.png)
Olá, Comunidade,
Neste artigo, vou apresentar meu aplicativo iris-mlm-explainer
Esse aplicativo da Web se conecta ao InterSystems Cloud SQL para criar, treinar, validar e prever modelos de ML, fazer previsões e mostrar um painel com todos os modelos treinados e uma explicação sobre o funcionamento de um modelo de machine learning ajustado. O painel fornece plotagens interativas de desempenho do modelo, importância do recurso, contribuições do recurso para previsões individuais, plotagens de dependência parcial, valores SHAP (interação), visualização de árvores de decisões individuais etc.
Pré-requisitos
- Você precisa ter uma conta no InterSystems Cloud SQL.
- Você precisa ter o <a book="" en="" getting-started-installing-git="" git-scm.com="" https:="" v2="">Git</a> instalado localmente.
- Você precisa ter o <a downloads="" https:="" www.python.org="">Python3</a> instalado localmente.
Primeiros Passos
Vamos seguir as etapas abaixo para criar e visualizar o painel explicativo de um modelo:
Etapa 1 : fazer o git pull/clone do repositório
Etapa 2 : fazer login no portal de serviços do InterSystems Cloud SQL
-
Etapa 2.1 : adicionar e gerenciar arquivos
-
Etapa 2.2 : importar DDL e arquivos de dados
-
Etapa 2.3 : criar modelo
-
Etapa 2.4 : treinar modelo
-
Etapa 2.5 : validar modelo
Etapa 3 : ativar o ambiente virtual do Python
Etapa 4 : executar o aplicativo da Web para previsão
Etapa 5 : explorar e o painel explicativo
Etapa 1 : fazer o git pull/clone do repositório
Então, vamos começar com a primeira etapa
Crie uma pasta e faça o git pull/clone do repositório em qualquer diretório local
git clone https://github.com/mwaseem75/iris-mlm-explainer.git
Etapa 2 : fazer login no portal de serviços do InterSystems Cloud SQL
Faça login no InterSystems Cloud Service Portal
Selecione a implantação executada
Etapa 2.1 : adicionar e gerenciar arquivos
Clique em "Add and Manage Files" (Adicionar e gerenciar arquivos)
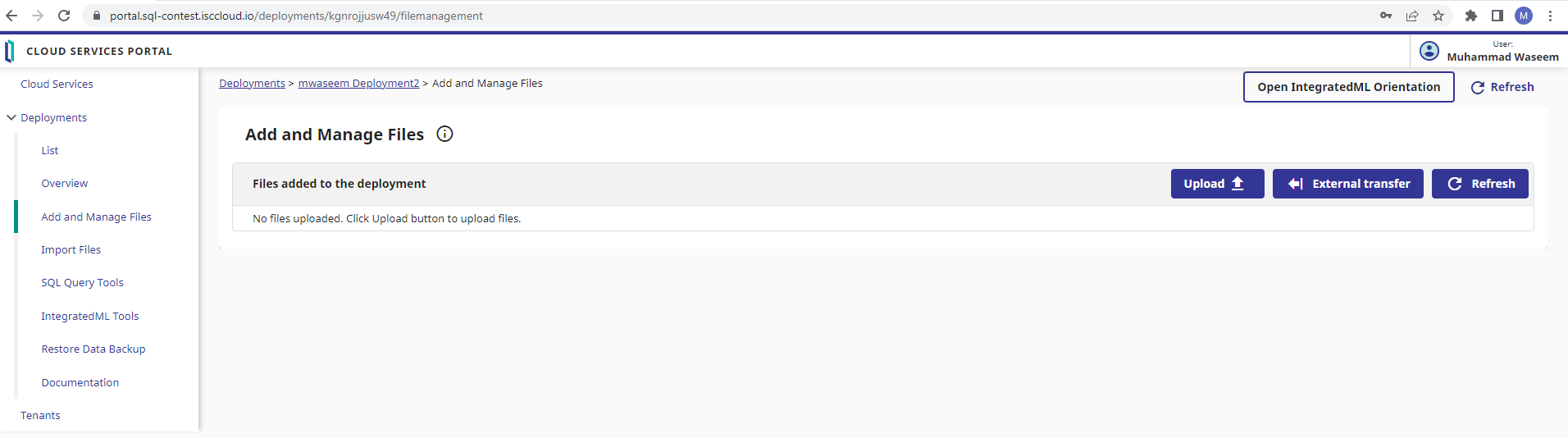
O repositório contém os arquivos USA_Housing_tables_DDL.sql(DDL para criar tabelas), USA_Housing_train.csv(dados de treinamento) e USA_Housing_validate.csv(para validação) na pasta de conjuntos de dados. Selecione o botão de upload para adicionar esses arquivos.

