Olá a todos,
Feliz em anunciar uma GitHub Action para fazer o deploy de fontes de um repositório GitHub diretamente para o IRIS.
Por favor viste https://openexchange.intersystems.com/package/Github-Action-IRIS-Deployer
Entrega Contínua (CD) é uma abordagem de engenharia de software em que as equipes produzem software em ciclos curtos, garantindo que o software possa ser lançado de forma confiável a qualquer momento. Seu objetivo é construir, testar e lançar software com mais rapidez e frequência.
Olá a todos,
Feliz em anunciar uma GitHub Action para fazer o deploy de fontes de um repositório GitHub diretamente para o IRIS.
Por favor viste https://openexchange.intersystems.com/package/Github-Action-IRIS-Deployer
Quando você implanta código de um repositório, a deleção de classes (arquivos) pode não ser refletida pelo seu sistema CICD.
Aqui está um simples código para automaticamente deletar todas as classes em um pacote específico que não foi importado; Ele pode ser facilmente ajustado para uma variedade de tarefas adjuntas:
set packages = "USER.*,MyCustomPackage.*"set dir = "C:\InterSystems\src\"set sc = $SYSTEM.OBJ.LoadDir(dir,"ck", .err, 1, .loaded)
set sc = $SYSTEM.OBJ.Delete(packages _ ",'" _ $LTS($LI($LFS(loaded_",",".cls,"), 1, *-1), ",'"),, .err2)O primeiro comando compila classes e também retorna uma lista de classes carregadas. O segundo comando deleta todas as classes de pacotes específicos, com exceção às classes carregadas anteriormente a ele.
A versão 2024.3 da plataforma de dados InterSystems IRIS® , InterSystems IRIS® for HealthTM, and HealthShare® Health Connect já está disponível para o público em geral.
Nesta versão, você pode esperar uma série de atualizações interessantes, incluindo:
Bem-vindo ao capítulo seguinte da minha série sobre CI/CD, onde discuto possíveis abordagens de desenvolvimento de software com tecnologias da InterSystems e GitLab.
Hoje, vamos falar sobre interoperabilidade.
Em uma produção de interoperabilidade ativa, há dois fluxos de processo separados: uma produção em funcionamento que processa as mensagens e um fluxo de processo CI/CD que atualiza o código, a configuração da produção e as configurações padrão do sistema.
Claramente, os processos CI/CD afetam a interoperabilidade. No entanto, as perguntas são:
Vamos começar com o ciclo de vida da produção.
Primeiro, a Produção pode ser iniciada. Só pode ser executada uma produção por namespace ao mesmo tempo, e em geral (a menos que você saiba o que e porque está fazendo isso), apenas uma produção deve ser executada por namespace. Alternar várias vezes em um namespace entre duas ou mais produções diferentes não é recomendado. Ao iniciar a produção, todos os Hosts de Negócio habilitados definidos nela são inicializados. Se alguns Hosts de Negócio não inicializarem, isso não afeta a inicialização da Produção.
Dicas:
##class(Ens.Director).StartProduction("ProductionName")OnStartApós a inicialização da Produção, Ens.Director monitora continuamente a produção em execução. Há dois estados de produção: o estado desejado, definido na classe da produção e nas Configurações Padrão do Sistema, e o estado em execução, os jobs atualmente em execução com configurações aplicadas quando os jobs foram criados. Se os estados desejado e atual forem idênticos, está tudo bem, mas a produção pode (e deve) ser atualizada se houver uma diferença. Geramente, você vê isso como um botão vermelho Update na página de Configurações da Produção no Portal de Gerenciamento de Sistemas.
A atualização da produção significa uma tentativa de corresponder o estado atual da Produção ao estado visado.
A execução de ##class(Ens.Director).UpdateProduction(timeout=10, force=0) para atualizar a produção faz o seguinte com cada Host de Negócio:
Depois de executar isso para cada Host de Negócio, UpdateProduction cria o conjunto de mudanças:
E, depois disso, aplica essas mudanças.
Dessa forma, "atualizar" as configurações sem mudar nada resulta em nenhum tempo de inatividade da produção.
Dicas:
##class(Ens.Director).UpdateProduction(timeout=10, force=0)Ens.Director:UpdateProduction com um tempo limite maior.UpdateProduction NÃO ATUALIZA BHs com código desatualizado. Esse é um comportamento voltado para a segurança, mas, se você quiser atualizar todos os BHs em execução automaticamente se o código subjacente mudar, siga estas etapas:
Primeiro, carregue e compile desta maneira:
do $system.OBJ.LoadDir(dir, "", .err, 1, .load)
do $system.OBJ.CompileList(load, "curk", .errCompile, .listCompiled)
Agora, listCompiled teria todos os itens que foram realmente compilados (use git diffs para minimizar o conjunto carregado) devido à flag u. Use listCompiled para obter um $lb de todas as classes que foram compiladas:
set classList = ""
set class = $o(listCompiled(""))
while class'="" {
set classList = classList _ $lb($p(class, ".", 1, *-1))
set class=$o(listCompiled(class))
}
Depois disso, calcule uma lista de BHs que precisam de uma reinicialização:
SELECT %DLIST(Name) bhList
FROM Ens_Config.Item
WHERE 1=1
AND Enabled = 1
AND Production = :production
AND ClassName %INLIST :classList
Por fim, após obter bhList, interrompa e inicie os hosts afetados:
for stop = 1, 0 {
for i=1:1:$ll(bhList) {
set host = $lg(bhList, i)
set sc = ##class(Ens.Director).TempStopConfigItem(host, stop, 0)
}
set sc = ##class(Ens.Director).UpdateProduction()
}
As produções podem ser interrompidas, ou seja, uma solicitação pode ser enviada para desativar todos os Jobs do Host de Negócio (com segurança, após lidarem com as mensagens ativas, se houver alguma).
Dicas:
##class(Ens.Director).StopProduction(timeout=10, force=0)Ens.Director:StopProduction com um tempo limite maior.OnStartO importante aqui é que a produção seja a soma total dos Hosts de Negócio:
Isso nos leva ao ciclo de vida dos Hosts de Negócio.
Os Hosts de Negócio são compostos de Jobs de Hosts de Negócio idênticos (de acordo com um valor de configuração de tamanho do pool). Ao inicializar um Host de Negócio, todos os Jobs de Hosts de Negócio também são inicializados. Eles são inicializados em paralelo.
Jobs de Host de Negócio individuais são inicializados desta maneira:
Após a conclusão de (4), o Job não pode alterar as configurações ou o código, então quando você importa código novo/igual e configurações padrão do sistema novas/iguais, isso não afeta os jobs de interoperabilidade atualmente em execução.
Interromper um Job de Host de Negócio significa o seguinte:
OnMessage para BO, OnProcessInput para BS, S<int> para BPL BPs e On* para BPs).force=0, ocorrerá a falha da atualização da produção para esse Host de Negócio (voce verá um botão "Update" vermelho no Portal de Gerenciamento de Sistemas).timeoutforce=1A atualização do Host de Negócio significa a interrupção de todos os Jobs em execução para o Host de Negócio e a inicialização de novos Jobs.
Todos os Hosts de Negócio são inicializados imediatamente usando as novas versões das Regras de negócios, de roteamento e DTLs assim que ficarem disponíveis. A reinicialização de um Host de Negócio não é necessária nesse caso.
Às vezes, no entanto, as atualizações da produção exigem tempo de inatividade de Hosts de Negócio individuais.
Considere a situação. Você tem uma Regra de Roteamento X atual que encaminha as mensagens para o Processo de Negócio A ou B com base em critérios arbitrários. Em um novo commit, você adiciona, simultaneamente:
Nesse caso, você não pode só carregar a regra primeiro e depois atualizar a produção. A regra recém-copilada imediatamente começaria a encaminhar as mensagens para o Processo de Negócio C, que o InterSystems IRIS talvez ainda não tenha compilado ou a interoperabilidade ainda não tenha atualizado para usar. Nesse caso, você precisa desativar o Host de Negócio com uma Regra de Roteamento, atualizar o código, atualizar a produção e ativar o Host de Negócio novamente.
Observações:
As dependências entre Hosts de Negócio são fundamentais. Suponha que você tenha os Processos de Negócio A e B, em que A envia mensagens a B. Em um novo commit, você adiciona, simultaneamente:
Nesse caso, PRECISAMOS atualizar o Processo B primeiro e o A depois. Você pode fazer isso de uma das seguintes maneiras:
Uma variação mais desafiadora desse tema, em que as novas versões dos Processos A e B são incompatíveis com as versões antigas, exige tempo de inatividade do Host de Negócio.
Se você sabe que, após a atualização, um Host de Negócio não conseguirá processar mensagens antigas, você precisa garantir que a Fila do Host de Negócio esteja vazia antes da atualização. Para isso, desative todos os Hosts de Negócio que enviam mensagens para o Host de Negócios e espere até que a fila fique vazia.
