
A visão geral e os detalhes abaixo são fornecidos pelo Google e estão disponíveis aqui.
Visão geral
Recursos do GCP
O GCP é composto por um conjunto de ativos físicos, como computadores e unidades de disco rígido, e também recursos virtuais, como máquinas virtuais (VMs), nos centros de dados do Google em todo o mundo. Cada centro de dados está em uma região do mundo. Cada região é uma coleção de zonas, isoladas de cada uma dentro da região. Cada zona é identificada por um nome que combina uma letra identificadora com o nome da região.
Essa distribuição de recursos tem várias vantagens, incluindo redundância em caso de falha e latência reduzida colocando recursos mais perto dos clientes. Essa distribuição também tem algumas regras quanto a como os recursos podem ser usados conjuntamente.
Acesso aos recursos do GCP
Na computação em nuvem, o hardware físico e o software se tornam serviços. Esses serviços oferecem acesso aos recursos adjacentes. Ao implantar sua aplicação baseada em InterSytems IRIS no GCP, você combina esses serviços para obter a infraestrutura necessária e depois adiciona seu código para possibilitar a concretização dos cenários que deseja criar. Os detalhes dos recursos disponíveis estão disponíveis aqui.
Projetos
Todos os recursos do GCP que você aloca e usa devem pertencer a um projeto. Um projeto é composto por configurações, permissões e outros metadados que descrevem suas aplicações. Os recursos em um único projeto podem funcionar juntos facilmente, por exemplo, comunicando-se por uma rede interna, sujeita a regras das regiões e zonas. Os recursos que cada projeto contêm permanecem separados por fronteiras de projetos. Você só pode interconectá-los por uma conexão de rede externa.
Interação com os serviços
O GCP oferece três formas básicas de interagir com os serviços e recursos.
Console
O Google Cloud Platform Console possui uma interface gráfica web do usuário que você pode usar para gerenciar os projetos e recursos do GCP. No GCP Console, você pode criar um novo projeto ou escolher um existente, e usar os recursos criados no contexto desse projeto. É possível criar diversos projetos, então você pode usá-los para segregar o trabalho da melhor maneira de acordo com suas necessidades. Por exemplo, você pode iniciar um novo projeto se quiser garantir que somente determinados membros da equipe consigam acessar recursos nesse projeto, enquanto todos os membros da equipe podem continuar acessando os recursos em outro projeto.
Interface de linha de comandos
Se você preferir trabalhar em uma janela de terminal, o Google Cloud SDK oferece a ferramenta de linha de comandos gcloud, que permite acesso aos comandos de que você precisa. A ferramenta gcloud pode ser usada para gerenciar o fluxo de trabalho de desenvolvimento e os recursos do GCP. Os detalhes de referências sobre o gcloud estão disponíveis aqui.
O GCP também oferece o Cloud Shell, um ambiente de shell interativo no navegador para o GCP. Você pode acessar o Cloud Shell pelo GCP Console. O Cloud Shell oferece:
Uma instância temporária de máquina virtual de mecanismo de computação.Acesso de linha de comando à instância por um navegador.Um editor de código integrado.5 GB de armazenamento em disco persistente.Google Cloud SDK e outras ferramentas pré-instalados.Suporte às linguagens Java, Go, Python, Node.js, PHP, Ruby e .NET.Funcionalidade de visualização da web.Autorização integrada para acesso aos projetos e recursos no GCP Console.Bibliotecas de cliente
O Cloud SDK inclui bibliotecas de cliente que permitem criar e gerenciar recursos com facilidade. As bibliotecas de cliente expõem APIs para dois propósitos principais:
- As APIs de aplicações concedem acesso aos serviços. As APIs de aplicações são otimizadas para as linguagens compatíveis, como Node.js e Python. As bibliotecas foram desenvolvidas com metáforas de serviço, então você pode usar os serviços de modo mais natural e escrever menos código boilerplate. As bibliotecas também oferecem elementos auxiliares para autenticação e autorização. Os detalhes estão disponíveis aqui.
- As APIs de administração oferecem funcionalidades de gerenciamento de recursos. Por exemplo, você pode usar as APIs de administração se quiser criar suas próprias ferramentas automatizadas.
Também é possível usar as bibliotecas de cliente da API do Google para acessar APIs de produtos, como Google Maps, Google Drive e YouTube. Os detalhes das bibliotecas de cliente do GCP estão disponíveis aqui.
Exemplos de arquitetura da InterSystems IRIS
Neste artigo, são fornecidos exemplos de implantações da InterSystems IRIS para GCP como ponto de partida para a implantação específica de sua aplicação. Eles podem ser usados como diretrizes para diversas possibilidades de implantação. Esta arquitetura de referência demonstra opções de implantação muito robustas, começando com implantações de pequeno porte até cargas de trabalho extremamente escaláveis para os requisitos de computação e dados.
Também são abordadas neste documento opções de alta disponibilidade e recuperação de desastres, junto com outras operações de sistema recomendadas. Espera-se que elas sejam modificadas pelos técnicos para se adequarem às práticas e políticas de segurança padrão da organização.
A InterSystems está disponível para conversar ou responder a perguntas sobre as implantações da InterSystems IRIS com GCP para sua aplicação específica.
Exemplos de arquitetura de referência
Os seguintes exemplos de arquitetura apresentam diversas configurações diferentes, com capacidade e funcionalidades cada vez maiores. Considere estes exemplos de implantação de pequeno porte / produção / produção de grande porte / produção com cluster fragmentado que mostram a progressão desde uma configuração pequena modesta para desenvolvimento até soluções extremamente escaláveis com alta disponibilidade entre zonas e recuperação de desastres multirregião. Além disso, é fornecido um exemplo de arquitetura usando as novas funcionalidades de fragmentação da InterSystems IRIS Data Plataform para cargas de trabalho híbridas com processamento de consulta SQL altamente paralelizado.
Configuração de implantação de pequeno porte
Neste exemplo, é usada uma configuração mínima para ilustrar um ambiente de desenvolvimento de pequeno porte que suporta até 10 desenvolvedores e 100 GB de dados. É fácil dar suporte a mais desenvolvedores e dados: basta alterar o tipo de instância da máquina virtual e aumentar o armazenamento dos discos persistentes conforme necessário.
Esta configuração é adequada para ambientes de desenvolvimento e para se familiarizar com a funcionalidade da InterSystems IRIS junto com construção de contêineres e orquestração do Docker, se desejar. Em geral, não se usam alta disponibilidade e espelhamento de bancos de dados em configurações de pequeno porte, mas essas funcionalidades podem ser adicionadas a qualquer momento, se for necessário prover alta disponibilidade.
Diagrama do exemplo de configuração de pequeno porte
O diagrama de exemplo abaixo na Figura 2.1.1-a ilustra a tabela de recursos na Figura 2.1.1-b. Os gateways incluídos são apenas exemplos e podem ser ajustados para se adequarem às práticas de rede padrão de sua organização.
.png)
Os seguintes recursos do projeto GCP VPC são provisionados com uma configuração mínima de pequeno porte. Podem ser adicionados ou removidos recursos do GCP conforme necessário.
Recursos do GCP para configuração de pequeno porte
Um exemplo de recursos do GCP para uma configuração de pequeno porte é fornecido na tabela abaixo.
.png)
É preciso considerar segurança de rede e regras de firewall adequadas para evitar o acesso não autorizado ao VPC. O Google desenvolveu melhores práticas de segurança de rede para dar os primeiros passos, disponíveis aqui.
Nota: as instâncias de máquina virtual precisam de um endereço IP público para estabelecerem conexão com os serviços do GCP. Embora esta prática possa suscitar preocupações, o Google recomenda usar regras de firewall para limitar o tráfego de entrada a essas instâncias de máquina virtual.
Caso sua política de segurança exija instâncias de máquina virtual verdadeiramente internas, você precisará configurar um proxy NAT manualmente em sua rede e uma rota correspondente para que as instâncias internas consigam estabelecer conexão com a Internet. É importante salientar que não é possível estabelecer conexão a uma instância de máquina virtual verdadeiramente interna diretamente usando-se SSH. Para estabelecer conexão a essas máquinas internas, você precisa configurar uma instância de bastion que tenha um endereço IP externo para usá-la como um túnel. É possível provisionar um host bastion para fornecer um ponto de entrada externo ao seu VPC.
Os detalhes dos hosts bastion estão disponíveis aqui.
Configuração de produção
Neste exemplo, temos uma configuração de maior porte como exemplo de configuração de produção que incorpora a funcionalidade de espelhamento de bancos de dados da InterSystems IRIS para fornecer alta disponibilidade e recuperação de desastres.
Está incluído nesta configuração um par de espelhos assíncronos dos servidores de banco de dados da InterSystems IRIS, divididos entre duas zonas dentro da região 1 para failover automático, e um terceiro membro espelho DR assíncrono na região 2 para recuperação de desastres no caso improvável de uma região GCP inteira ficar offline.
O servidor Arbiter e ICM da InterSystems é implantado em uma terceira zona separada para oferecer maior resiliência. O exemplo de arquitetura também inclui um conjunto de servidores web com balanceamento de carga opcionais para dar suporte a aplicações web. Esses servidores web com o InterSystems Gateway podem ser escaláveis de maneira independente, conforme necessário.
Diagrama do exemplo de configuração de produção
O diagrama de exemplo abaixo na Figura 2.2.1-a ilustra a tabela de recursos exibida na Figura 2.2.1-b. Os gateways incluídos são apenas exemplos e podem ser ajustados para se adequarem às práticas de rede padrão de sua organização.
.png)
Os seguintes recursos do GCP VPC Project são o mínimo recomendado para dar suporte a um cluster fragmentado. Podem ser adicionados ou removidos recursos do GCP conforme necessário.
Recursos do GCP configuração de produção
Um exemplo de recursos do GCP uma configuração de produção é fornecido nas tabelas abaixo.
.png)