Etapa 2.2 : importar DDL e arquivos de dados
Clique em "Import files" (Importar arquivos), no botão de opção das declarações DDL ou DML e no botão "Next" (Próximo)

Clique no botão de opção do Intersystems IRIS e em "Next"

Selecione o arquivo USA_Housing_tables_DDL.sql e pressione o botão para importar arquivos

Clique em "Import" na caixa de diálogo de confirmação para criar a tabela

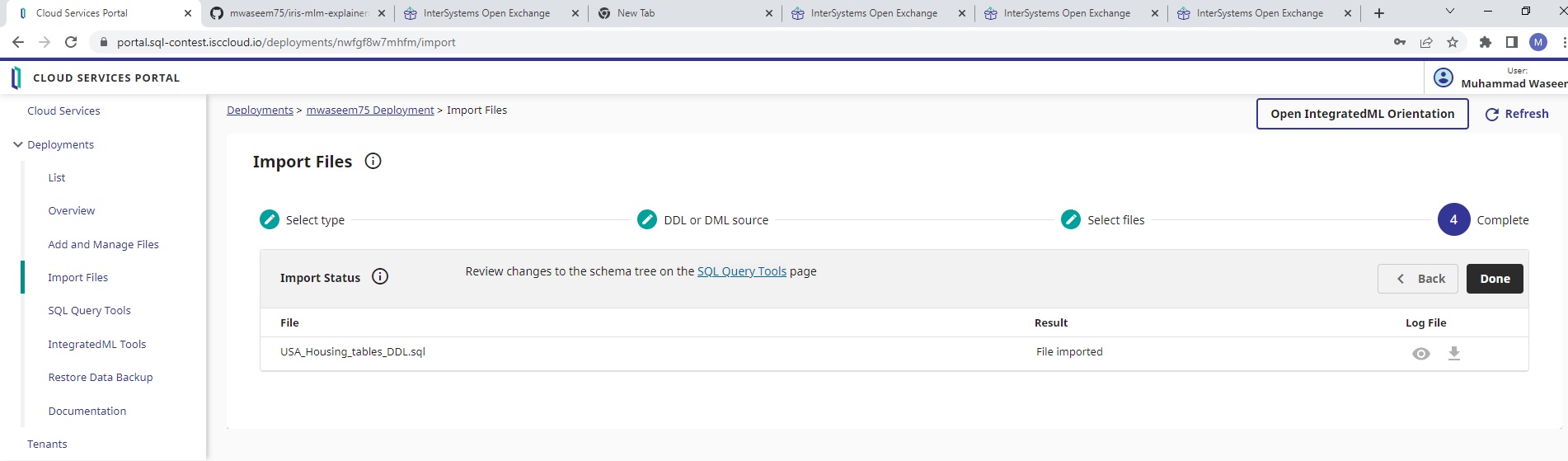
Clique nas ferramentas da Query em SQL para verificar se as tabelas foram criadas

Importar arquivos de dados
Clique em "Import files" (Importar arquivos), no botão de opção dos dados CSV e no botão "Next" (Próximo)