Primeiro, uma pequena introdução sobre como funcionam os BPs do BPL. Depois de compilar um BP do BPL, duas classes são criadas no pacote com o mesmo nome que o da classe BPL completa:
Thread1 contém os métodos S1, S2, ... SN, que corresponde às atividades no BPLContext tem todas as variáveis de contexto, além do próximo estado que o BPL executaria (ou seja, S5)Além disso, a classe BPL é persistente e armazena as solicitações que estão sendo processadas.
O BPL funciona ao executar os métodos S em uma classe Thread e atualizando de maneira correspondente a tabela da classe BPL, Context e Thread1, em que uma mensagem "em processamento" é uma linha em uma tabela BPL. Após o processamento da solicitação, o BPL exclui as entradas do BPL, Context e Thread. Como os BPs do BPL são assíncronos, um job BPL pode processar simultaneamente várias solicitações ao salvar as informações entre chamadas S e alternar entre diferentes solicitações. Por exemplo, o BPL processou uma solicitação até chegar a uma atividade sync, aguardando uma resposta da BO. Ele salvaria o contexto atual no disco, com a propriedade %NextState (na classe Thread1) definida para o método S de atividade de resposta e trabalharia em outras solicitações até a BO responder. Após a resposta da BO, o BPL carregaria "Context" na memória e executaria o método correspondente a um estado salvo na propriedade %NextState.
Agora, o que acontece quando atualizamos o BPL? Primeiro, precisamos conferir se pelo menos uma destas condições é atendida:
Se pelo menos uma condição for atendida, podemos continuar. Não há solicitações de pré-atualização para processar o BPL pós-atualização ou os Estados são adicionados no final, o que significa que as solicitações antigas também podem ir para lá (supondo que as solicitações de pré-atualização sejam compatíveis com as atividades e o processamento do BPL pós-atualização).
Mas e se você tiver solicitações ativas em processamento e o BPL mudar a ordem dos estados? O ideal é, se você puder esperar, desativar os autores de chamada do BPL e esperar até que a fila esteja vazia. Valide se a tabela Context também está vazia. Lembre-se de que a Fila mostra apenas as solicitações não processadas e a tabela Context armazena as solicitações em trabalho, então um BPL muito ocupado pode mostrar o tamanho da Fila como zero e isso é normal. Depois disso, desative o BPL, realize a atualização e ative todos os Hosts de Negócio desativados anteriormente.
Se isso não for possível (geralmente quando o BPL é muito longo, lembro de atualizar um que demorou cerca de uma semana para processar uma solicitação, ou a janela de atualização é muito curta), use o versionamento do BPL.
Como alternativa, você pode escrever um script de atualização. No script de atualização, mapeie os próximos estados antigos para os próximos estados novos e execute na tabela Thread1 para que o BPL atualizado possa processar solicitações antigas. O BPL precisa ser desativado durante a atualização. Dito isso, é uma situação extremamente rara e geralmente desnecessária, mas, se precisar fazer isso, é dessa maneira.
A interoperabilidade implementa um algoritmo sofisticado para minimizar o número de ações necessárias para atualizar a produção após a alteração do código subjacente. Chame UpdateProduction com um tempo limite seguro em cada atualização de SDS. Para cada atualização de código, você precisa decidir uma estratégia.
Minimizar a quantidade de código compilado usando git diffs ajuda no tempo de compilação, mas "atualizar" o código com ele mesmo e compilá-lo novamente ou "atualizar" as configurações com os mesmos valores não aciona ou exige uma atualização da produção.
Atualizar e compilar Regras de Negócio, Regras de Roteamento e DTLs os torna imediatamente acessíveis sem a atualização da produção.
Por fim, a atualização da produção é uma operação segura e geralmente não requer tempo de inatividade.
O autor gostaria de agradecer a @James MacKeith, @Dmitry Zasypkin e @Regilo Regilio Guedes de Souza pela ajuda inestimável com este artigo.
Após uma pausa de quase quatro anos, minha série sobre CI/CD está de volta! Ao longo dos anos, trabalhei com vários clientes da InterSystems, desenvolvendo pipelines de CI/CD para diferentes casos de uso. Espero que as informações apresentadas neste artigo sejam úteis para alguém.
Esta série de artigos discute várias abordagens possíveis para o desenvolvimento de software com tecnologias da InterSystems e do GitLab.
Temos uma variedade interessante de tópicos para abordar: hoje, vamos falar sobre elementos fora do código — ou seja, configurações e dados.
Anteriormente, discutimos promoções de código e, de certa forma, sem estado — sempre passamos de uma instância (presumivelmente) vazia para uma codebase completa. No entanto, às vezes, precisamos fornecer dados ou estado. Há diferentes tipos de dados:
Vamos discutir todos esses tipos de dados e como eles podem ser adicionados primeiro ao controle de fonte e posteriormente implantados.
A configuração do sistema é dividida em muitas classes diferentes, mas o InterSystems IRIS pode exportar a maioria delas para XMLs. Primeiro, um Pacote de segurança contém informações sobre:
Todas essas classes fornecem métodos Exists, Export e Import, permitindo movê-las entre ambientes.
Algumas ressalvas:
Também vale a pena notar que, em vez de importar/exportar, você pode usar %Installer ou Mesclagem CPF para criar a maioria desses elementos. Ambas as ferramentas também são compatíveis com a criação de namespaces e bancos de dados. A Mesclagem CPF pode ajustar as configurações do sistema, como o tamanho do buffer global.
A classe %SYS.Task armazena tarefas e fornece métodos ExportTasks e ImportTasks. Você também pode verificar a classe de utilitário acima para importar e exportar tarefas uma a uma. Observe que, ao importar tarefas, você pode obter erros de importação (ERROR #7432: Start Date and Time must be after the current date and time - A data e o horário de início precisam ser posteriores à data e ao horário atual) se StartDate ou outras propriedades relacionadas à programação estiverem no passado. Como solução, defina LastSchedule como 0 para o InterSystems IRIS reprogramar uma tarefa recém-importada para ser executada em um futuro próximo.
As produções de interoperabilidade contêm:
Os dois primeiros estão disponíveis no pacote Ens.Config com métodos %Export e %Import. Exporte Credenciais e Tabelas Lookup usando a classe de utilitário acima. Em versões recentes, Tabelas Lookup podem ser exportadas/importadas pela classe $system.OBJ.
Configurações Padrão de Sistema - é um mecanismo de interoperabilidade padrão para configurações específicas ao ambiente:
A finalidade das configurações padrão do sistema é simplificar o processo de cópia de uma definição de produção de um ambiente para outro. Em qualquer produção, os valores de algumas configurações são determinados como parte do design de produção. Geralmente, essas configurações são as mesmas em todos os ambientes. Outras configurações, no entanto, precisam ser ajustadas ao ambiente. Essas configurações incluem caminhos de arquivo, números de portas e assim por diante.
As configurações padrão do sistema precisam especificar apenas os valores do ambiente em que o InterSystems IRIS está instalado. Por outro lado, a definição da produção precisa especificar valores de configurações que devem ser iguais em todos os ambientes.
Recomendo usá-los em ambientes de produção. Use %Export e %Import para transferir as configurações padrão do sistema.
Seu aplicativo provavelmente também usa configurações. Nesse caso, recomendo usar as Configurações Padrão do Sistema. Embora seja um mecanismo de interoperabilidade, as configurações podem ser acessadas via: %GetSetting(pProductionName, pItemName, pHostClassName, pTargetType, pSettingName, Output pValue) (documentos). Você pode escrever um wrapper para definir os padrões com que você não se importa, por exemplo:
ClassMethod GetSetting(name, Output value) As %Boolean [Codemode=expression]
{
##class(Ens.Config.DefaultSettings).%GetSetting("myAppName", "default", "default", , name, .value)
}
Se você quiser mais categorias, você também pode expor argumentos pItemName e/ou pHostClassName. As configurações podem ser definidas inicialmente ao importar, usar o Portal de Gerenciamento de Sistema, criar objetos da classe Ens.Config.DefaultSettings ou definir ^Ens.Config.DefaultSettingsD como global.
Meu principal conselho aqui seria manter as configurações em um só lugar (pode ser as Configurações Padrão do Sistema ou uma solução personalizada), e o aplicativo precisa obter as configurações usando apenas a API fornecida. Dessa forma, o próprio aplicativo não conhece o ambiente e o que resta é fornecer um armazenamento centralizado de configurações com valores específicos ao ambiente. Para isso, crie uma pasta de configurações no seu repositório contendo arquivos de configuração com nomes iguais aos das ramificações do ambiente. Em seguida, durante a fase do CI/CD, use a variável de ambiente$CI_COMMIT_BRANCH para carregar o arquivo correto.