Configuração de produção de grande porte
Neste exemplo, é fornecida uma configuração extremamente escalável expandindo-se a funcionalidade da InterSystems IRIS para fornecer servidores de aplicação usando-se o Enterprise Cache Protocol (ECP) da InterSystems para oferecer uma enorme escalabilidade horizontal de usuários. Neste exemplo, é incluído um nível ainda maior de disponibilidade, pois os clientes ECP preservam os detalhes de sessões mesmo caso haja failover da instância do banco de dados. São usadas diversas zonas GCP, com servidores de aplicação baseados em ECP e membros espelho de bancos de dados implantados em várias regiões. Esta configuração oferece suporte a dezenas de milhões de acessos ao banco de dados por segundo e a diversos terabytes de dados.
Diagrama do exemplo de configuração de produção de grande porte
O diagrama de exemplo na Figura 2.3.1-a ilustra a tabela de recursos na Figura 2.3.1-b. Os gateways incluídos são apenas exemplos e podem ser ajustados para se adequarem às práticas de rede padrão de sua organização.
Estão incluídos nesta configuração um par de espelhos de failover, quatro ou mais clientes ECP (servidores de aplicação) e um ou mais servidores web por servidor de aplicação. Os pares de espelhos de bancos de dados para failover são divididos entre duas zonas GCP diferentes na mesma região para proteção com domínio de falha, com o servidor Arbiter e ICM da InterSystems implantado em uma terceira zona para oferecer maior resiliência.
A recuperação de desastres se estende para uma segunda região e zona(s) GCP similar ao exemplo anterior. Podem ser usadas diversas regiões de recuperação de desastres com vários membros espelho DR assíncronos, se desejar.

Os seguintes recursos do GCP VPC Project são o mínimo recomendado para dar suporte a uma implantação em produção de grande escala. Podem ser adicionados ou removidos recursos do GCP conforme necessário.
Recursos do GCP para configuração de produção de grande porte
Um exemplo de recursos do GCP para uma configuração de produção de grande porte é fornecido nas tabelas abaixo.



Configuração de produção com cluster fragmentado da InterSystems IRIS
Neste exemplo, é fornecida uma configuração com escalabilidade horizontal para cargas de trabalho híbridas com SQL, incluindo-se os novos recursos de cluster fragmentado da InterSystems IRIS para fornecer uma enorme escalabilidade horizontal de consultas e tabelas SQL entre diversos sistemas. Os detalhes do cluster fragmentado da InterSystems IRIS e suas funcionalidades são abordados com mais detalhes posteriormente neste artigo.
Configuração de produção com cluster fragmentado da InterSystems IRIS
O diagrama de exemplo na Figura 2.4.1-a ilustra a tabela de recursos na Figura 2.4.1-b. Os gateways incluídos são apenas exemplos e podem ser ajustados para se adequarem às práticas de rede padrão de sua organização.
Estão incluídos nesta configuração quatro pares de espelhos como nós de dados. Cada um dos pares de espelhos de bancos de dados para failover é dividido entre duas zonas GCP diferentes na mesma região para proteção com domínio de falha, com o servidor Arbiter e ICM da InterSystems implantado em uma terceira zona para oferecer maior resiliência.
Esta configuração permite que todos os métodos de acesso ao banco de dados fiquem disponíveis a partir de qualquer nó de dados do cluster. Os dados das tabelas SQL grandes são particionados fisicamente em todos os nós de dados para permitir enorme paralelização de processamento de consultas e volume de dados. A combinação de todas essas funcionalidades permite o suporte a cargas de trabalho híbridas complexas, como consultas analíticas SQL de grande escala com ingestão simultânea de novos dados, tudo com uma única InterSystems IRIS Data Platform.

