Palavras-chave: ChatGPT, COS, Tabelas de consulta, IRIS, IA
Objetivo
Aqui está outra pequena observação antes de seguirmos para a jornada de automação assistida por GPT-4. Confira abaixo algumas "ajudinhas" que o ChatGPT já oferece, em várias áreas, durante as tarefas diárias.
Saiba também quais são as possíveis lacunas, riscos e armadilhas da automação assistida por LLMs, caso você explore esse caminho. Também adoraria ouvir os casos de uso e as experiências de outras pessoas nesse campo.
Tabelas de consulta
Uma das tarefas mais simples podem ser as tabelas de consulta. Com frequência, precisamos transformar tabelas de código Excel ou CSV em tabelas de consulta XML de forma manual. Principalmente, quando há espaços em branco e outros elementos distribuídos de maneira aleatória nos valores em milhares de registros, e você precisa organizá-los diversas vezes antes dos prazos de publicação.
O ChatGPT pode ajudar um pouco nisso? Aqui está um teste rápido.
Prompt:
Você é um programa que converte um arquivo CSV automaticamente em um arquivo de tabela de consulta XML.
A entrada é um arquivo CSV separado por vírgulas com 3 colunas de dados :
Blood Science ,XCOM,CANCELLED/REJECTED SAMPLE
Blood Science ,ADX ,ADD ON TEST COMMENT
Blood Transfusion,DARA,ALERT FOR DARA/CAMELLIA
Blood Transfusion, BT1 ,REJECT SAMPLE UNLABELLED
A saída deve ser um arquivo XML no seguinte formato:
<lookupTable>
<entry table="HIE.ICE.FilterOBR4" key="XCOM">Blood Science</entry>
<entry table="HIE.ICE.FilterOBR4" key="ADX ">Blood Science</entry>
<entry table="HIE.ICE.FilterOB
R4" key="DARA">Blood Transfusion</entry>
<entry table="HIE.ICE.FilterOBR4" key="BT1">Blood Transfusion</entry>
</lookupTable>
Observação: a sequência do atributo XML em cada raiz deve ser mantidaChatGPT:
Aqui está um script em Python que lê o arquivo CSV, o processa e gera o arquivo XML:
import csv
defconvert_csv_to_xml(input_file, output_file):"""
Convert a CSV file to an XML lookup table file.
Parameters:
input_file (str): Path to the input CSV file.
output_file (str): Path to the output XML file.
Returns:
int: 0 if the conversion was successful, 1 if there was an error.
"""try:
lookup_table = {}
with open(input_file, "r") as csvfile:
csvreader = csv.reader(csvfile)
for row in csvreader:
category = row[0].strip()
key = row[1].strip()
value = row[2].strip()
lookup_table[key] = category
with open(output_file, "w") as xmlfile:
xmlfile.write('<?xml version="1.0"?>\n')
xmlfile.write('<lookupTable>\n')
for key in lookup_table:
xmlfile.write(f'<entry table="HIE.ICE.FilterOBR4" key="{key}">{lookup_table[key]}</entry>\n')
xmlfile.write('</lookupTable>\n')
return0except Exception as e:
print("Error:", e)
return1
Esse script primeiro lê o arquivo CSV usando o módulo csv e cria um dicionário para manter os dados da tabela de consulta. Depois, ele processa cada linha do arquivo CSV e adiciona os dados relevantes ao dicionário.
Por fim, o script gera o arquivo XML ao iterar pelo dicionário e gravar as tags e os atributos XML apropriados no arquivo de saída. Veja que a sintaxe da string f é usada para inserir dinamicamente os dados da chave e da categoria nas tags XML.
Executei o script rapidamente em um Jupyter Notebook e deu certo. Ele também removeu todos os espaços em branco (seriam vários ajustes manuais). Ele ofereceu uma ferramenta para lidar com CSVs longos que têm valores confusos, sem limitação de tamanho do token.
Nesse caso específico, eu diria que a produtividade aumentou cerca de 20 vezes em relação às abordagens manuais repetidas para lidar com várias tabelas de código confusas.
Depois de economizar um pouco de tempo, eu queria saber se ele poderia gerar uma amostra de COS para criar a classe Util para BAUs de serviços futuros etc.
Prompt:
Você pode converter a função em Python acima para o ClassMethod do COS da InterSystems usando a função correta específica do COS?