DEV.xml
TEST.xml
PROD.xml
Se você tiver vários arquivos de configurações por ambiente, use pastas com nomes de ramificações de ambiente. Para obter o valor da variável de ambiente de dentro do InterSystems IRIS, use$System.Util.GetEnviron("name").
Se você quiser disponibilizar dados (tabelas de referência, catálogos, etc.), há várias formas de fazer isso:
xml.gz, os métodos $system.OBJ automaticamente (des)arquivam os arquivos xml.gz conforme necessário. A principal desvantagem dessa abordagem é que os dados não são legíveis por humanos, nem mesmo o XML — a maioria é codificado em base64.O formato que você deve escolher depende do seu caso de uso. Listei aqui os formatos na ordem de eficiência de armazenamento, mas essa não é uma preocupação se você não tiver muitos dados.
O estado adiciona complexidade aos seus pipelines de implantação de CI/CD, mas o InterSystems IRIS fornece uma vasta gama de ferramentas para gerenciá-lo.
Nesta série de artigos, quero apresentar e discutir várias abordagens possíveis para o desenvolvimento de software com tecnologias da InterSystems e do GitLab. Vou cobrir tópicos como:
Neste artigo, falaríamos sobre como criar e implantar seu próprio contêiner.
Como os contêineres são bastante efêmeros, eles não devem armazenar nenhum dado do aplicativo. O recurso %SYS Durável permite exatamente isso — armazenar configurações, definições, dados %SYS, etc. em um volume de host, especificamente:
Por outro lado, precisamos armazenar o código do aplicativo dentro do nosso contêiner para atualizá-lo quando necessário.
Tudo isso nos leva a esta arquitetura:

Para fazer isso durante o tempo de compilação, precisamos, no mínimo, criar um banco de dados adicional (para armazenar o código do aplicativo) e mapeá-lo no namespace do aplicativo. No meu exemplo, eu usaria o namespace USER para manter os dados do aplicativo, como ele já existe e é durável.
Com base no descrito acima, nosso instalador precisa:
Class MyApp.Hooks.Local
{
Parameter Namespace = "APP";
/// See generated code in zsetup+1^MyApp.Hooks.Local.1
XData Install [ XMLNamespace = INSTALLER ]
{
<Manifest>
<Log Text="Creating namespace ${Namespace}" Level="0"/>
<Namespace Name="${Namespace}" Create="yes" Code="${Namespace}" Ensemble="" Data="IRISTEMP">
<Configuration>
<Database Name="${Namespace}" Dir="/usr/irissys/mgr/${Namespace}" Create="yes" MountRequired="true" Resource="%DB_${Namespace}" PublicPermissions="RW" MountAtStartup="true"/>
</Configuration>
<Import File="${Dir}Form" Recurse="1" Flags="cdk" IgnoreErrors="1" />
</Namespace>
<Log Text="End Creating namespace ${Namespace}" Level="0"/>
<Log Text="Mapping to USER" Level="0"/>
<Namespace Name="USER" Create="no" Code="USER" Data="USER" Ensemble="0">
<Configuration>
<Log Text="Mapping Form package to USER namespace" Level="0"/>
<ClassMapping From="${Namespace}" Package="Form"/>
<RoutineMapping From="${Namespace}" Routines="Form" />
</Configuration>
<CSPApplication Url="/" Directory="${Dir}client" AuthenticationMethods="64" IsNamespaceDefault="false" Grant="%ALL" Recurse="1" />
</Namespace>
</Manifest>
}
/// This is a method generator whose code is generated by XGL.
/// Main setup method
/// set vars("Namespace")="TEMP3"
/// do ##class(MyApp.Hooks.Global).setup(.vars)
ClassMethod setup(ByRef pVars, pLogLevel As %Integer = 0, pInstaller As %Installer.Installer) As %Status [ CodeMode = objectgenerator, Internal ]
{
Quit ##class(%Installer.Manifest).%Generate(%compiledclass, %code, "Install")
}
/// Entry point
ClassMethod onAfter() As %Status
{
try {
write "START INSTALLER",!
set vars("Namespace") = ..#Namespace
set vars("Dir") = ..getDir()
set sc = ..setup(.vars)
write !,$System.Status.GetErrorText(sc),!
set sc = ..createWebApp()
} catch ex {
set sc = ex.AsStatus()
write !,$System.Status.GetErrorText(sc),!
}
quit sc
}
/// Modify web app REST
ClassMethod createWebApp(appName As %String = "/forms") As %Status
{
set:$e(appName)'="/" appName = "/" _ appName
#dim sc As %Status = $$$OK
new $namespace
set $namespace = "%SYS"
if '##class(Security.Applications).Exists(appName) {
set props("AutheEnabled") = $$$AutheUnauthenticated
set props("NameSpace") = "USER"
set props("IsNameSpaceDefault") = $$$NO
set props("DispatchClass") = "Form.REST.Main"
set props("MatchRoles")=":" _ $$$AllRoleName
set sc = ##class(Security.Applications).Create(appName, .props)
}
quit sc
}
ClassMethod getDir() [ CodeMode = expression ]
{
##class(%File).NormalizeDirectory($system.Util.GetEnviron("CI_PROJECT_DIR"))
}
}Para criar o banco de dados não durável, usei um subdiretório de /usr/irissys/mgr, que não é persistente. Observe que a chamada para ##class(%File).ManagerDirectory() retorna um caminho para o diretório durável, e não para o diretório do contêiner interno.
Confira a parte VII para ver as informações completas, mas tudo o que você precisa fazer é adicionar estas duas linhas (em negrito) à configuração existente.
run image:
stage: run
environment:
name: $CI_COMMIT_REF_NAME
url: http://$CI_COMMIT_REF_SLUG.docker.eduard.win/index.html
tags:
- test
script:
- docker run -d
--expose 52773
--volume /InterSystems/durable/$CI_COMMIT_REF_SLUG:/data
--env ISC_DATA_DIRECTORY=/data/sys
--env VIRTUAL_HOST=$CI_COMMIT_REF_SLUG.docker.eduard.win
--name iris-$CI_COMMIT_REF_NAME
docker.eduard.win/test/docker:$CI_COMMIT_REF_NAME
--log $ISC_PACKAGE_INSTALLDIR/mgr/messages.logO argumento do volume monta o diretório do host para o contêiner e a variável ISC_DATA_DIRECTORY mostra ao InterSystems IRIS qual diretório usar. Para citar a documentação:
- Ao executar um contêiner InterSystems IRIS usando essas opções, ocorre o seguinte:
- O volume externo especificado é montado.
- Se o diretório %SYS durável especificado pela variável de ambiente ISC_DATA_DIRECTORY, iconfig/ no exemplo anterior, já existe e contém os dados %SYS duráveis, todos os ponteiros internos da instância são redefinidos para esse diretório e a instância usa os dados que contém.
- Se o diretório %SYS durável especificado na variável de ambiente ISC_DATA_DIRECTORY já existir, mas não conter os dados %SYS duráveis, nenhum dado é copiado e a instância é executada usando os dados na árvore de instalação dentro do contêiner, ou seja, os dados específicos da instância não são persistentes. Por esse motivo, é recomendável incluir nos scripts uma verificação para essa condição antes de executar o contêiner.
- Se o diretório %SYS durável especificado por ISC_DATA_DIRECTORY não existir:
- É criado o diretório %SYS durável.
- Os diretórios e arquivos listados no conteúdo do Diretório %SYS Durável são copiados dos locais instalados para o diretório %SYS durável (os originais permanecem no local).
- Todos os ponteiros internos da instância são redefinidos para o diretório %SYS durável e a instância usa os dados que contém.
Quando o aplicativo evoluir e uma nova versão (contêiner) for lançada, às vezes é necessário executar algum código. Pode ser antes ou depois dos hooks de compilação, das migrações do esquema e dos testes de unidade, mas é necessário executar código arbitrário. Por isso, você precisa de um framework que gerencie seu aplicativo. Em artigos anteriores, descrevi a estrutura básica desse framework, mas, é claro, ele pode ser consideravelmente ampliado para atender a requisitos específicos do aplicativo.
A criação de um aplicativo em contêiner requer algumas considerações, mas o InterSystems IRIS oferece vários recursos para facilitar esse processo.
Nesta série de artigos, quero apresentar e discutir várias abordagens possíveis para o desenvolvimento de software com tecnologias da InterSystems e do GitLab. Vou cobrir tópicos como:
Neste artigo, vamos desenvolver a entrega contínua com o InterSystems Cloud Manager. O ICM é uma solução de provisionamento e implantação na nuvem para aplicativos baseados no InterSystems IRIS. Ele permite definir a configuração de implantação desejada e o ICM provisiona de maneira automática. Para mais informações, consulte First Look: ICM.