No diagrama acima e na coluna "tipo do recurso" na tabela abaixo, "Compute [Engine] (Computação [Mecanismo])" é um termo do GCP que representa uma instância de servidor GCP (virtual), conforme descrito com mais detalhes na seção 3.1 deste documento. Ele não representa nem sugere o uso de "nós de computação" na arquitetura de cluster descrita posteriormente neste artigo.
Os seguintes recursos do GCP VPC Project são o mínimo recomendado para dar suporte a um cluster fragmentado. Podem ser adicionados ou removidos recursos do GCP conforme necessário.
Recursos do GCP para configuração de produção com cluster fragmentado
Um exemplo de recursos do GCP para uma configuração de cluster fragmentado é fornecido na tabela abaixo.

Introdução aos conceitos de nuvem
O Google Cloud Platform (GCP) fornece um ambiente em nuvem repleto de recursos para infraestrutura como serviço (IaaS) totalmente capaz de dar suporte a todos os produtos da InterSystems, incluindo ao DevOps baseado em contêiner com a nova InterSystems IRIS Data Platform. Deve-se ter cuidado, assim como em qualquer plataforma ou modelo de implantação, para garantir que todos os aspectos de um ambiente sejam considerados, como desempenho, disponibilidade, operações de sistema, alta disponibilidade, recuperação de desastres, controles de segurança e outros procedimentos de gerenciamento. Este documento aborda os três principais componentes de todas as implantações em nuvem: Computação, Armazenamento e Rede.
Mecanismos de computação (máquinas virtuais)
No GCP, há diversas opções disponíveis para recursos de mecanismo de computação, com várias especificações de CPU e memória virtuais e das opções de armazenamento. Um item importante sobre o GCP: referências ao número de vCPUs em um determinado tipo de máquina é igual a um vCPU em um hyper-thread no host físico na camada do hypervisor.
Neste documento, os tipos de instância n1-standard* e n1-highmem* serão usados e estão amplamente disponíveis na maioria das regiões de implantação do GCP. Porém, o uso dos tipos de instância n1-ultramem* é uma excelente opção para conjuntos de dados muito grandes, pois são mantidas enormes quantidades de dados em cache na memória. As configurações padrão da instância, como a Política de disponibilidade da instância ou outros recursos avançados, são usadas, salvo indicação em contrário. Os detalhes dos vários tipos de máquina estão disponíveis aqui.
Armazenamento em disco
O tipo de armazenamento relacionado mais diretamente com os produtos da InterSystems são os tipos de disco persistente. Porém, o armazenamento local pode ser usado para altos níveis de desempenho, desde que as restrições de disponibilidade de dados sejam entendidas e atendidas. Existem várias outras opções, como armazenamento em nuvem (buckets). Porém, elas são mais específicas para os requisitos de cada aplicação, em vez de darem suporte à operação da InterSystems IRIS Data Platform.
Como vários outros provedores de nuvem, o GCP impõe limites da quantidade de armazenamento persistente que pode ser associado a um mecanismo de computação específico. Esses limites incluem o tamanho máximo de cada disco, o número de discos persistentes conectados a cada mecanismo de computação e a quantidade de IOPS por disco persistente com um limite geral de IOPS da instância específica do mecanismo de computação. Além disso, há limites de IOPS impostos por GB de espaço em disco. Então, às vezes é necessário provisionar mais capacidade de disco para alcançar a taxa de IOPS desejada.
Esses limites podem variar ao longo do tempo e devem ser confirmados com o Google conforme necessário.
Existem dois tipos de armazenamento persistente para volumes de disco: discos padrão persistentes e discos SSD persistentes. Os discos SSD persistentes são mais adequados para cargas de trabalho de produção que exigem um IOPS de baixa latência previsível e uma maior taxa de transferência. Os discos padrão persistentes são uma opção mais acessível para ambientes de desenvolvimento e teste ou para cargas de trabalho de arquivamento.
Os detalhes dos vários tipos de disco e limitações estão disponíveis aqui.
Rede do VPC
A rede Virtual Private Cloud (VPC) é recomendável para dar suporte aos diversos componentes da InterSystems IRIS Data Platform e também para fornecer controles de segurança de rede adequados, vários gateways, roteamento, atribuições de endereço IP interno, isolamento de interface de rede e controles de acesso. Um exemplo de VPC será detalhado nos exemplos apresentados neste documento.
Os detalhes de rede e firewall do VPC estão disponíveis aqui.
Visão geral do Virtual Private Cloud (VPC)
Os VPCs do GCP são um pouco diferentes dos de outros provedores de nuvem e oferecem maior simplicidade e flexibilidade. Uma comparação dos conceitos está disponível aqui.
São permitidos diversos VPCs por projeto do GCP (atualmente, 5 por projeto, no máximo), e existem duas opções para criar uma rede no VPC: modo automático e modo personalizado.
Os detalhes de cada tipo estão disponíveis aqui.
Na maioria das implantações em nuvem de grande porte, vários VPCs são provisionados para isolar os diversos tipos de gateways dos VPCs para aplicações e para aproveitar o emparelhamento de VPCs para comunicações de entrada e saída. Recomendamos consultar seu administrador de rede para verificar detalhes das subredes permitidas e qualquer regra de firewall de sua organização. O emparelhamento de VPCs não é abordado neste documento.
Nos exemplos fornecidos neste documento, um único VPC com três subredes será usado para fornecer isolamento de rede dos vários componentes e para se ter uma latência e largura de banda previsíveis, além de isolamento de segurança dos diversos componentes da InterSystems IRIS.
Definições de subrede e gateway de rede
São fornecidos dois gateways no exemplo deste documento para dar suporte a conectividade via Internet e VPN segura. Cada acesso de entrada precisa ter regras de firewall e roteamento corretas para fornecer segurança adequada à aplicação. Os detalhes de como usar rotas estão disponíveis aqui.
São usadas três subredes nos exemplos de arquitetura fornecidos, exclusivas para uso com a InterSystems IRIS Data Platform. O uso dessas subredes e interfaces de rede separadas permite maior flexibilidade dos controles de segurança e proteção da largura de banda, além do monitoramento de cada um dos três principais componentes acima. Os detalhes dos vários casos de uso estão disponíveis aqui.
Os detalhes da criação de instâncias de máquina virtual com várias interfaces de rede estão disponíveis aqui.
Subredes incluídas nestes exemplos:
Rede do Espaço do Usuáriopara consultas e usuários conectados de entradaRede Fragmentadapara comunicações interfragmentos entre os nós fragmentadosRede de Espelhamentopara alta disponibilidade usando replicação assíncrona e failover automático de nós de dados individuais. Nota:: o espelhamento síncrono de bancos de dados para failover só é recomendado entre diversas zonas com interconexões de baixa latência em uma única região GCP. Geralmente, a latência entre as regiões é alta demais para fornecer uma boa experiência do usuário, principalmente para implantações com altas taxas de atualização.
Balanceadores de carga internos
A maioria dos servidores de nuvem IaaS não tem a capacidade de fornecer um endereço IP virtual (VIP), geralmente usado nos projetos com failover automático de bancos de dados. Para tratar esse problema, vários dos métodos de conectividade usados com mais frequência, especificamente clientes ECP e gateways web, são aprimorados na InterSystems IRIS para não depender da funcionalidade de VIP, tornando-os cientes do espelhamento e automáticos.
Métodos de conectividade como xDBC, sockets TCP-IP diretos ou outros protocolos de conexão direta exigem o uso de endereços tipo VIP. Para dar suporte a esses protocolos de entrada, a tecnologia de espelhamento de bancos de dados da InterSystems possibilita o failover automático para esses métodos de conectividade no GCP, usando uma página de status de verificação de integridade chamada <span class="Characteritalic" style="font-style:italic">mirror_status.cxw </span> para interagir com o balanceador de carga para conseguir funcionalidade parecida com a do VIP do balanceador de carga, encaminhando o tráfego somente para o membro espelho primário ativo e, portanto, fornecendo um projeto de alta disponibilidade completo e robusto no GCP.
.png)
Os detalhes de como usar um balanceador de carga para fornecer funcionalidade parecida com a do VIP estão disponíveis aqui.
Exemplo de topologia do VPC
Combinando todos os componentes, a ilustração da Figura 4.3-a abaixo demonstra o layout de um VPC com as seguintes características:
Usa várias zonas dentro de uma região para fornecer alta disponibilidadeFornece duas regiões para recuperação de desastresUsa subredes múltiplas para segregação da redeInclui gateways separados para conectividade via Internet e conectividade via VPNUsa um balanceador de carga em nuvem para failover de IP para membros espelho
Visão geral do armazenamento persistente
Conforme abordado na introdução, recomenda-se o uso dos discos persistentes do GCP, especificamente os tipos de disco SSD persistente. Recomendam-se os discos SSD persistentes devido a taxas IOPS de leitura e gravação maiores, além da baixa latência necessária para cargas de trabalho de bancos de dados transacionais e analíticos. Podem ser usadas SSDs locais em determinadas circunstâncias, mas é importante salientar que os ganhos de desempenho das SSDs locais são obtidos ao custo de disponibilidade, durabilidade e flexibilidade.
Os detalhes de persistência de dados em SSDs locais estão disponíveis aqui para entender quando os dados de SSDs locais são preservados e quando não são.
LVM Striping
Como outros fornecedores de nuvem, o GCP impõe diversos limites no armazenamento, em termos de IOPS, espaço de armazenamento e número de dispositivos por instância de máquina virtual. Consulte a documentação do GCP para conferir os limites atuais aqui.
Com esses limites, o LVM stripping se torna necessário para maximizar o IOPS para além de um único dispositivo de disco para uma instância de banco de dados. No exemplo das instâncias de máquina virtual fornecido, recomendam-se os seguintes layouts de disco. Os limites de desempenho relativos aos discos de SSD persistentes estão disponíveis aqui.
Nota: atualmente, há um limite máximo de 16 discos persistentes por instância de máquina virtual, embora o GCP tenha informado que, atualmente, um aumento para 128 está em fase beta, o que será uma melhoria muito bem-vinda.