Selecione o arquivo USA_Housing_train.csv e clique no botão "Next"
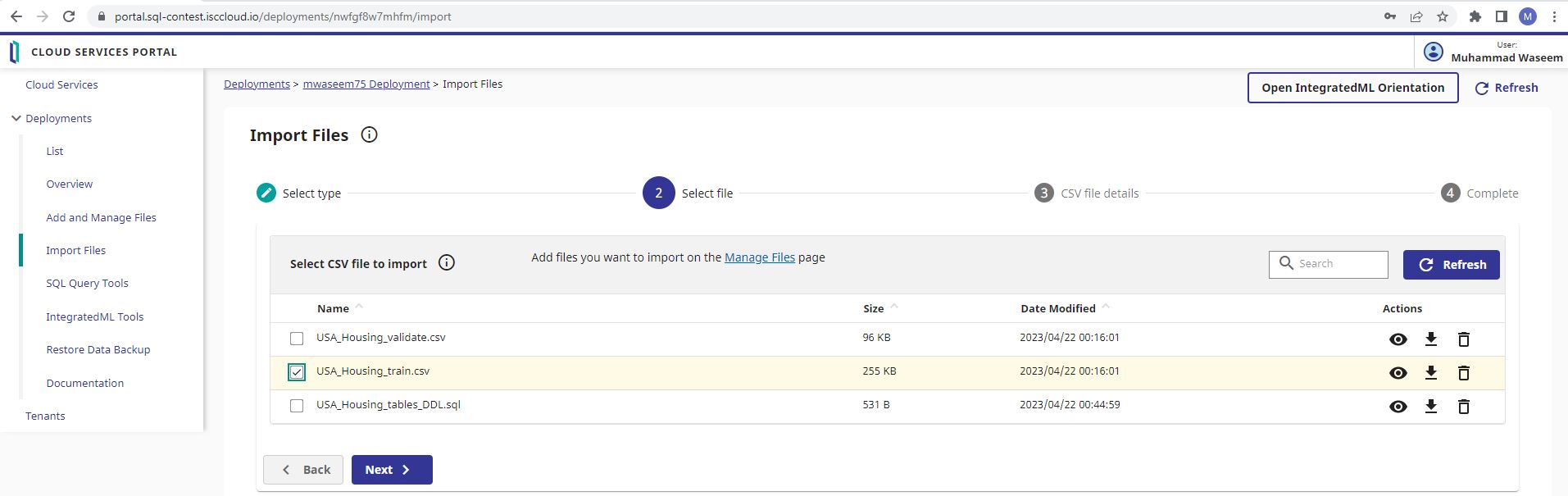
Selecione o arquivo USA_Housing_train.csv na lista suspensa, marque para importar o arquivo como linha de cabeçalho, selecione "Field names in header row match column names in selected table" (Os nomes dos campos na linha de cabeçalho correspondem aos nomes das colunas na tabela selecionada) e clique em "Import files"

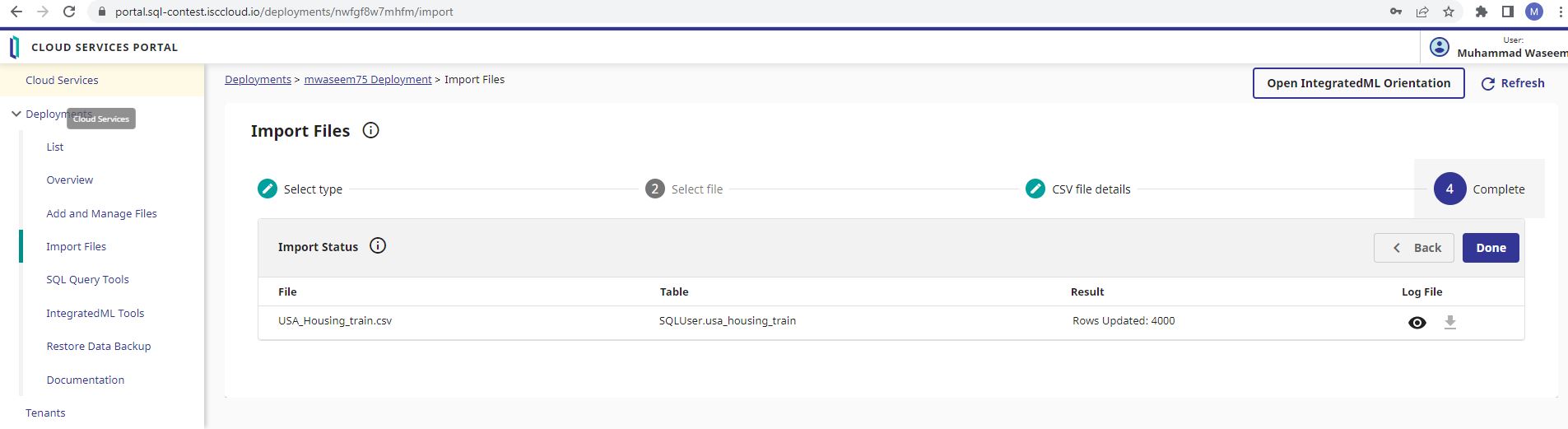
Clique em "Import" na caixa de diálogo de confirmação