Na nossa configuração de entrega contínua:
Ou em formato gráfico:
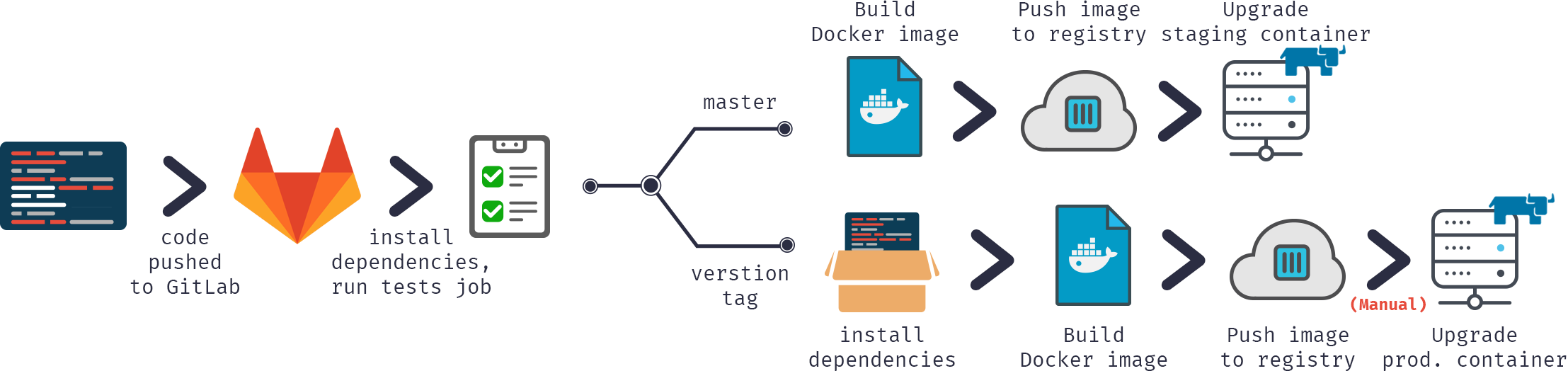
Como você pode ver, é praticamente igual, exceto que usaríamos o ICM em vez de gerenciar os contêineres do Docker manualmente.
Antes de atualizar os contêineres, eles devem ser provisionados. Para isso precisamos definir defaults.json e definitions.json, descrevendo nossa arquitetura. Vou fornecer esses 2 arquivos para um servidor LIVE, as definições para um servidor TEST são as mesmas, e os padrões são os mesmos, exceto para os valores Tag e SystemMode.
{
"Provider": "GCP",
"Label": "gsdemo2",
"Tag": "LIVE","SystemMode": "LIVE",
"DataVolumeSize": "10",
"SSHUser": "sample",
"SSHPublicKey": "/icmdata/ssh/insecure.pub",
"SSHPrivateKey": "/icmdata/ssh/insecure",
"DockerImage": "eduard93/icmdemo:master",
"DockerUsername": "eduard93",
"DockerPassword": "...",
"TLSKeyDir": "/icmdata/tls",
"Credentials": "/icmdata/gcp.json",
"Project": "elebedyu-test",
"MachineType": "n1-standard-1",
"Region": "us-east1",
"Zone": "us-east1-b",
"Image": "rhel-cloud/rhel-7-v20170719",
"ISCPassword": "SYS",
"Mirror": "false"
}
[
{
"Role": "DM",
"Count": "1",
"ISCLicense": "/icmdata/iris.key"
}
]Dentro do contêiner ICM, a pasta /icmdata é montada a partir do host e:
Depois de obter todas as chaves necessárias:
keygenSSH.sh /icmdata/ssh keygenTLS.sh /icmdata/tls
E colocar os arquivos necessários em /icmdata:
Chame o ICM para provisionar suas instâncias:
cd /icmdata/test icm provision icm run cd /icmdata/live icm provision icm run
Um servidor TEST e um servidor LIVE seriam provisionados com uma instância do InterSystems IRIS independente em cada um.
Consulte ICM First Look para ver um guia mais detalhado.
Primeiro, precisamos criar nossa imagem.
Nosso código seria, como sempre, armazenado no repositório, a configuração de CD em gitlab-ci.yml. No entanto, além disso (para aumentar a segurança), armazenaríamos vários arquivos específicos do servidor em um servidor de compilação.
Chave de licença. Como alternativa, ela pode ser baixada durante a compilação do contêiner em vez de armazenada em um servidor. É bastante arriscado armazenar no repositório.
Arquivo contendo a senha padrão. Novamente, é bastante arriscado armazená-lo no repositório. Além disso, se você estiver hospedando um ambiente de produção em um servidor separado, ele poderá ter uma senha padrão diferente.
O script inicial:
set dir = ##class(%File).NormalizeDirectory($system.Util.GetEnviron("CI_PROJECT_DIR"))
do ##class(%SYSTEM.OBJ).Load(dir _ "Installer/Global.cls","cdk")
do ##class(Installer.Global).init()
haltObserve que a primeira linha é deixada em branco de maneira intencional.
Várias coisas diferem dos exemplos anteriores. Em primeiro lugar, não habilitamos a autenticação do SO, pois o ICM interagiria com o contêiner em vez do GitLab diretamente. Segundo, estou usando o manifesto do instalador para inicializar nosso aplicativo para mostrar diferentes abordagens de inicialização. Leia mais sobre o Instalador neste artigo. Por fim, publicaremos nossa imagem em um Docher Hub como um repositório privado.
Nosso manifesto do instalador fica desta forma:
E implementa as seguintes mudanças:
Agora, para a configuração da entrega contínua:
build image:
stage: build
tags:
- master
script:
- cp -r /InterSystems/mount ci
- cd ci
- echo 'SuperUser' | cat - pwd.txt load_ci_icm.script > temp.txt
- mv temp.txt load_ci.script
- cd ..
- docker build --build-arg CI_PROJECT_DIR=$CI_PROJECT_DIR -t eduard93/icmdemo:$CI_COMMIT_REF_NAME .O que está acontecendo aqui?
Primeiro, como o docker build pode acessar apenas subdiretórios de um diretório de compilação base — na raiz do repositório do nosso caso, precisamos copiar nosso diretório "secreto" (aquele com iris.key, pwd.txt e load_ci_icm.script) no repositório clonado.
Em seguida, o primeiro acesso ao terminal requer um usuário/senha, então nós os adicionamos a load_ci.script (por isso a linha vazia no início de load_ci.script).
Por fim, criamos a imagem do docker e a marcamos adequadamente: eduard93/icmdemo:$CI_COMMIT_REF_NAME
onde $CI_COMMIT_REF_NAME é o nome de um branch atual. Observe que a primeira parte da tag de imagem deve ter o mesmo nome do nome do projeto no GitLab, para que possa ser vista na guia GitLab Registry (instruções sobre a marcação estão disponíveis na guia Registry).
A criação de uma imagem docker é feita usando o Dockerfile:
FROM intersystems/iris:2018.1.1-released ENV SRC_DIR=/tmp/src ENV CI_DIR=$SRC_DIR/ci ENV CI_PROJECT_DIR=$SRC_DIR COPY ./ $SRC_DIR RUN cp $CI_DIR/iris.key $ISC_PACKAGE_INSTALLDIR/mgr/ \ && cp $CI_DIR/GitLab.xml $ISC_PACKAGE_INSTALLDIR/mgr/ \ && $ISC_PACKAGE_INSTALLDIR/dev/Cloud/ICM/changePassword.sh $CI_DIR/pwd.txt \ && iris start $ISC_PACKAGE_INSTANCENAME \ && irissession $ISC_PACKAGE_INSTANCENAME -U%SYS < $CI_DIR/load_ci.script \ && iris stop $ISC_PACKAGE_INSTANCENAME quietly
Começamos a partir do contêiner básico iris.
Primeiro, copiamos nosso repositório (e diretório "secreto") dentro do contêiner.
Em seguida, copiamos a chave de licença para o diretório mgr.
Em seguida, alteramos a senha para o valor de pwd.txt. Observe que pwd.txt é excluído nessa operação.
Depois disso, a instância é iniciada e load_ci.script é executado.
Por fim, a instância iris é interrompida.
Estou usando o executor GitLab Shell, e não o executor Docker. O executor Docker é usado quando você precisa de algo de dentro da imagem, por exemplo, você está criando um aplicativo Android em um contêiner java e precisa apenas de um apk. No nosso caso, precisamos de um contêiner inteiro e, para isso, precisamos do executor Shell. Então, estamos executando comandos do Docker pelo executor GitLab Shell.
Agora, vamos publicar nossa imagem em um Docker Hub
publish image:
stage: publish
tags:
- master
script:
- docker login -u eduard93 -p ${DOCKERPASSWORD}
- docker push eduard93/icmdemo:$CI_COMMIT_REF_NAMEObserve a variável ${DOCKERPASSWORD}, é uma variável secreta do GitLab. Podemos adicioná-la em GitLab > Project > Settings > CI/CD > Variables:

Os logs de job também não contêm valor de senha:
Running with gitlab-runner 10.6.0 (a3543a27)
on icm 82634fd1
Using Shell executor...