Com o LVM stripping, é possível espalhar cargas de trabalho de E/S aleatórias para mais dispositivos de disco e herdar filhas de discos. Veja abaixo um exemplo de como usar o LVM stripping com o Linux para o grupo de volumes do banco de dados. Este exemplo usa quatro discos em um LVM PE stripe com uma tamanho de extensão física (PE) de 4 MB. Também é possível usar tamanhos de PE maiores, se necessário.
- Passo 1: Criar os discos padrão ou discos SSD persistentes conforme necessário
- Etapa 2: O agendador de E/S é o NOOP para cada dispositivo de disco, usando-se "lsblk -do NAME,SCHED"
- Etapa 3: Identificar os dispositivos de disco usando "lsblk -do KNAME,TYPE,SIZE,MODEL"
- Etapa 4: Criar o grupo de volumes com novos dispositivos de disco
- vgcreate s 4M
- exemplo: vgcreate -s 4M vg_iris_db /dev/sd[h-k]
- Etapa 4: Criar volume lógico
- lvcreate n -L -i -I 4MB
- exemplo: lvcreate -n lv_irisdb01 -L 1000G -i 4 -I 4M vg_iris_db
- Etapa 5: Criar sistema de arquivo
- mkfs.xfs K
- exemplo: mkfs.xfs -K /dev/vg_iris_db/lv_irisdb01
- Etapa 6: Montar sistema de arquivo
- edit /etc/fstab com as seguintes entradas de montagem
- /dev/mapper/vg_iris_db-lv_irisdb01 /vol-iris/db xfs defaults 0 0
- mount /vol-iris/db
Usando a tabela acima, cada servidor da InterSystems IRIS terá a seguinte configuração com dois discos para SYS (sistema), quatro discos para DB (banco de dados), dois discos para registros de log primários e dois discos para registros de log alternativos.

