 .
.
Estou muito emocionado de continuar com a minha série de artigos "InterSystems para Dummies", e hoje queremos contar tudo sobre uma das funções mais potentes que temos para a interoperabilidade.
Mesmo que já as tenha utilizado, planejamos analisar a fundo como aproveitá-las ao máximo e melhorar ainda mais nossa produção.
O que é um Record Mapper?
Essencialmente, um Record Mapper é uma ferramenta que permite mapear dados de arquivos de texto a mensagens de produção e vice-versa. A inteface do Portal de Administração, por outro lado, permite criar uma representação visual de um arquivo de texto e um modelo de objeto válido desses dados para mapear-los a um único objeto de mensagem de produção persistente.
Portanto, se você deseja importar dados de um arquivo CSV à sua classe persistente, pode tentar com um par de classes de entrada (por FTP ou diretório de arquivos). Mas não se apresse! Vamos abordar cada um desses pontos no seu devido tempo.
TIP: Todos os exemplos e classes descritos nessse artigo podem ser baixados no seguinte link: https://github.com/KurroLopez/iris-recordmap-fordummies.git
Como começar?
Vou direto ao ponto e especifico nosso cenário.
Precisamos importar informações de nossos clientes, incluindo seu nome, data de nascimento, número de identificação nacional, endereço, cidade e país.
Abra seu portal IRIS e selecione Interoperabilidade – Criar – Record Maps.

Crie um novo Record Maps com o nome do pacote e a classe.

Em nosso exemplo, o nome do pacote é Demo.Data, enquanto o nome da classe é es PersonalInfo.
O primeiro passo é configurar o arquivo CSV. Isso significa determinar o caractere separador, se os campos de string têm aspas duplas, etc.
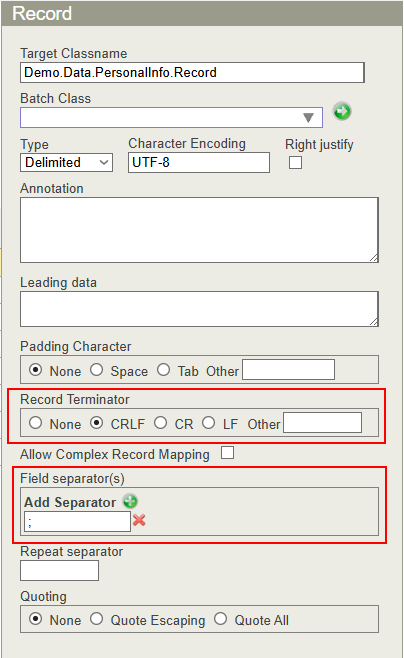
Se você usa o sistema operacional Windows, o terminador de registro comum é CRLF (Char(10) Char(12)).
Como meu arquivo CSV é padrão, separado por ponto e vírgula (;), devo definir o caractere do separador de campos.
Agora, vou declarar os campos do perfil do cliente (nome, sobrenome, data de nascimento, número de identificação nacional, endereço, cidade e país).

Esta é uma definição básica, mas você pode estabelecer mais condições em relação ao seu arquivo CSV, se desejar.

Lembre-se de que, por padrão, um campo %String tem um comprimento máximo de 50 caracteres. Portanto, atualizarei este valor para permitir mais caracteres no campo de endereço (um máximo de 100).
Também definirei o formato de data usando o formato ISO (aaaa-mm-dd), que corresponde ao número 3.
Além disso, tornarei os campos Nome, Sobrenome e Data de Nascimento obrigatórios.

Pronto! Vamos pressionar o botão "Gerar" para criar a classe persistente!