Running on docker...
Fetching changes...
Removing ci/
HEAD is now at 8e24591 Add deploy to LIVE
Checking out 8e245910 as master...Skipping Git submodules setup$ docker login -u eduard93 -p ${DOCKERPASSWORD}
WARNING! Using --password via the CLI is insecure. Use --password-stdin.
Login Succeeded
$ docker push eduard93/icmdemo:$CI_COMMIT_REF_NAME
The push refers to repository [docker.io/eduard93/icmdemo]
master: digest: sha256:d1612811c11154e77c84f0c08a564a3edeb7ddbbd9b7acb80754fda97f95d101 size: 2620
Job succeeded
e no Docker Hub podemos ver nossa nova imagem:

Temos nossa imagem, agora vamos executá-la em nosso servidor de teste. Aqui está o script.
run image:
stage: run
environment:
name: $CI_COMMIT_REF_NAME
tags:
- master
script:
- docker exec icm sh -c "cd /icmdata/test && icm upgrade -image eduard93/icmdemo:$CI_COMMIT_REF_NAME"Com o ICM, precisamos executar apenas um comando (icm upgrade) para fazer upgrade da implantação existente. Estamos chamando-a executando "docker exec icm sh -c ", que executa um comando especificado dentro do contêiner icm. Primeiro, entramos no modo /icmdata/test, onde a definição da implantação do ICM é configurada para um servidor TEST. Depois disso, chamamos icm upgrade para substituir o contêiner existente por um novo contêiner.
Vamos fazer alguns testes.
test image:
stage: test
tags:
- master
script:
- docker exec icm sh -c "cd /icmdata/test && icm session -namespace USER -command 'do \$classmethod(\"%UnitTest.Manager\",\"RunTest\",\"MyApp/Tests\",\"/nodelete\")' | tee /dev/stderr | grep 'All PASSED' && exit 0 || exit 1"
Novamente, estamos executando um comando dentro do nosso contêiner icm. A sessão icm executa um comando em um nó implantado. O comando executa testes de unidade. Depois disso, ele canaliza todos os resultados para a tela e também para o grep para encontrar os resultados dos testes de unidade e sair do processo com sucesso ou com um erro.
A implantação em um servidor de produção é absolutamente igual à implantação em teste, exceto por outro diretório para a definição da implantação LIVE. Se os testes falhassem, essa etapa não seria executada.
deploy image:
stage: deploy
environment:
name: $CI_COMMIT_REF_NAME
tags:
- master
script:
- docker exec icm sh -c "cd /icmdata/live && icm upgrade -image eduard93/icmdemo:$CI_COMMIT_REF_NAME"Nesta série de artigos, quero apresentar e discutir várias abordagens possíveis para o desenvolvimento de software com tecnologias da InterSystems e do GitLab. Vou cobrir tópicos como:
Nessa série de artigos, discuti abordagens gerais de entrega contínua. É um tema extremamente vasto e essa série de artigos precisa ser vista mais como uma coleção de receitas do que algo definitivo. Se você deseja automatizar o desenvolvimento, os testes e a entrega do seu aplicativo, a entrega contínua em geral e o GitLab em particular é o melhor caminho. A entrega contínua e os contêineres permitem que você personalize seu fluxo de trabalho conforme necessário.
Nesta série de artigos, quero apresentar e discutir várias abordagens possíveis para o desenvolvimento de software com tecnologias da InterSystems e do GitLab. Vou cobrir tópicos como:
No primeiro artigo, abordamos os fundamentos do Git, por que um entendimento de alto nível dos conceitos do Git é importante para o desenvolvimento de software moderno e como o Git pode ser usado para desenvolver software.
No segundo artigo, abordamos o fluxo de trabalho do GitLab: um processo inteiro do ciclo de vida do software e a entrega contínua.
No terceiro artigo, abordamos a instalação e configuração do GitLab e a conexão dos seus ambientes a ele
No quarto artigo, escrevemos uma configuração de CD.
No quinto artigo, falamos sobre contêineres e como (e por que) eles podem ser usados.
No sexto artigo, vamos discutir os principais componentes necessários para executar um pipeline de entrega contínua com contêineres e como eles trabalham juntos.
Neste artigo, criaremos a configuração de entrega contínua discutida nos artigos anteriores.
Na nossa configuração de entrega contínua:
Ou em formato gráfico:
Vamos começar.
Primeiro, precisamos criar nossa imagem.
Nosso código seria, como sempre, armazenado no repositório, a configuração de CD em gitlab-ci.yml. No entanto, além disso (para aumentar a segurança), armazenaríamos vários arquivos específicos do servidor em um servidor de compilação.
Contém o código dos hooks de CD. Foi desenvolvido no artigo anterior e disponibilizado no GitHub. É uma pequena biblioteca para carregar código, executar vários hooks e testar código. Como alternativa preferencial, você pode usar submódulos git para incluir este projeto ou algo semelhante no seu repositório. Os submódulos são melhores porque é mais fácil mantê-los atualizados. Uma outra alternativa seria marcar as versões no GitLab e carregá-las com o comando ADD.
Chave de licença. Como alternativa, ela pode ser baixada durante a compilação do contêiner em vez de armazenada em um servidor. É bastante arriscado armazenar no repositório.
Arquivo contendo a senha padrão. Novamente, é bastante arriscado armazená-lo no repositório. Além disso, se você estiver hospedando um ambiente de produção em um servidor separado, ele poderá ter uma senha padrão diferente.
O script inicial:
Ativa a autenticação do SO
Carrega GitLab.xml
Inicializa as configurações do utilitário GitLab
Carrega o código
set sc = ##Class(Security.System).Get("SYSTEM",.Properties) write:('sc) $System.Status.GetErrorText(sc) set AutheEnabled = Properties("AutheEnabled") set AutheEnabled = $zb(+AutheEnabled,16,7) set Properties("AutheEnabled") = AutheEnabled set sc = ##Class(Security.System).Modify("SYSTEM",.Properties) write:('sc) $System.Status.GetErrorText(sc) zn "USER" do ##class(%SYSTEM.OBJ).Load(##class(%File).ManagerDirectory() _ "GitLab.xml","cdk") do ##class(isc.git.Settings).setSetting("hooks", "MyApp/Hooks/") do ##class(isc.git.Settings).setSetting("tests", "MyApp/Tests/") do ##class(isc.git.GitLab).load() halt
Observe que a primeira linha é deixada em branco de maneira intencional.
Como algumas configurações podem ser específicas do servidor, elas não são armazenadas no repositório, mas separadamente. Se o hook inicial for sempre o mesmo, você pode simplesmente armazená-lo no repositório.
Agora, para a configuração da entrega contínua:
build image:
stage: build
tags:
- test
script:
- cp -r /InterSystems/mount ci
- cd ci
- echo 'SuperUser' | cat - pwd.txt load_ci.script > temp.txt
- mv temp.txt load_ci.script
- cd ..
- docker build --build-arg CI_PROJECT_DIR=$CI_PROJECT_DIR -t docker.domain.com/test/docker:$CI_COMMIT_REF_NAME .O que está acontecendo aqui?
Primeiro, como o docker build pode acessar apenas subdiretórios de um diretório de compilação base — na raiz do repositório do nosso caso, precisamos copiar nosso diretório "secreto" (aquele com GitLab.xml, iris.key, pwd.txt e load_ci.script) no repositório clonado.
Em seguida, o primeiro acesso ao terminal requer um usuário/senha, então nós os adicionamos a load_ci.script (por isso a linha vazia no início de load_ci.script).
Por fim, criamos a imagem do docker e a marcamos adequadamente: docker.domain.com/test/docker:$CI_COMMIT_REF_NAME
onde $CI_COMMIT_REF_NAME é o nome de um branch atual. Observe que a primeira parte da tag de imagem deve ter o mesmo nome do nome do projeto no GitLab, para que possa ser vista na guia GitLab Registry (instruções sobre a marcação estão disponíveis na guia Registry).
A criação da imagem docker é feita usando o Dockerfile:
FROM docker.intersystems.com/intersystems/iris:2018.1.1.611.0 ENV SRC_DIR=/tmp/src ENV CI_DIR=$SRC_DIR/ci ENV CI_PROJECT_DIR=$SRC_DIR COPY ./ $SRC_DIR RUN cp $CI_DIR/iris.key $ISC_PACKAGE_INSTALLDIR/mgr/ \ && cp $CI_DIR/GitLab.xml $ISC_PACKAGE_INSTALLDIR/mgr/ \ && $ISC_PACKAGE_INSTALLDIR/dev/Cloud/ICM/changePassword.sh $CI_DIR/pwd.txt \ && iris start $ISC_PACKAGE_INSTANCENAME \ && irissession $ISC_PACKAGE_INSTANCENAME -U%SYS < $CI_DIR/load_ci.script \ && iris stop $ISC_PACKAGE_INSTANCENAME quietly
Começamos a partir do contêiner básico iris.