Para escalabilidade, o LVM permite a expansão de dispositivos e volumes lógicos quando necessário sem interrupções. Consulte as melhores práticas de gerenciamento constante e expansão de volumes LVM na documentação do Linux.
Nota: a ativação de E/S assíncrona para o banco de dados e os arquivos de registros de log de imagem de gravação são altamente recomendáveis. Consulte os detalhes de ativação no Linux no seguinte artigo da comunidade: https://community.intersystems.com/post/lvm-pe-striping-maximize-hyper-converged-storage-throughput
Provisionamento
O InterSystems Cloud Manager (ICM) é uma novidade da InterSystems IRIS. O ICM realiza muitas tarefas e oferece diversas opções para provisionamento da InterSystems IRIS Data Platform. O ICM é fornecido como uma imagem do Docker que inclui tudo que é necessário para provisionar uma solução em nuvem do GCP robusta.
Atualmente, o ICM dá suporte ao provisionamento nas seguintes plataformas:
- Google Cloud Platform (GCP)
- Amazon Web Services, incluindo GovCloud (AWS / GovCloud)
- Microsoft Azure Resource Manager, incluindo Government (ARM / MAG)
- VMware vSphere (ESXi)
O ICM e o Docker podem ser executados em uma estação de trabalho desktop/notebook ou em um servidor de "provisionamento" simples, exclusivo e centralizado com um repositório centralizado.
A função do ICM no ciclo de vida da aplicação é Definir -> Provisionar -> Implantar -> Gerenciar
Os detalhes de instalação e uso do ICM com o Docker estão disponíveis aqui.
NOTA: o uso do ICM não é obrigatório para implantações em nuvem. O método tradicional de instalação e implantação com distribuições tarball é totalmente compatível e disponível. Porém, o ICM é recomendado para facilidade de provisionamento e gerenciamento em implantações em nuvem.
Monitoramento de contêiner
O ICM inclui um recurso de monitoramento básico usando Weave Scope para implantação baseada em contêiner. Ela não é implantada por padrão e precisa ser especificada no campo Monitor do arquivo de padrões.
Os detalhes de monitoramento, orquestração e agendamento com o ICM estão disponíveis aqui.
Uma visão geral e documentação do Weave Scope estão disponíveis aqui.
Alta disponibilidade
O espelhamento de bancos de dados da InterSystems proporciona o mais alto nível de disponibilidade em qualquer ambiente de nuvem. Existem opções para fornecer alguma resiliência de máquina virtual diretamente no nível da instância. Os detalhes das diversas políticas disponíveis no GCP estão disponíveis aqui.
As seções anteriores explicaram como um balanceador de carga em nuvem fornece failover automático de endereço IP para uma funcionalidade de IP Virtual (parecida com VIP) com espelhamento de bancos de dados. O balanceador de carga em nuvem usa a página de status de verificação de integridade <span class="Characteritalic" style="font-style:italic">mirror_status.cxw</span> mencionada anteriormente na seção Balanceadores de carga internos. Existem dois modos de espelhamento de bancos de dados: síncrono com failover automático e assíncrono. Neste exemplo, será abordado o espelhamento com failover síncrono. Os detalhes do espelhamento estão disponíveis aqui.
A configuração de espelhamento mais básica é um par de membros espelho de failover em uma configuração controlada pelo Arbiter. O Arbiter é colocado em uma terceira zona dentro da mesma região para proteção contra possíveis interrupções na zona que impactem tanto o Arbiter quanto um dos membros espelho.
Existem várias maneiras de configurar o espelhamento na configuração de rede. Neste exemplo, usaremos as subredes definidas anteriormente na seção Definições de subrede e gateway de rededeste documento. Serão fornecidos exemplos de esquemas de endereço IP em uma seção abaixo e, para o objetivo desta seção, somente as interfaces de rede e subredes designadas serão representadas.