Confira se 4000 linhas foram atualizadas
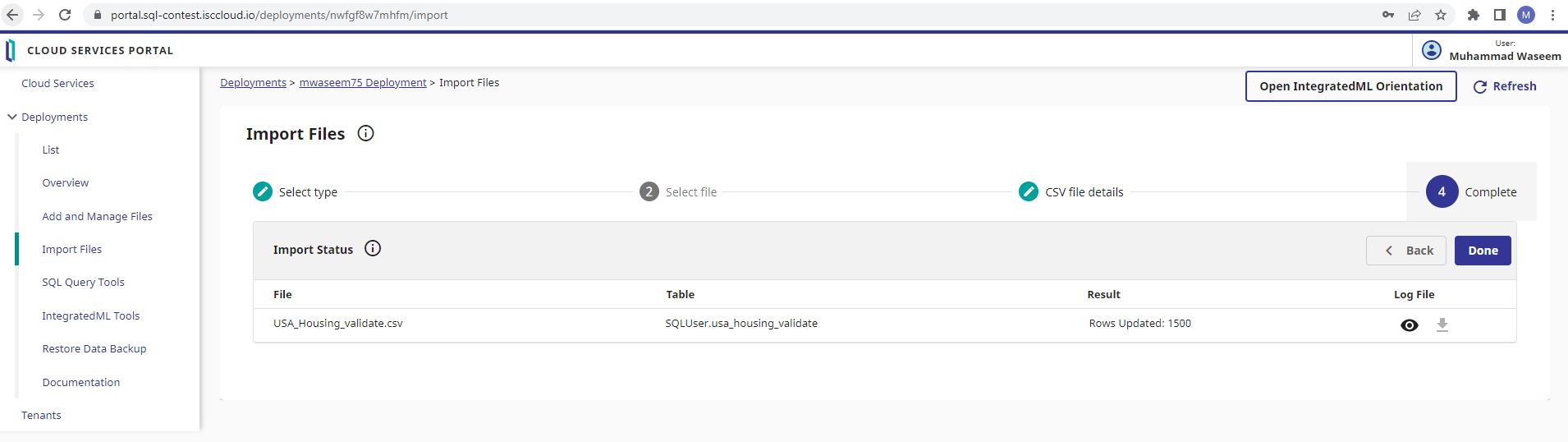
Repita as mesmas etapas para importar o arquivo USA_Housing_validate.csv, que contém 1500 registros
Etapa 2.3 : criar modelo
Clique em "IntegratedML tools" (ferramentas do IntegratedML) e selecione "Create Panel" (Criar painel).
Insira "USAHousingPriceModel" no campo de nome do modelo, selecione a tabela "usa_housing_train" e "Price" no menu suspenso "Field to predict" (Campo para prever). Clique no botão "Create model" para criar o modelo

Etapa 2.4 : treinar modelo
Selecione "Train Panel" (Treinar painel), escolha "USAHousingPriceModel" na lista suspensa "Model to train" (Modelo a treinar) e insira "USAHousingPriceModel_t1" no campo de nome do modelo a treinar

O modelo será treinado após a conclusão do status de execução

Etapa 2.5 : validar modelo
Selecione "Validate Panel" (Validar painel), escolha "USAHousingPriceModel_t1" na lista suspensa "Trained model to validate" (Modelo treinado a validar), selecione "usa_houseing_validate" na lista suspensa "Table to validate model from" (Tabela para validar o modelo) e clique no botão "Validate model" (Validar modelo)

Clique em "Show validation metrics" para ver as métricas

Clique no ícone de gráfico para ver o gráfico "Prediction VS Actual" (Previsão x Real)