Primeiro, copiamos nosso repositório (e diretório "secreto") dentro do contêiner.
Em seguida, copiamos a chave de licença e GitLab.xml para o diretório mgr.
Em seguida, alteramos a senha para o valor de pwd.txt. Observe que pwd.txt é excluído nessa operação.
Depois disso, a instância é iniciada e load_ci.script é executado.
Por fim, a instância iris é interrompida.
Veja o registro do job (parcial, os registros de carregamento/compilação foram ignorados):
Running with gitlab-runner 10.6.0 (a3543a27) on docker 7b21e0c4 Using Shell executor... Running on docker... Fetching changes... Removing ci/ Removing temp.txt HEAD is now at 5ef9904 Build load_ci.script From http://gitlab.eduard.win/test/docker 5ef9904..9753a8d master -> origin/master Checking out 9753a8db as master... Skipping Git submodules setup $ cp -r /InterSystems/mount ci $ cd ci $ echo 'SuperUser' | cat - pwd.txt load_ci.script > temp.txt $ mv temp.txt load_ci.script $ cd .. $ docker build --build-arg CI_PROJECT_DIR=$CI_PROJECT_DIR -t docker.eduard.win/test/docker:$CI_COMMIT_REF_NAME . Sending build context to Docker daemon 401.4kB Step 1/6 : FROM docker.intersystems.com/intersystems/iris:2018.1.1.611.0 ---> cd2e53e7f850 Step 2/6 : ENV SRC_DIR=/tmp/src ---> Using cache ---> 68ba1cb00aff Step 3/6 : ENV CI_DIR=$SRC_DIR/ci ---> Using cache ---> 6784c34a9ee6 Step 4/6 : ENV CI_PROJECT_DIR=$SRC_DIR ---> Using cache ---> 3757fa88a28a Step 5/6 : COPY ./ $SRC_DIR ---> 5515e13741b0 Step 6/6 : RUN cp $CI_DIR/iris.key $ISC_PACKAGE_INSTALLDIR/mgr/ && cp $CI_DIR/GitLab.xml $ISC_PACKAGE_INSTALLDIR/mgr/ && $ISC_PACKAGE_INSTALLDIR/dev/Cloud/ICM/changePassword.sh $CI_DIR/pwd.txt && iris start $ISC_PACKAGE_INSTANCENAME && irissession $ISC_PACKAGE_INSTANCENAME -U%SYS < $CI_DIR/load_ci.script && iris stop $ISC_PACKAGE_INSTANCENAME quietly ---> Running in 86526183cf7c . Waited 1 seconds for InterSystems IRIS to start This copy of InterSystems IRIS has been licensed for use exclusively by: ISC Internal Container Sharding Copyright (c) 1986-2018 by InterSystems Corporation Any other use is a violation of your license agreement %SYS> 1 %SYS> Using 'iris.cpf' configuration file This copy of InterSystems IRIS has been licensed for use exclusively by: ISC Internal Container Sharding Copyright (c) 1986-2018 by InterSystems Corporation Any other use is a violation of your license agreement 1 alert(s) during startup. See messages.log for details. Starting IRIS Node: 39702b122ab6, Instance: IRIS Username: Password: Load started on 04/06/2018 17:38:21 Loading file /usr/irissys/mgr/GitLab.xml as xml Load finished successfully. USER> USER> [2018-04-06 17:38:22.017] Running init hooks: before [2018-04-06 17:38:22.017] Importing hooks dir /tmp/src/MyApp/Hooks/ [2018-04-06 17:38:22.374] Executing hook class: MyApp.Hooks.Global [2018-04-06 17:38:22.375] Executing hook class: MyApp.Hooks.Local [2018-04-06 17:38:22.375] Importing dir /tmp/src/ Loading file /tmp/src/MyApp/Tests/TestSuite.cls as udl Compilation started on 04/06/2018 17:38:22 with qualifiers 'c' Compilation finished successfully in 0.194s. Load finished successfully. [2018-04-06 17:38:22.876] Running init hooks: after [2018-04-06 17:38:22.878] Executing hook class: MyApp.Hooks.Local [2018-04-06 17:38:22.921] Executing hook class: MyApp.Hooks.Global Removing intermediate container 39702b122ab6 ---> dea6b2123165 [Warning] One or more build-args [CI_PROJECT_DIR] were not consumed Successfully built dea6b2123165 Successfully tagged docker.domain.com/test/docker:master Job succeeded
Estou usando o executor GitLab Shell, e não o executor Docker. O executor Docker é usado quando você precisa de algo de dentro da imagem, por exemplo, você está criando um aplicativo Android em um contêiner java e precisa apenas de um apk. No nosso caso, precisamos de um contêiner inteiro e, para isso, precisamos do executor Shell. Então, estamos executando comandos do Docker pelo executor GitLab Shell.
Temos nossa imagem, agora vamos executá-la. No caso de ramificações de recursos, podemos simplesmente destruir o contêiner antigo e iniciar o novo. No caso do ambiente, podemos executar um container temporário e substituir o contêiner do ambiente caso os testes tenham êxito (isso fica como um exercício para o leitor).
Aqui está o script.
destroy old:
stage: destroy
tags:
- test
script:
- docker stop iris-$CI_COMMIT_REF_NAME || true
- docker rm -f iris-$CI_COMMIT_REF_NAME || trueEsse script destrói o contêiner em execução no momento e é sempre bem-sucedido (por padrão, o docker falha se tentar parar/remover um contêiner inexistente).
Em seguida, iniciamos a nova imagem e a registramos como um ambiente. Contêiner Nginx faz proxy automático de solicitações usando a variável de ambiente VIRTUAL_HOST e a diretiva de exposição (para saber em qual porta fazer o proxy).
run image:
stage: run
environment:
name: $CI_COMMIT_REF_NAME
url: http://$CI_COMMIT_REF_SLUG. docker.domain.com/index.html
tags:
- test
script:
- docker run -d
--expose 52773
--env VIRTUAL_HOST=$CI_COMMIT_REF_SLUG.docker.eduard.win
--name iris-$CI_COMMIT_REF_NAME
docker.domain.com/test/docker:$CI_COMMIT_REF_NAME
--log $ISC_PACKAGE_INSTALLDIR/mgr/messages.logVamos fazer alguns testes.
test image:
stage: test
tags:
- test
script:
- docker exec iris-$CI_COMMIT_REF_NAME irissession iris -U USER "##class(isc.git.GitLab).test()"Por fim, vamos publicar nossa imagem no registro
publish image:
stage: publish
tags:
- test
script:
- docker login docker.domain.com -u dev -p 123
- docker push docker.domain.com/test/docker:$CI_COMMIT_REF_NAMEO usuário/código pode ser transmitido usando variáveis secretas do GitLab.
Agora, podemos ver a imagem no GitLab:

E outros desenvolvedores podem a extrair do registro. Na guia de ambientes, todos os ambientes estão disponíveis para a fácil navegação:

Nessa série de artigos, discuti abordagens gerais de entrega contínua. É um tema extremamente vasto e essa série de artigos precisa ser vista mais como uma coleção de receitas do que algo definitivo. Se você deseja automatizar o desenvolvimento, os testes e a entrega do seu aplicativo, a entrega contínua em geral e o GitLab em particular é o melhor caminho. A entrega contínua e os contêineres permitem que você personalize seu fluxo de trabalho conforme necessário.
É isso. Espero que eu tenha abordado os conceitos básicos da entrega contínua e dos contêineres.
Há vários tópicos sobre os quais não falei (talvez mais tarde), especialmente em relação a contêineres:
Nesta série de artigos, quero apresentar e discutir várias abordagens possíveis para o desenvolvimento de software com tecnologias da InterSystems e do GitLab. Vou cobrir tópicos como:
No primeiro artigo, abordamos os fundamentos do Git, por que um entendimento de alto nível dos conceitos do Git é importante para o desenvolvimento de software moderno e como o Git pode ser usado para desenvolver software.
No segundo artigo, abordamos o fluxo de trabalho do GitLab: um processo inteiro do ciclo de vida do software e a entrega contínua.
No terceiro artigo, abordamos a instalação e configuração do GitLab e a conexão dos seus ambientes a ele
No quarto artigo, escrevemos uma configuração de CD.
No quinto artigo, falamos sobre contêineres e como (e por que) eles podem ser usados.
Neste artigo, vamos discutir os principais componentes necessários para executar um pipeline de entrega contínua com contêineres e como eles trabalham juntos.
A configuração deve ser assim:
Aqui podemos ver a separação de três etapas principais:
Nas partes anteriores, a criação era frequentemente incremental — calculamos a diferença entre o ambiente e a codebase atuais e modificamos nosso ambiente para corresponder à codebase. Com contêineres, cada build é completo. O resultado de um build é uma imagem que pode ser executada em qualquer lugar com dependências.