Recuperação de desastres
O espelhamento de bancos de dados da InterSystems estende a funcionalidade de alta disponibilidade para também dar suporte à recuperação de desastres para outra região geográfica do GCP para proporcionar resiliência operacional no caso improvável de uma região GCP inteira ficar offline. Como uma aplicação conseguirá suportar essas interrupções depende da meta de tempo de recuperação (RTO) e das metas de ponto de recuperação (RPO). Elas fornecerão a estrutura inicial para a análise necessária para projetar um plano de recuperação de desastres adequado. Os seguintes links apresentam um guia para os itens que devem ser considerados ao criar um plano de recuperação de desastres para sua aplicação. https://cloud.google.com/solutions/designing-a-disaster-recovery-plan e https://cloud.google.com/solutions/disaster-recovery-cookbook
Espelhamento assíncrono de bancos de dados
O espelhamento de bancos de dados da InterSystems IRIS Data Platform fornece funcionalidades robustas para replicação assíncrona de dados entre zonas e regiões do GCP para ajudar a alcançar os objetivos de RTO e RPO de seu plano de recuperação de desastres. Os detalhes de membros espelho assíncronos estão disponíveis aqui.
Similar à seção anterior sobre alta disponibilidade, um balanceador de carga em nuvem fornece failover automático de endereço IP para uma funcionalidade de IP Virtual (parecida com IP virtual) para espelhamento assíncrono para recuperação de desastres também usando a mesma página de status de verificação de integridade <span class="Characteritalic" style="font-style:italic">mirror_status.cxw</span> mencionada anteriormente na seção Balanceadores de carga internos.
Neste exemplo, o espelhamento assíncrono de failover para recuperação de desastres será abordado junto com a introdução do serviço de Balanceamento de carga global do GCP para fornecer a sistemas upstream e estações de trabalho clientes um único endereço IP anycast, independentemente de em qual zona ou região sua implantação da InterSystems IRIS esteja operando.
Um dos avanços do GCP é o que o balancedador de carga é um recurso global definido por software e não está vinculado a uma região específica. Dessa forma, você terá o recurso exclusivo de usar um único serviço entre regiões, já que não é uma instância ou solução baseada em dispositivo. Os detalhes do Balanceamento Global de carga com IP anycast do GCP estão disponíveis aqui.
.png)
No exemplo acima, os endereços IP de todas as três instâncias da InterSystems IRIS recebem um Balanceador de carga global do GCP, e o tráfego será encaminhado somente para o membro espelho que for o espelho primário ativo, independentemente da zona ou região na qual está localizado.
Cluster fragmentado
A InterSystems IRIS inclui um amplo conjunto de funcionalidades para permitir escalabilidade de suas aplicações, que podem ser aplicadas de maneira independente ou conjunta, dependendo da natureza de sua carga de trabalho e dos desafios de desempenho específicos enfrentados. Uma dessas funcionalidades, a fragmentação, particiona os dados e o cache associado em diversos servidores, fornecendo escalabilidade flexível, barata e com bom desempenho para consultas e ingestão de dados, ao mesmo tempo em que maximiza o valor da infraestrutura por meio da utilização de recursos extremamente eficiente. Um cluster fragmentado da InterSystems IRIS pode proporcionar vantagens de desempenho significativas para diversas aplicações, mas especialmente para aquelas com cargas de trabalho que incluem um ou mais dos seguintes aspectos:
- Ingestão de dados de alta velocidade ou alto volume, ou uma combinação das duas.
- Conjuntos de dados relativamente grandes ou consultas que retornam grandes quantidades de dados, ou ambos.
- Consultas complexas que realizam grandes quantidades de processamento de dados, como aquelas que buscam muitos dados no disco ou envolvem trabalho computacional significativo.
Cada um desses fatores tem suas próprias influências no ganho potencial obtido com a fragmentação, mas pode haver mais vantagens quando há uma combinação deles. Por exemplo, uma combinação dos três fatores (grandes quantidades de dados ingeridos rapidamente, grandes conjuntos de dados e consultas complexas que recuperam e processam muitos dados) faz muitas das cargas de trabalho analíticas da atualidade excelentes candidatas para a fragmentação.
Todas essas características estão relacionadas a dados, e a principal função da fragmentação da InterSystems IRIS é fornecer escalabilidade para grandes volumes de dados. Porém, um cluster fragmentado também pode incluir recursos para escalabilidade de volume de usuários, quando as cargas de trabalho que envolvem alguns ou todos esses fatores relacionados a dados também têm um altíssimo volume de consultas devido à grande quantidade de usuários. A fragmentação também pode ser combinada com escalabilidade vertical.
Visão geral operacional
O centro da arquitetura de fragmentação é o particionamento dos dados e do cache associado em vários sistemas. Um cluster fragmentado particiona fisicamente grandes tabelas de bancos de dados horizontalmente (ou seja, por linha) em diversas instâncias da InterSystems IRIS, chamadas denós de dados, enquanto permite às aplicações acessar de maneira transparente essas tabelas por qualquer nó e ainda ver todo o conjunto de dados como uma única união lógica. Essa arquitetura tem as seguintes vantagens:
- Processamento paralelo: as consultas são executadas em paralelo nos nós de dados, e os resultados são unidos, combinados e retornados à aplicação como resultados de consulta completos pelo nó ao qual a aplicação está conectada, aumentando consideravelmente a velocidade de execução em diversos casos.
- Cache particionado: cada nó de dados tem seu próprio cache, exclusivo para a partição fragmentada dos dados da tabela fragmentada que ele armazena, em vez de um único cache da instância atendendo a todo o conjunto de dados, o que reduz bastante o risco de sobrecarregar o cache e forçar leituras no disco que degradam o desempenho.
- Carregamento paralelo: os dados podem ser carregados nos nós de dados em paralelo, reduzindo o cache e a contenção de disco entre a carga de trabalho de ingestão e a carga de trabalho de consulta, e aumentando o desempenho de ambas.
Os detalhes de cluster fragmentado da InterSystems IRIS estão disponíveis aqui.
Elementos de fragmentação e tipos de instância
Um cluster fragmentado consiste de pelo menos um nó de dados e, se necessário para requisitos específicos de desempenho ou carga de trabalho, uma quantidade opcional de nós computacionais. Esses dois tipos de nó oferecem blocos de construção simples com um modelo de escalabilidade simples, transparente e eficiente.
Nós de dados
Os nós de dados armazenam dados. No nível físico, os dados de tabelas fragmentadas são espalhados em todos os nós de dados do cluster, e os dados de tabelas não fragmentadas são armazenados fisicamente somente no primeiro nó de dados. Essa diferença é transparente para os usuários, com uma única possível exceção: o primeiro nó pode ter um consumo de armazenamento um pouco maior que os outros, mas espera-se que essa diferença seja insignificante, já que os dados de tabelas fragmentadas costumam ser maiores que os dados de tabelas não fragmentadas em pelo menos uma ordem de grandeza.
Os dados de tabelas fragmentadas podem ser rebalanceados no cluster quando necessário, em geral após adicionar novos nós de dados. Essa ação moverá "buckets" de dados entre os nós para deixar a distribuição de dados aproximadamente igual.
No nível lógico, os dados de tabelas não fragmentadas e a junção de todos os dados das tabelas fragmentadas são visíveis de qualquer nó, então os clientes verão todo o conjunto de dados, independentemente de a qual nó estão conectados. Os metadados e o código também são compartilhados entre todos os nós de dados.
O diagrama básico da arquitetura de um cluster fragmentado consiste simplesmente dos nós de dados que parecem uniformes em todo o cluster. As aplicações cliente podem se conectar a qualquer nó e usarão os dados como se eles fossem locais.

Nós de dados
Para cenários avançados em que é necessário ter baixas latências, possivelmente com uma chegada constante de dados, podem ser adicionados nós computacionais para fornecer uma camada de cache transparente para responder às consultas.
Os nós computacionais armazenam dados em cache. Cada nó computacional está associado a um nó de dados, para o qual ele armazena em cache os dados das tabelas fragmentadas correspondentes e, além disso, ele também armazena em cache dados das tabelas não fragmentadas conforme necessário para responder às consultas.

Como os nós computacionais não armazenam fisicamente dados e têm a função de dar suporte à execução de consultas, o perfil de hardware deles pode ser personalizado de acordo com essas necessidades, por exemplo, adicionando mais memória e CPI e mantendo o armazenamento no mínimo necessário. A ingestão é encaminhada para os nós de dados, seja por um driver (xDBC, Spark) ou implicitamente pelo código de gerenciamento de fragmentação quando o código da aplicação "crua" é executado em um nó computacional.
Ilustrações do cluster fragmentado
Existem várias combinações de implantação de um cluster fragmentado. Os seguintes diagramas de alto nível são fornecidos para ilustrar os modelos de implantação mais comuns. Esses diagramas não incluem os gateways e detalhes de rede e se concentram somente nos componentes do cluster fragmentado.
Cluster fragmentado básico
O diagrama abaixo é o cluster fragmentado mais simples, com quatro nós de dados implantados em uma única região e uma única zona. Um Balanceador de carga global do GCP é usado para distribuir as conexões de clientes para qualquer um dos nós do cluster fragmentado.

Neste modelo básico, não é fornecida resiliência ou alta disponibilidade além daquelas oferecidas pelo GCP para uma única máquina virtual e seu armazenamento SSD persistente. São recomendados dois adaptadores de interface de rede separados para fornecer tanto isolamento de segurança da rede para as conexões de entrada dos clientes quanto isolamento de largura de banda entre o tráfego dos clientes e as comunicações do cluster fragmentado.
Cluster fragmentado básico com alta disponibilidade
O diagrama abaixo é o cluster fragmentado mais simples, com quatro nós de dados espelhados implantados em uma única região dividindo o espelho de cada nó entre zonas. Um Balanceador de carga global do GCP é usado para distribuir as conexões de clientes para qualquer um dos nós do cluster fragmentado.
A alta disponibilidade é fornecida pelo uso do espelhamento de bancos de dados da InterSystems, que manterá um espelho replicado de maneira síncrona em uma zona secundária dentro da região.
São recomendados três adaptadores de interface de rede separados para fornecer isolamento de segurança da rede para as conexões de entrada dos clientes, isolamento de largura de banda entre o tráfego dos clientes e as comunicações do cluster fragmentado, e o tráfego do espelhamento síncrono entre os pares de nó.