Etapa 3 : ativar o ambiente virtual do Python
O repositório já contém uma pasta de ambiente virtual do python (venv) com as bibliotecas necessárias.
Tudo o que precisamos fazer é ativar o ambiente
No Unix ou MacOS:
$source venv/bin/activate
No Windows:
venv\scripts\activate
###Etapa 4 : definir parâmetros de conexão do InterSystems Cloud SQL
O repositório contém o arquivo config.py. Basta abrir e definir os parâmetros

Coloque os mesmos valores usados no InterSystems Cloud SQL

Etapa 4 : executar o aplicativo da Web para previsão
Execute o comando abaixo no ambiente virtual para iniciar nosso aplicativo principal
python app.py

Acesse http://127.0.0.1:5000/ para executar o aplicativo
Insira "Age of house" (Idade da casa), "No of rooms" (Nº de cômodos), "No of bedroom" (Nº de quartos) e "Area population" (População da área) para obter a previsão

Etapa 5 : explorar e o painel explicativo
Por fim, execute o comando abaixo no ambiente virtual para iniciar nosso aplicativo principal
python expdash.py


Acesse http://localhost:8050/ para executar o aplicativo

O aplicativo listará todos os modelos treinados com nosso "USAHousingPriceModel". Clique no hyperlink "Go to dashboard" (Acessar painel) para visualizar a explicação sobre o modelo
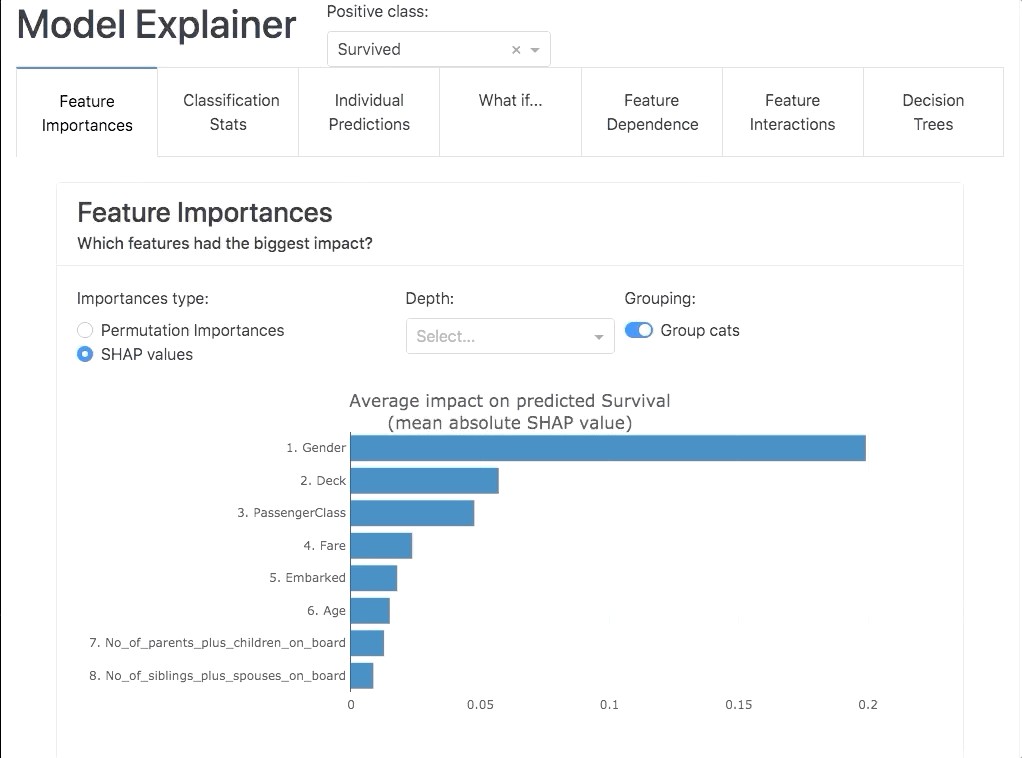
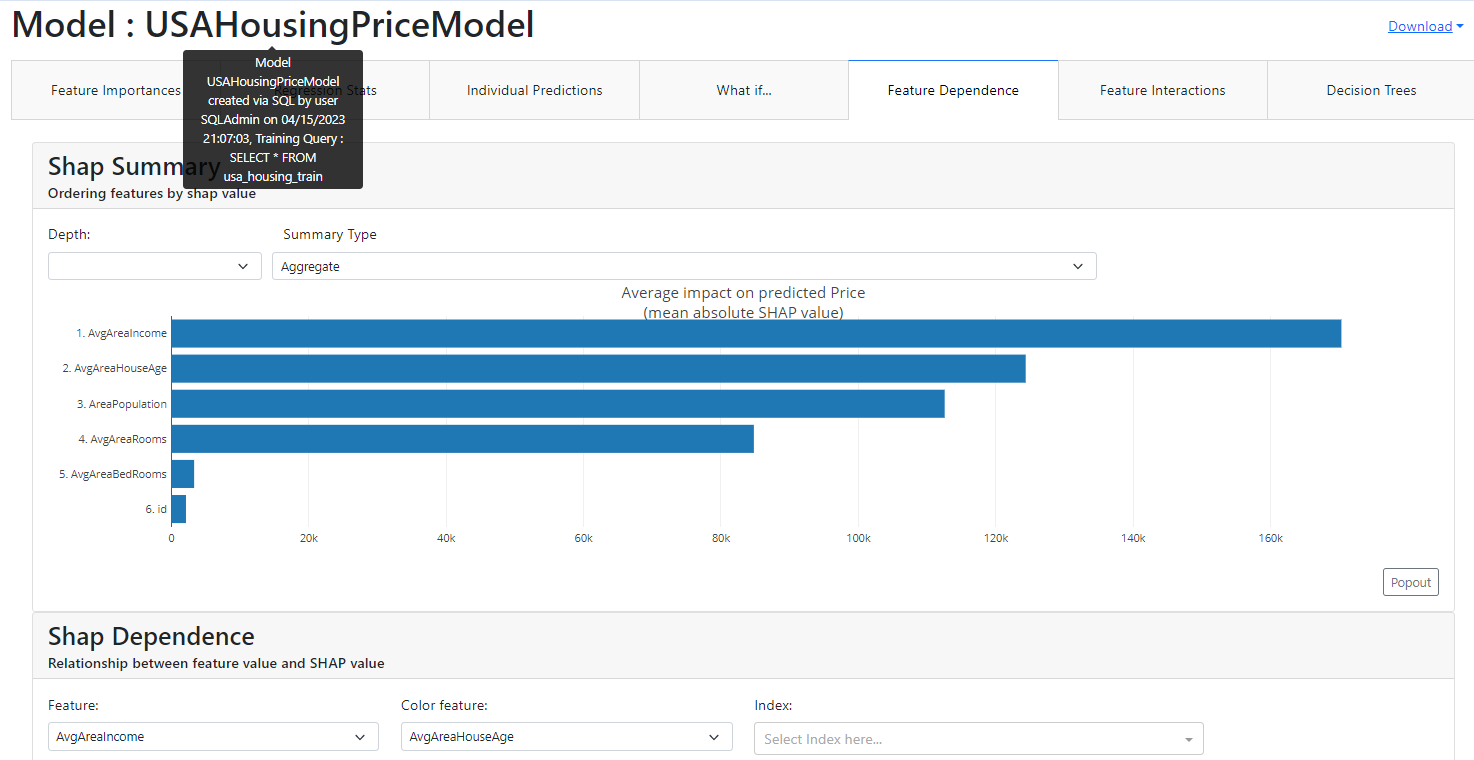
Importância dos recursos. Quais recursos tiveram o maior impacto?

Métricas quantitativas para o desempenho do modelo, Qual é a diferença entre o valor previsto e o observado?

Previsão e Como cada recurso contribuiu para a previsão?

Ajuste os valores dos recursos para mudar a previsão

Resumo Shap, Ordenamento dos recursos por valores shap
Resumo de interações, Ordenamento dos recursos por valor de interação shap

Árvores de decisões, Exibição de árvores de decisões individuais dentro do Random Forest

Obrigado





.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)