Depois que nossa imagem é criada e aprovada nos testes, ela é carregada no registro — servidor especializado para hospedar imagens docker. Então, é possível substituir a imagem anterior pela mesma tag. Por exemplo, devido ao novo commit para o master branch, nós construímos a nova imagem (project/version:master) e, se os testes funcionarem, podemos substituir a imagem no registro pela nova com a mesma tag, então todos que extraírem project/version:master obtêm uma nova versão.
Por fim, nossas imagens são implantadas. Uma solução de CI, como o GitLab, pode controlar isso ou um orquestrador especializado, mas o ponto é o mesmo: algumas imagens são executadas, verificadas periodicamente quanto à integridade e atualizadas se uma nova versão estiver disponível.
Confira o webinar docker explicando esses diferentes estágios.
Como alternativa, do ponto de vista do commit:

Na nossa configuração de entrega:
Para fazer isso, precisamos do seguinte:
Primeiro de tudo, precisamos executar o docker em algum lugar. Recomendo começar com um servidor mais convencional tipo o Linux, como Ubuntu, RHEL ou Suse. Não use distribuições voltadas para a nuvem, como CoreOS, RancherOS etc. — elas não são destinadas a iniciantes. Não se esqueça de trocar o driver de armazenamento para devicemapper.
Em caso de grandes implantações, usar ferramentas de orquestração de contêineres, como Kubernetes, Rancher ou Swarm, pode automatizar a maioria das tarefas, mas não vamos discuti-las (pelo menos nesta parte).
Esse é o primeiro contêiner que precisamos executar e é um aplicativo do lado do servidor escalável e sem estado que armazena e permite distribuir imagens Docker.
Use o registro se quiser:
Veja a documentação do registro.
Observação: o GitLab inclui registro integrado. Você pode executá-lo em vez do registro externo. Leia os documentos do GitLab vinculados neste parágrafo.
Para conectar seu registro ao GitLab, você precisará executar seu registro com suporte HTTPS — eu uso o Let's Encrypt para obter os certificados e segui este Gist para obter e transmitir os certificados a um contêiner. Depois de garantir a disponibilidade do registro em HTTPS (você pode verificar no navegador), siga estas instruções sobre como conectar o registro ao GitLab. Essas instruções diferem com base no que você precisa e na sua instalação do GitLab. No meu caso, a configuração foi adicionar o certificado do registro e a chave (com o nome adequado e as permissões corretas) a /etc/gitlab/ssl e estas linhas a /etc/gitlab/gitlab.rb:
registry_external_url 'https://docker.domain.com' gitlab_rails['registry_api_url'] = "https://docker.domain.com"
Depois de reconfigurar o GitLab, pude ver a nova guia do Registro, com informações sobre como marcar corretamente as imagens recém-criadas para que elas apareçam aqui.

Na nossa configuração de Entrega Contínua, construímos automaticamente uma imagem por branch e, se a imagem passar nos testes, ela é publicada no registro e executada automaticamente. Para que nosso aplicativo fique disponível em todos os "estados" de maneira automática, por exemplo, podemos acessar:
Para isso, precisamos de um nome de domínio e adicionamos um registro DNS curinga que aponta *.docker.domain.com ao endereço IP de docker.domain.com. Outra opção seria usar portas diferentes.
Como temos várias ramificações de recursos, precisamos redirecionar os subdomínios automaticamente para o contêiner correto. Para fazer isso, podemos usar o Nginx como proxy reverso. Veja aqui um guia.
Para começar a trabalhar com contêineres, você pode usar a linha de comando ou uma das interfaces GUI. Há várias disponíveis, por exemplo:
Eles permitem que você crie contêineres e os gerencie a partir da GUI em vez da CLI. Veja como o Rancher aparenta:

Como antes, para executar scripts em outros servidores, precisaremos instalar o runner do GitLab. Discuti isso no terceiro artigo.
Você precisará usar o executor Shell, e não o executor Docker. O executor Docker é usado quando você precisa de algo de dentro da imagem, por exemplo, você está criando um aplicativo Android em um contêiner java e precisa apenas de um apk. No nosso caso, precisamos de um contêiner inteiro e, para isso, precisamos do executor Shell.
É fácil começar a executar contêineres e há muitas ferramentas disponíveis.
A entrega contínua usando contêineres difere da configuração usual de várias maneiras:
<p>
No próximo artigo, vamos falar sobre a criação da configuração de CD que usa o contêiner Docker do InterSystems IRIS.
</p>
</div>
</div>
</div>
No vasto e variado mercado de banco de dados SQL, o InterSystems IRIS se destaca como uma plataforma que vai muito além do SQL, oferecendo uma experiência multimodelo otimizada e a compatibilidade com um rico conjunto de paradigmas de desenvolvimento. Em especial, o mecanismo Object-Relational avançado ajudou as organizações a usar a abordagem de desenvolvimento mais adequada para cada faceta das cargas de trabalho com muitos dados, por exemplo, fazendo a ingestão de dados por objetos e consultando-os simultaneamente por SQL. As Classes Persistentes correspondem às tabelas SQL, suas propriedades às colunas da tabela, e a lógica de negócios é facilmente acessada usando as Funções Definidas pelo Usuário ou os Procedimentos Armazenados. Neste artigo, focaremos um pouco na mágica logo abaixo da superfície e discutiremos como isso pode afetar suas práticas de desenvolvimento e implantação. Essa é uma área do produto em que temos planos de evoluir e melhorar, portanto, não hesite em compartilhar suas opiniões e experiências usando a seção de comentários abaixo.
Escrever uma nova lógica de negócios é fácil e, supondo que você tenha APIs e especificações bem definidas, adaptá-la ou ampliá-la também costuma ser. No entanto, quando não é apenas lógica de negócios, mas também envolve dados persistentes, qualquer coisa que você alterar na versão inicial precisará ser capaz de lidar com os dados que foram ingeridos por essa versão anterior.
No InterSystems IRIS, os dados e código coexistem em um único mecanismo de alto desempenho, sem a meia dúzia de camadas de abstração que você vê em outras estruturas de programação 3GL ou 4GL. Isso significa que há apenas um mapeamento muito fino e transparente para traduzir as propriedades da sua classe para posições $list em um nó global por linha de dados ao usar o armazenamento padrão. Se você adicionar ou remover propriedades, não quer que os dados de uma propriedade removida apareçam em uma nova propriedade. É desse mapeamento das propriedades da sua classe que a Definição de Armazenamento cuida, um bloco de XML um pouco enigmático que você deve ter percebido na parte inferior da definição da sua classe. Na primeira vez que você compila uma classe, uma nova Definição de Armazenamento é gerada com base nas propriedades e nos parâmetros da classe. Quando você faz alterações na definição da classe, no momento da recompilação, essas alterações são reconciliadas com a Definição de Armazenamento existente e alteradas para manter a compatibilidade com os dados existentes. Assim, enquanto você se esforça para refatorar as classes, a Definição de Armazenamento considera cuidadosamente sua criatividade anterior e garante que os dados antigos e novos permaneçam acessíveis. Chamamos isso de evolução de esquema.
Na maioria dos outros bancos de dados SQL, o armazenamento físico das tabelas é muito mais opaco, se visível, e as alterações só podem ser feitas por declarações ALTER TABLE. Esses são comandos de DDL (linguagem de definição de dados) padrão, mas normalmente são muito menos expressivos do que é possível alcançar ao modificar uma definição de classe e um código de procedimento diretamente no IRIS.
Na InterSystems, nos esforçamos para oferecer aos desenvolvedores do IRIS a capacidade de separar de forma limpa o código e os dados, pois isso é crucial para garantir o empacotamento e a implantação suave dos aplicativos. A Definição de Armazenamento desempenha uma função única nisso, pois captura como um mapeia para o outro. Por isso, vale a pena examinar mais a fundo o contexto de práticas gerais de desenvolvimento e pipelines de CI/CD em particular.
No século atual, o gerenciamento de código-fonte é baseado em arquivos, então vamos primeiro analisar o formato principal de exportação de arquivos do IRIS. A Linguagem de Descrição Universal (Universal Description Language ou UDL, na sigla em inglês) pretende, como o nome sugere, ser um formato de arquivo universal para todo e qualquer código que você escrever no InterSystems IRIS. É o formato de exportação padrão ao trabalhar com o plug-in VS Code ObjectScript e leva a arquivos fáceis de ler que parecem quase iguais ao que você veria em um IDE, com um arquivo .cls individual para cada classe (tabela) no seu aplicativo. Você pode usar $SYSTEM.OBJ.Export() para criar arquivos UDL explicitamente ou apenas aproveitar a integração do VS Code.