Dê uma olhada na classe gerada:
/// THIS IS GENERATED CODE. DO NOT EDIT.
/// RECORDMAP: Generated from RecordMap 'Demo.Data.PersonalInfo'
/// on 2025-07-14 at 08:37:00.646 [2025-07-14 08:37:00.646 UTC]
/// by user SuperUser
Class Demo.Data.PersonalInfo.Record Extends (%Persistent, %XML.Adaptor, Ens.Request, EnsLib.RecordMap.Base) [ Inheritance = right, ProcedureBlock ]
{
Parameter INCLUDETOPFIELDS = 1;
Property Name As %String [ Required ];
Property Surname As %String [ Required ];
Property DateOfBirth As %Date(FORMAT = 3) [ Required ];
Property NationalId As %String;
Property Address As %String(MAXLEN = 100);
Property City As %String;
Property Country As %String;
Parameter RECORDMAPGENERATED = 1;
Storage Default
{
<Data name="RecordDefaultData">
<Value name="1">
<Value>%%CLASSNAME</Value>
</Value>
<Value name="2">
<Value>Name</Value>
</Value>
<Value name="3">
<Value>%Source</Value>
</Value>
<Value name="4">
<Value>DateOfBirth</Value>
</Value>
<Value name="5">
<Value>NationalId</Value>
</Value>
<Value name="6">
<Value>Address</Value>
</Value>
<Value name="7">
<Value>City</Value>
</Value>
<Value name="8">
<Value>Country</Value>
</Value>
<Value name="9">
<Value>Surname</Value>
</Value>
</Data>
<DataLocation>^Demo.Data.PersonalInfo.RecordD</DataLocation>
<DefaultData>RecordDefaultData</DefaultData>
<ExtentSize>2000000</ExtentSize>
<IdLocation>^Demo.Data.PersonalInfo.RecordD</IdLocation>
<IndexLocation>^Demo.Data.PersonalInfo.RecordI</IndexLocation>
<StreamLocation>^Demo.Data.PersonalInfo.RecordS</StreamLocation>
<Type>%Storage.Persistent</Type>
}
}
Como você pode ver, cada propriedade tem o nome dos campos em nosso arquivo CSV.
Neste ponto, criaremos um arquivo CSV com a seguinte estrutura para testar nosso Record Mapper:
Name;Surname;DateOfBirth;NationalId;Address;City;Country Matthew O.;Wellington;1964-31-07;208-36-1552;1485 Stiles Street;Pittsburgh;USA Deena C.;Nixon;1997-03-03;495-26-8850;1868 Mandan Road;Columbia;USA Florence L.;Guyton;2005-04-10;21 069 835 790;Invalidenstrasse 82;Contwig;Germany Maximilian;Hahn;1945-10-17;92 871 402 258;Boxhagener Str. 97;Hamburg;Germany Amelio;Toledo Zavala;1976-06-07;93789292F;Plaza Mayor, 71;Carbajosa de la Sagrada;Spain
Você pode usá-lo como teste agora.
Clique em "Selecionar arquivo de amostra" selecione a amostra em /irisrun/repo/Samples e escolha PersonalInfo-Test.csv.

Neste momento, você poderá observar como seus dados são importados:

Os Problemas Aumentam
Justo quando você pensa que está tudo pronto, você recebe uma nova especificação do seu chefe:
"Precisamos dos dados para poder carregar o número de telefone do cliente e armazenar mais de um (fixo, celular, etc.)".
Ops... Preciso atualizar meu Record Map e adicionar um número de telefone. No entanto, deve haver mais de um... Como posso fazer isso?
Nota: Você pode fazer isso diretamente na mesma classe. No entanto, criarei uma nova para fins explicativos e a salvarei nos exemplos. Desta forma, você pode revisar e executar o código seguindo todos os passos deste artigo.
Bem, é hora de reabrir o Record Map que acabamos de criar.
Adicione o novo campo "Phone", mas lembre-se de indicar que este campo é "Repetido".

Como atribuímos este campo como "Repetido", devemos definir o caractere separador para os dados replicados. Este indicador está no mesmo lugar onde normalmente especificamos o separador de campo.

Perfeito! Vamos carregar o arquivo CSV de exemplo com os números de telefone separados por #.

Se dermos uma olhada na classe persistente que produzimos, podemos ver que o campo "Phone" é do tipo %String:
Property Phone As list Of %String(MAXLEN = 20);
Ok, Kurro, mas como podemos enviar este arquivo?
Essa é uma pergunta muito boa, caro leitor.
O InterSystems IRIS nos fornece duas classes de entrada (inbound): EnsLib.RecordMap.Service.FileServiceEnsLib.RecordMap.Service.FTPService
Não vou me aprofundar nessas classes porque seria muito longo. No entanto, podemos revisar suas funções principais.
Em resumo, o serviço monitora os processos em uma pasta definida, captura os arquivos armazenados nesse diretório, os carrega, os lê linha por linha e envia esse registro para o Processo de Negócio designado.
Isso ocorre tanto no servidor quanto nos diretórios FTP.
Vamos ao que interessa...
Nota: Apresentarei meus exemplos usando a classeEnsLib.RecordMap.Service.FileService. No entanto, a classe EnsLib.RecordMap.Service.FTPService realiza as mesmas operações.
Se você baixou o código de exemplo, verá que uma produção foi criada com dois componentes:
Uma classe de Serviço (EnsLib.RecordMap.Service.FileService), que carregará os arquivos, e uma classe de Negócio (Demo.BP.ProcessData),que processará cada um dos registros lidos do arquivo. Neste caso, usaremos este último apenas para ver os rastros de comunicação.
É importante configurar alguns parâmetros na classe do Business Service.