Este modelo de implantação também agrega o Arbiter espelho conforme descrito em uma seção anterior deste documento.
Cluster fragmentado com nós computacionais separados
O seguinte diagrama expande o cluster fragmentado para simultaneidade maciça de usuários/consultas com nós computacionais separados e quatro nós de dados. O pool de servidores de Cloud Load Balancer contém somente os endereços dos nós computacionais. As atualizações e ingestões de dados continuarão a ser feitas diretamente nos nós de dados como antes para manter desempenho com latência baixíssima e evitar interferência e congestão de recursos entre as cargas de trabalho analíticas/de consultas e a ingestão de dados em tempo real.
Com este modelo, pode ser feito um ajuste fino da alocação de recursos para escalabilidade de computação/consultas e ingestão de maneira independente, permitindo um uso ideal de recursos quando necessário de forma "just-in-time" e mantendo uma solução simples e econômica, em vez de gastar recursos desnecessariamente só para escalabilidade de computação ou dados.
Os nós computacionais fazem um uso bem direto do grupo de escalabilidade automática do GCP (também chamado de Autoscaling) para permitir a inclusão ou exclusão automática de instâncias de um grupo de instâncias gerenciado com base em aumento ou diminuição da carga. A escalabilidade automática funciona pela inclusão de mais instâncias ao grupo quando há mais carga (aumento de escalabilidade) e pela exclusão de instâncias quando são necessárias menos instâncias (diminuição de escalabilidade).
Os detalhes de escalabilidade automática do GCP estão disponíveis aqui.

A escalabilidade automática ajuda as aplicações em nuvem a tratar de maneira simples o aumento no tráfego e reduz o custo quando a necessidade de recursos diminui. Basta definir a política de escalabilidade automática, e a ferramenta de escalabilidade automática atua com base na carga mensurada.
Operações de backup
Existem várias opções disponíveis para operações de backup. As três opções a seguir são viáveis para sua implantação do GCP com a InterSystems IRIS.
As duas primeiras opções detalhas abaixo incorporam um procedimento do tipo instantâneo (snapshot) que envolve a suspensão das gravações do banco de dados no disco antes de criar o snapshot e, em seguida, a retomada das atualizações assim que o snapshot for bem-sucedido.
As seguintes etapas de alto nível são realizadas para criar um backup limpo usando um dos métodos de snapshot:
- Pausar gravações no banco de dados por meio da chamada de API de congelamento externo do banco de dados.
- Criar snapshots dos discos de dados e do sistema operacional.
- Retomar as gravações do banco de dados por meio da chamada da API de descongelamento externo.
- Arquivos de instalação de backup para localização de backup
Os detalhes das APIs de congelamento/descongelamento externos estão disponíveis aqui.
Nota: não estão incluídos neste documento exemplos de script para backup. Porém, verifique periodicamente os exemplos publicados na InterSystems Developer Community. www.community.intersystems.com A terceira opção é o backup on-line da InterSystems. Esta é uma opção básica para implantações de pequeno porte com um caso de uso e interface bem simples. No entanto, à medida que os bancos de dados aumentam de tamanho, os backups externos com tecnologia de snapshot são recomendados como uma melhor prática, com diversas vantagens, incluindo o backup de arquivos externos, tempos de restauração mais rápidos e uma visão corporativa de dados e ferramentas de gerenciamento.
Etapas adicionais, como verificações de integridade, podem ser adicionadas em intervalos periódicos para garantir um backup limpo e consistente.
Os pontos de decisão sobre qual opção usar dependem dos requisitos operacionais e políticas de sua organização. A InterSystems está disponível para discutir as várias opções com mais detalhes.
Backup de snapshot de disco persistente do GCP
As operações de backup podem ser arquivadas usando a API de linha de comando gcloud do GCP junto com os recursos das APIs de congelamento/descongelamento externos da InterSystems. Assim, é possível ter resiliência operacional 24/7 e a garantia de backups limpos regulares. Os detalhes de gerenciamento, criação e automação de snapshots dos discos persistentes do GCP estão disponíveis aqui.
Snapshots do Logical Volume Manager (LVM)
Como alternativa, muitas das ferramentas de backup de terceiros disponíveis no mercado podem ser usadas implementando agentes de backup individuais na própria VM e aproveitando backups em nível de arquivo em conjunto com snapshots do Logical Volume Manager (LVM).
Um dos principais benefícios desse modelo é ter a capacidade de fazer restaurações em nível de arquivo de VMs Windows ou Linux. Alguns pontos a serem observados com esta solução são: como o GCP e a maioria dos outros provedores em nuvem IaaS não fornecem mídia de fita, todos os repositórios de backup são baseados em disco para arquivamento de curto prazo e têm a capacidade de aproveitar o armazenamento de baixo custo do tipo blob ou bucket para retenção de longo prazo (LTR). É altamente recomendável usar este método para usar um produto de backup que suporte tecnologias de eliminação de duplicação e fazer o uso mais eficiente dos repositórios de backup baseados em disco.
Alguns exemplos desses produtos de backup com suporte à nuvem incluem, mas não se limitam a: Commvault, EMC Networker, HPE Data Protector e Veritas Netbackup.
Nota: a InterSystems não valida ou endossa um produto de backup em detrimento do outro. A responsabilidade de escolher um software de gerenciamento de backup é de cada cliente.
Backup on-line
Para implantações de pequeno porte, o recurso de backup on-line integrado também é uma opção viável. Este utilitário de backup on-line de banco de dados da InterSystems faz backup de dados em arquivos de banco de dados, capturando todos os blocos nos bancos de dados e depois gravando a saída em um arquivo sequencial. Este mecanismo de backup proprietário foi projetado para não causar tempo de inatividade aos usuários do sistema em produção. Os detalhes do backup on-line estão disponíveis aqui.
No GCP, após a conclusão do backup on-line, o arquivo de saída do backup e todos os outros arquivos em uso pelo sistema devem ser copiados para algum outro local de armazenamento fora da instância da máquina virtual. O armazenamento de bucket/objeto é uma boa opção.
Existem duas opções para usar um bucket de armazenamento do GCP.
- Usar as APIs de script gcloud diretamente para copiar e manipular os arquivos de backup on-line recém-criados (e outros arquivos não relacionados ao banco de dados). Os detalhes estão disponíveis aqui.
- Montar um bucket de armazenamento como um sistema de arquivo e usá-lo de maneira similar a um disco persistente, embora os buckets de armazenamento em nuvem sejam armazenamento de objetos.
Os detalhes de como montar um bucket de armazenamento em nuvem usando o Cloud Storage FUSE estão disponíveis aqui.