Da época do Studio, talvez você se lembre de um formato XML que capturava as mesmas informações do UDL e permitia agrupar várias classes em uma única exportação. Embora essa última parte seja conveniente em alguns cenários, é muito menos prático ler e rastrear diferenças entre versões, então vamos ignorá-la por enquanto.
Como a UDL é destinada a capturar tudo o que o IRIS pode expressar sobre uma classe, ela incluirá todos os elementos de uma definição de classe, incluindo a Definição de Armazenamento completa. Ao importar uma definição de classe que já inclui uma Definição de Armazenamento, o IRIS verificará se essa Definição de Armazenamento abrange todas as propriedades e índices da classe e, se for o caso, usará no estado em que está e substituirá a Definição anterior para essa classe. Isso torna a UDL um formato prático para o gerenciamento de versões das classes e a Definição de Armazenamento, pois preserva essa compatibilidade para dados ingeridos por versões anteriores da classe, onde quer que você implante.
Se você é um desenvolvedor hardcore, talvez se pergunte se essas Definições de Armazenamento continuam crescendo e se essa "bagagem" precisa ser transportada indefinidamente. O objetivo das Definições de Armazenamento é preservar a compatibilidade com dados pré-existentes, portanto, se você sabe que não há nada disso e quiser se livrar de uma genealogia longa, pode "redefinir" a Definição de Armazenamento ao removê-la da definição da classe e gerar outra com o compilador da classe. Por exemplo, você pode usar isso para aproveitar novas práticas recomendadas, como o uso de Conjuntos de Extensão, que implementam nomes globais com hash e separam cada índice em um próprio global, melhorando as eficiências de baixo nível. Para a compatibilidade com versões anteriores nos aplicativos dos clientes, não podemos mudar universalmente esses padrões na superclasse %Persistent (embora os aplicaremos ao criar uma tabela do zero usando o comando DDL CREATE TABLE). Portanto, uma revisão periódica das classes e do armazenamento vale a pena. Também é possível editar o XML de Definição de Armazenamento diretamente, mas os usuários precisam ter muito cuidado, pois isso pode tornar os dados existentes inacessíveis.
Até aqui, tudo bem. As Definições de Armazenamento oferecem um mapeamento inteligente entre suas classes e se adaptam automaticamente com a evolução do esquema. O que mais tem lá?
Como você provavelmente sabe, o mecanismo SQL do InterSystems IRIS faz o uso avançado de estatísticas de tabela para identificar o plano de consulta ideal para qualquer declaração executada pelo usuário. As estatísticas de tabela incluem métricas sobre o tamanho de uma tabela, como os valores são distribuídos em uma coluna e muito mais. Essas informações ajudam o otimizador de SQL do IRIS a decidir qual índice é mais vantajoso, em que ordem unir as tabelas, etc. Portanto, intuitivamente, quanto mais atualizadas as estatísticas estiverem, maiores serão as chances de planos de consulta ideais. Infelizmente, até a introdução da amostragem de bloco rápida no IRIS 2021.2, coletar estatísticas de tabela precisas costumava ser uma operação computacionalmente cara. Portanto, quando os clientes implantavam o mesmo aplicativo em vários ambientes com padrões de dados basicamente iguais, fazia sentido considerar as estatísticas de tabela como parte do código do aplicativo e incluí-las nas definições da tabela.
Por isso, no IRIS hoje você encontra as estatísticas de tabela incorporadas à Definição de Armazenamento. Ao coletar estatísticas de tabela por uma chamada manual para TUNE TABLE ou de maneira implícita pela consulta (veja abaixo), as novas estatísticas são gravadas na Definição de Armazenamento e os planos de consulta existentes para essa tabela são invalidados, para que possam aproveitar as novas estatísticas durante a próxima execução. Por serem parte da Definição de Armazenamento, essas estatísticas farão parte das exportações de classe UDL e, portanto, podem acabar no seu repositório de código-fonte. No caso de estatísticas cuidadosamente verificadas para um aplicativo empacotado, isso é desejado, pois você quer que essas estatísticas específicas levem à geração do plano de consulta para todas as implantações do aplicativo.
A partir de 2021.2, o IRIS coletará automaticamente as estatísticas de tabela no início do planejamento de consulta ao consultar uma tabela que não possui nenhuma estatística e está qualificada para a amostragem de bloco rápida. Nos nossos testes, os benefícios de trabalhar com estatísticas atualizadas em vez de nenhuma estatística superaram claramente o custo da coleta de estatísticas em tempo real. Para alguns clientes, no entanto, isso teve o lamentável efeito colateral das estatísticas coletadas automaticamente na instância do desenvolvedor terminarem na Definição de Armazenamento no sistema de controle de fonte e, por fim, no aplicativo empacotado. Obviamente, os dados nesse ambiente de desenvolvedor e, portanto, as estatísticas nele talvez não sejam representativos para uma implantação real do cliente e levem a planos de consulta abaixo do ideal.
É fácil evitar essa situação. As estatísticas de tabela podem ser excluídas da exportação da definição de classe usando o qualificador /exportselectivity=0 ao chamar $SYSTEM.OBJ.Export(). O padrão do sistema para essa sinalização pode ser configurado usando $SYSTEM.OBJ.SetQualifiers("/exportselectivity=0"). Depois, deixe para a coleta automática na eventual implantação coletar estatísticas representativas, tornar a coleta de estatísticas explícitas parte do processo de implantação, o que substituirá qualquer coisa que possa ter sido empacotada com o aplicativo, ou gerenciar suas estatísticas de tabela separadamente pelas próprias funções de importação/exportação: $SYSTEM.SQL.Stats.Table.Export() e Import().
A longo prazo, pretendemos mover as estatísticas de tabela para ficar com os dados, em vez de fazer parte do código, e diferenciar mais claramente entre quaisquer estatísticas configuradas explicitamente por um desenvolvedor e as coletadas de dados reais. Além disso, estamos planejando mais automação em relação à atualização periódica dessas estatísticas, com base em quanto os dados da tabela mudam ao longo do tempo.
Neste artigo, descrevemos a função de uma Definição de Armazenamento no mecanismo ObjectRelational do IRIS, como ela é compatível com a evolução do esquema e o que significa incluí-la no seu sistema de controle de fonte. Também descrevemos por que as estatísticas de tabela são atualmente armazenadas nessa Definição de Armazenamento e sugerimos práticas de desenvolvimento para garantir que as implantações de aplicativos acabem com estatísticas representativas dos dados reais do cliente. Conforme mencionado anteriormente, planejamos aprimorar ainda mais esses recursos. Portanto, aguardamos seu feedback sobre a funcionalidade atual e planejada para refinar nosso design conforme apropriado.
A equipe de Plataforma de Dados está muito grata em anunciar o lançamento da versão 2021.2 da Plataforma de Dados InterSystems IRIS, InterSystems IRIS for Health e HealthShare Health Connect, que se encontra agora disponível para nossos clientes e parceiros.
A nova versão 2021.2 da Plataforma de Dados InterSystems IRIS torna ainda mais fácil o desenvolvimento, implantação e gestão de aplicações de alta capacidade e de processos de negócio que juntam dados e silos de aplicativos. Ela possui várias funcionalidades novas, incluindo:
Suponha que você desenvolveu uma nova aplicação utilizando a parte de Interoperabilidade do InterSystems IRIS e você tem certeza de que será um sucesso! No entanto, você ainda não tem um número concreto de quantas pessoas irão utilizá-la. Além disso, pode haver dias específicos em que há mais pessoas utilizando sua aplicação e dias em que quase ninguém irá acessar. Deste modo, você necessita de que sua aplicação seja escalável!
Estou muito grato em anunciar o lançamento do InterSystems Container Registry. Este lançamento disponibiliza um novo canal de distribuição para que clientes possam acessar lançamentos é prévias de lançamentos baseadas em contêineres. Todas as imagens Community Edition estão disponíveis em um repositório público sem necessidade de login. Todas as imagens de produto completos (IRIS, IRIS for Health, Health Connect, System Alerting and Monitoring, InterSystems Cloud Manager) e imagens utilitárias (como o árbitro, Web Gateway e PasswordHash) necessitam de token de login, gerado a partir das credenciais de sua conta do WRC.
Suponha que você desenvolveu uma nova aplicação utilizando a parte de Interoperabilidade do InterSystems IRIS e você tem certeza de que será um sucesso! No entanto, você ainda não tem um número concreto de quantas pessoas irão utilizá-la. Além disso, pode haver dias específicos em que há mais pessoas utilizando sua aplicação e dias em que quase ninguém irá acessar. Deste modo, você necessita de que sua aplicação seja escalável!
Com a transformação digital no mundo dos negócios, novos recursos ou funcionalidades nos softwares oferecidos por uma empresa, podem significar vantagem competitiva. No entanto, se o time de TI não estiver preparado com a cultura, metodologia, práticas e ferramentas corretas, pode ser muito difícil garantir a entrega dessas novas funcionalidades a tempo hábil.