ChatGPT:
Com certeza! Aqui está o código convertido para o ClassMethod do ObjectScript da InterSystems:
ClassMethod ConvertCSVToXML(inputFile As%String, outputFile As%String) As%Integer
{
try {
set lookupTable = {}
set csvReader = ##class(%File.CharacterStream).%New()
do csvReader.LinkToFile(inputFile)
while (csvReader.AtEnd = 0) {
set row = csvReader.ReadLine()
set category = $ZSTRIP($PIECE(row, ",", 1), "B")
set key = $ZSTRIP($PIECE(row, ",", 2), "B")
set value = $ZSTRIP($PIECE(row, ",", 3), "B")
set lookupTable(key) = category
}
do csvReader.%Close()
set xmlWriter = ##class(%File.CharacterStream).%New()
do xmlWriter.LinkToFile(outputFile)
do xmlWriter.WriteLine("<?xml version=""1.0""?>")
do xmlWriter.WriteLine("<lookupTable>")
set keys = lookupTable.%GetKeys()
while ('keys.%AtEnd) {
set key = keys.%GetNext()
set category = lookupTable(key)
do xmlWriter.WriteLine("<entry table=""HIE.ICE.FilterOBR4"" key="""_key_""">"_category_"</entry>")
}
do xmlWriter.WriteLine("</lookupTable>")
do xmlWriter.%Close()
quit0
}
catch (ex) {
Write"Error: "_ex.DisplayString(), !
quit1
}
}
No ObjectScript da InterSystems, podemos usar a classe %File.CharacterStream para ler e gravar arquivos. Usamos o método LinkToFile() para abrir os arquivos de entrada e saída, e depois usamos os métodos ReadLine() e WriteLine() para ler e gravar os dados nos arquivos.
Para remover os espaços à esquerda e à direita de cada campo, usamos a função $ZSTRIP() com a sinalização "B".
Também usamos o método %GetKeys() do objeto lookupTable para iterar as chaves no dicionário.
Por fim, o método retorna um código de status 0 se a conversão for bem-sucedida ou 1 se houver um erro.
Ele não fornece uma ferramenta correta que funciona de maneira tão imediata quanto o Python. %File.CharacterStream deve ser %Stream.FileCharacter, a remoção de espaços em branco deve usar "<>W", e a iteração pelos globais deve usar $ORDER etc. </p>
Os prompts podem ser melhorados, mas não sou muito bom em pedir favores, então fiz alguns ajustes rápidos durante o processo.
ClassMethod ConvertCSVToXML2(inputFile As%String, outputFile As%String) As%Integer
{
s tSC = $$$OKtry {
set^lookupTable = ""set csvReader = ##class(%Stream.FileCharacter).%New()
set tSC = csvReader.LinkToFile(inputFile)
while (csvReader.AtEnd = 0) {
set row = csvReader.ReadLine()
set category = $ZSTRIP($PIECE(row, ",", 1), "<>W")
set key = $ZSTRIP($PIECE(row, ",", 2), "<>W")
set value = $ZSTRIP($PIECE(row, ",", 3), "<>W")
set^lookupTable(key) = category
}
do csvReader.%Close()
set xmlWriter = ##class(%Stream.FileCharacter).%New()
set tSC = xmlWriter.LinkToFile(outputFile)
set tSC = xmlWriter.WriteLine("<?xml version=""1.0""?>")
set tSC = xmlWriter.WriteLine("<lookupTable>")
set key = $O(^lookupTable("")) while (key '= "") {
set category = $GET(^lookupTable(key))
w !,key, " ", category
set tSC = xmlWriter.WriteLine("<entry table=""HIE.ICE.FilterOBR4"" key="""_key_""">"_category_"</entry>")
set key = $O(^lookupTable(key))
}
set tSC = xmlWriter.WriteLine("</lookupTable>")
set tSC = xmlWriter.%Save("</lookupTable>")
set tSC = xmlWriter.%Close()
}
catch (ex) {
Write"Error: "_ex.DisplayString(), !
s tSC = ex
}
return tSC
}
Então, quais são as lacunas detectadas aqui?
Algumas possíveis implicações que vieram à minha mente:
1. Produtividade: a recompensa de produtividade dependeria da proficiência do COS do desenvolvedor. Essa ferramenta aumentaria ainda mais qualquer vantagem de proficiência em programação.
2. Lacunas: minha pergunta seria — como podemos aumentar a precisão pela aprendizagem few-shot via prompts, com ou até mesmo sem ajustes? Se você explora essa área em LLMs, eu adoraria ouvir suas ideias ou sonhos.
Gerações automáticas de testes de unidades
Ao discutir o desenvolvimento, não podemos escapar dos testes.
Parece que isso está mudando agora. Ferramentas polidas que parecem bastante "simples" e usam o poder dos GPTs, como RubberDuck, surgiram para ajudar.
Então, testei a extensão do RubberDuck no VSCode e configurei com minha chave da API OpenAI.