 Aplicativo usado na demonstração:
Aplicativo usado na demonstração: 
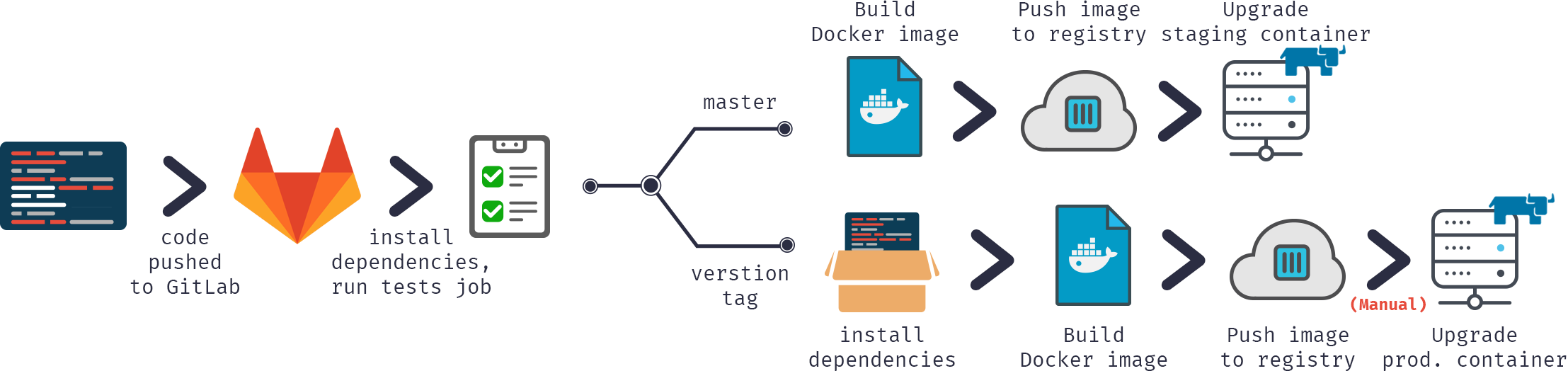




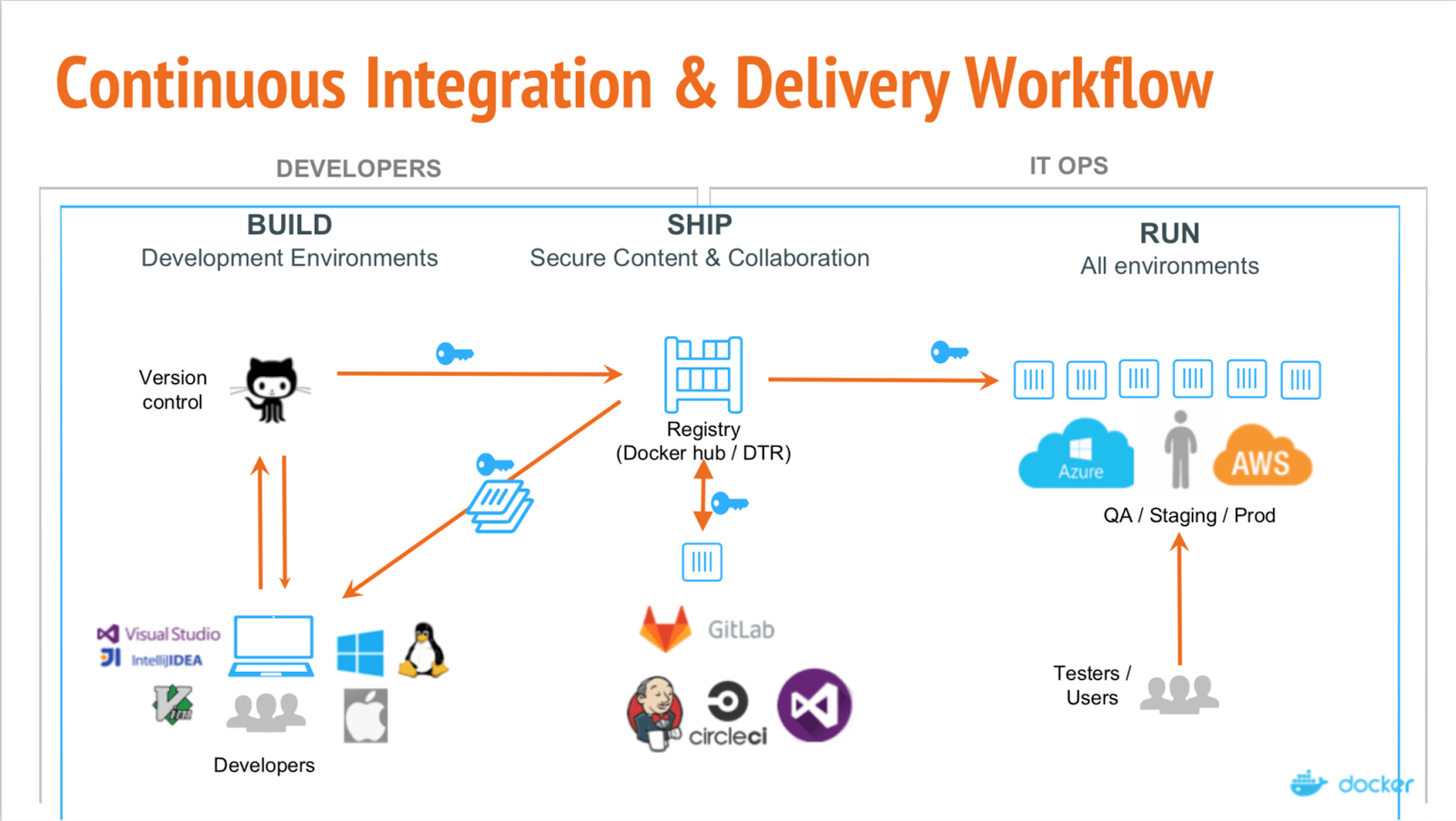















.png)
.png)