File Path: É um registro que a classe usa para monitorar se há arquivos pendentes de processamento. Ao colocar um arquivo neste diretório, o processo de carregamento é ativado automaticamente e envia cada registro para a classe definida como Processo de Negócios.
File Spec: É um padrão de arquivo para buscar (por padrão, é *, mas podemos definir alguns arquivos que desejamos diferenciar de outros processos). Por exemplo, podemos ter duas classes de escuta de entrada no mesmo diretório, cada uma com uma classe RecordMap diferente. Podemos atribuir a extensão .pi1 aos arquivos que a classe PersonalInfo processará, enquanto .pi2 marcará os arquivos que serão processados pela classe PersonalInfoPhone.
Archive Path: É um diretório onde os arquivos são movidos após serem processados.
Work Path: É um caminho onde o adaptador deve colocar o arquivo de entrada enquanto processa os dados. Esta configuração é útil quando se usa o mesmo nome de arquivo para envios repetidos. Se o WorkPath não for especificado, o adaptador não moverá o arquivo durante o processamento.
Call Interval: É a frequência (calculada em segundos) das verificações do adaptador para os arquivos de entrada nos locais especificados.
RecordMap: É o nome da classe Record Map, que contém a definição dos dados no arquivo.
Target Config Name: É o nome do Processo de Negócio que manipula os dados armazenados no arquivo.

Subdirectory Levels: É um espaço onde o processo busca um novo arquivo. Por exemplo, se um processo adiciona um arquivo a cada dia (segunda, terça, quarta, quinta e sexta), ele buscará em todos os subdiretórios, começando pelo diretório raiz, sempre que especificarmos o nível 1. Por padrão, o nível 0 significa que ele buscará apenas no diretório raiz.
Delete From Server: Esta função indica que, se o diretório dos arquivos processados não for especificado, o arquivo será excluído do diretório raiz.
File Access Timeout: É um tempo definido (calculado em segundos) para acessar o arquivo. Se o arquivo for somente leitura ou houver algum problema que impeça o acesso ao diretório, será exibido um erro.
Header Count:: É uma característica importante que indica o número de cabeçalhos que devem ser ignorados. Por exemplo, se o arquivo tiver um cabeçalho que especifica os campos que contém, você deve indicar quantas linhas de cabeçalho ele contém para que possam ser ignoradas e apenas as linhas de dados possam ser lidas.
Carregar um Arquivo
Como mencionei anteriormente, o processo de carregamento é ativado quando um arquivo é colocado no diretório do processo
Nota: As seguintes instruções são baseadas no código de exemplo. Na pasta "samples", você encontrará o arquivo PersonalInfoPhone-Test.csv. Você deve copiar este arquivo para a pasta do processo para que ele seja processado automaticamente.
NOTA: Se estiver trabalhando com Docker, use o seguinte comando:
docker cp .\PersonalInfoPhone-Test.csv containerId:/opt/irisbuild/process/containerId é o ID do seu contêiner, ex: : docker cp .\PersonalInfoPhone-Test.csv 66f96b825d43398ba6a1edcb2f02942dc799d09f1b906627e0563b1392a58da1:/opt/irisbuild/process/`

Para cada registro, ele dispara uma chamada para o Processo de Negócio com todos os dados.