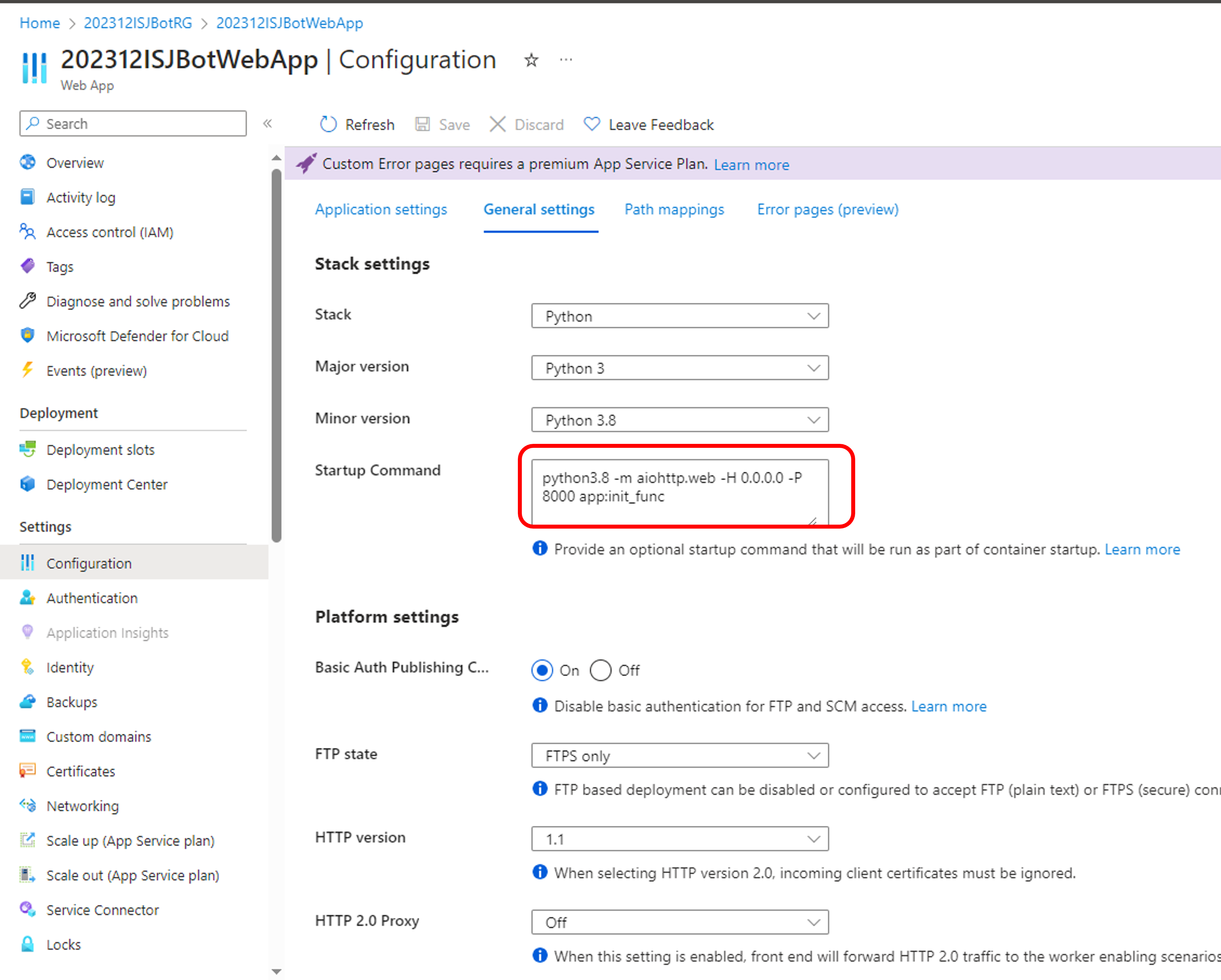
Depois, abri a função em Python mencionada acima no VSCode, conforme a seguir:
.png)
Em seguida, selecionei o menu "Generate Unit Test ...", que gera automaticamente uma cobertura de teste de unidade em alguns segundos, pelo menos 100 vezes mais rápido do que digitando. Ele fornece um marcador de posição rápido para ajustes.