Excelente trabalho! Em apenas alguns passos, você conseguiu criar um processo que pode ler arquivos de um diretório e gerenciar esses dados de forma rápida e fácil. O que mais você poderia pedir aos seus processos de interoperabilidade?
Complex Record Map (Mapa de Registro Complexo)
Ninguém quer ter uma vida complexa, mas eu prometo que você vai se apaixonar pelos Complex Record Maps.
Os Complex Record Maps são exatamente o que o nome indica. Trata-se de uma combinação de vários Record Maps que nos fornece informações mais completas e estruturadas.
Imaginemos que nosso chefe nos contacta e nos apresenta os seguintes requisitos:
“Precisamos de informações do cliente com mais números de telefone, incluindo códigos de país e prefixos. Também precisamos de mais endereços de contato, incluindo códigos postais, países e nomes de estados.
Um cliente pode ter um número de telefone, dois ou nenhum”.
Se precisarmos de mais informações sobre números de telefone e endereços, como vimos anteriormente, incluir essas informações em uma única linha seria muito complicado. Vamos separar as diferentes partes de que precisamos:
- Informações do cliente necessárias.
- Números de telefone (de 0 a 5).
- Endereço postal (de 0 a 2).
Para cada seção, criaremos um apelido para diferenciar o tipo de informação que inclui.
Vamos construir cada seção:
Passo 1
Projete um novo Record Maps para as informações do cliente (Nome, Sobrenome, Data de Nascimento e Documento Nacional de Identidade) e inclua um identificador para indicar que se trata da seção USER.

O nome da seção deve ser único para os tipos de dados "USER", pois são responsáveis por configurar as colunas e posições de cada dado. O conteúdo deve ser semelhante ao seguinte: USER|Matthew O.;Wellington;1964-07-31;208-36-1552 Em NEGRITO, o nome da seção, em ITALICO, o conteúdo.
Passo 2 Crie as seções PHONE e ADDRESS para os números de telefone e os endereços postais.
Lembre-se de especificar o nome da seção e ativar a opção Complex Record Map.


Agora devemos ter três classes:
- Demo.Data.ComplexUser
- Demo.Data.ComplexPhone
- Demo.Data.ComplexAddress
Passo 3 Complete o Complex Record Map.
Abra a opção "Complex Record Maps":

A primeira coisa que vemos aqui é uma estrutura com um cabeçalho e um rodapé. O cabeçalho pode ser outro mapa de registros para armazenar informações do pacote de dados (por exemplo, informações do departamento do usuário, etc.).
Como estas seções são opcionais, vamos ignorá-las em nosso exemplo.

Defina o nome deste registro (por exemplo, PersonalInfo) e adicione novos registros para cada seção.

Se quisermos que uma das seções tenha repetições, devemos indicar os valores mínimos e máximos de repetição.

De acordo com as especificações anteriores, o arquivo com as informações se parecerá com isto:
USER|Matthew O.;Wellington;1964-07-31;208-36-1552
PHONE|1;305;2089160
PHONE|1;805;9473136
ADDR|1485 Stiles Street;Pittsburgh;15286;PA;USA
Se quisermos carregar um arquivo, precisamos de um serviço que possa ler este tipo de arquivos, e o InterSystems IRIS nos fornece duas classes de entrada para isso:
EnsLib.RecordMap.Service.ComplexBatchFileServiceEnsLib.RecordMap.Service.ComplexBatchFTPService Como mencionei anteriormente, usaremos a classe EnsLib.RecordMap.Service.ComplexBatchFileService como exemplo. No entanto, o processo para FTP é idêntico.
Utilize a mesma configuração que o Record Map, exceto pelo número de linha do cabeçalho, porque este tipo de arquivo não precisa de um:

Como mencionei anteriormente, o processo de carregamento é ativado quando um arquivo é colocado no diretório do processo.
Nota: As seguintes instruções são baseadas no código de exemplo.
Na pasta "samples", você encontrará o arquivo PersonalInfoComplex.txt. Você deve copiar este arquivo para a pasta do processo para que ele seja processado automaticamente.
NOTA: Se estiver trabalhando com o exemplo do Docker, utilize o seguinte comando:
docker cp .\ PersonalInfoComplex.txt containerId:/opt/irisbuild/process/p
containerId é o ID do seu contêiner, ex: docker cp .\ PersonalInfoComplex.txt 66f96b825d43398ba6a1edcb2f02942dc799d09f1b906627e0563b1392a58da1:/opt/irisbuild/process/
Aqui podemos ver cada linha chamando o Business Service:



Como você já deve ter notado, os Record Maps são uma ferramenta potente para importar dados de forma complexa e estruturada. Permitem salvar informações em tabelas relacionadas ou processar cada dado de forma independente.
Graças a esta ferramenta, você pode criar rapidamente processos de carregamento de dados em lote e armazená-los sem a necessidade de realizar leituras complexas de dados, separação de campos, validação de tipos de dados, etc.
Espero que este artigo seja útil.
Nos vemos no próximo "InterSystems para Dummies".
.jpg)
.png)


.png)