.png)
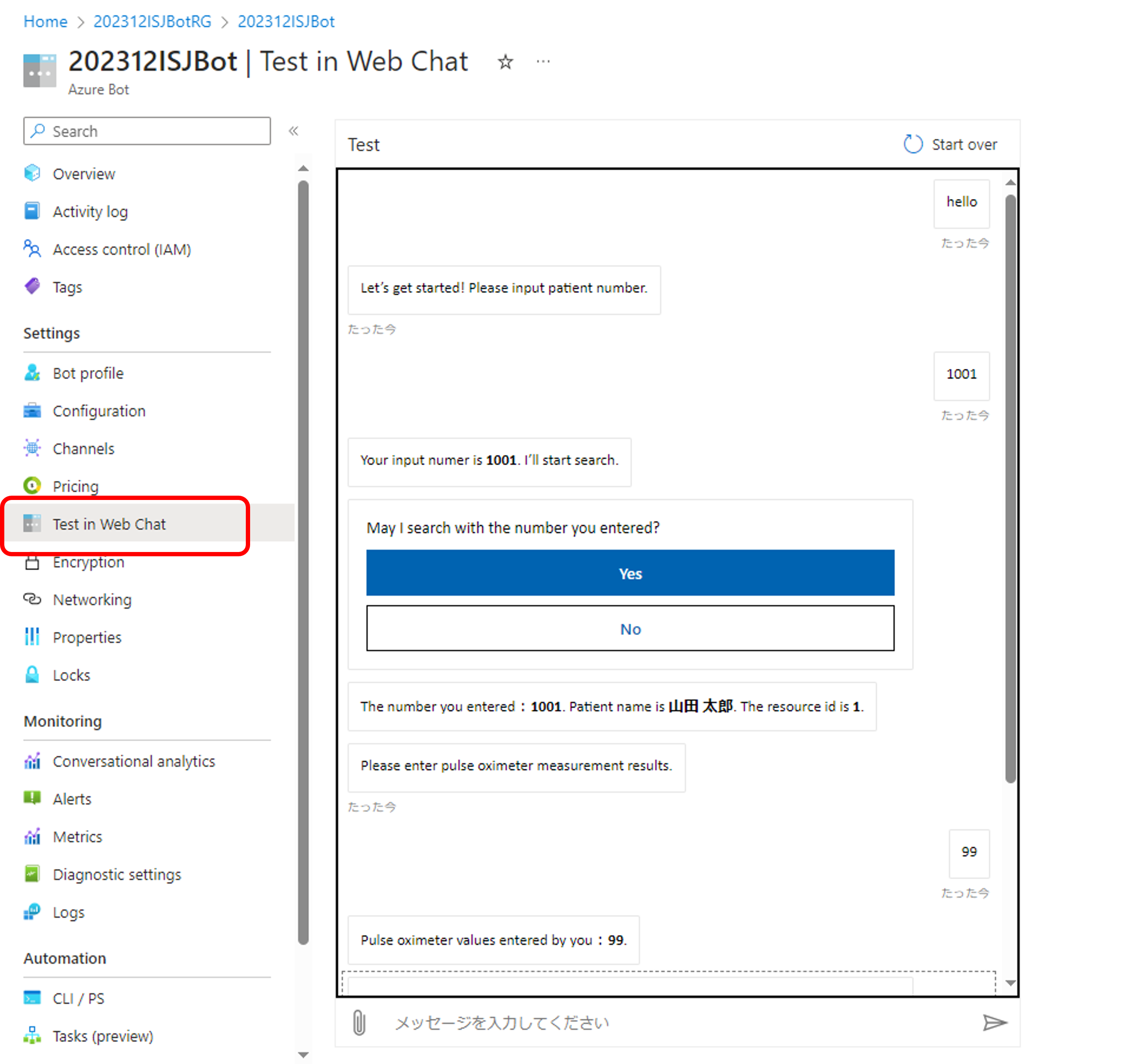
Podemos fazer isso para o código COS também, mesmo que o RubberDuck e o ChatGPT ainda não entendam realmente o COS (e não é culpa do LLM):
.png)
Ele gerou esse marcador de posição de teste de unidade sem entender muito bem o COS — deixarei as lacunas abertas para conselhos agora e, especialmente, se ou como as lacunas precisarão ser resolvidas com um senso de propósito.
.png)
Precisaria de alguns ajustes, mas, usando o ChatGPT, parece que agora ele consegue gerar, analisar e comentar automaticamente o código, além de gerar marcadores de posição de testes de unidade para você. (Bem, mais ou menos, dependendo da linguagem de programação usada e do que queremos que ele faça em seguida).
Conclusão?
Novamente, não tenho conclusões rápidas, já que ainda não consigo explorar muito os limites e as armadilhas.
Base matemática??
Talvez algum dia, assim como o conceito de "entropia" na teoria da informação foi criado em 1948, outro gênio da matemática possa simplesmente nos iluminar com outro conceito para quantificar as distâncias e lacunas "linguísticas" entre todos os tipos de linguagens, sejam humanas ou de máquina. Até lá, não saberemos realmente o potencial real, limites, riscos e armadilhas desses LLMs. Ainda assim, isso não parece impedir o avanço dos LLMs a cada mês ou semana.
Outros casos de uso??
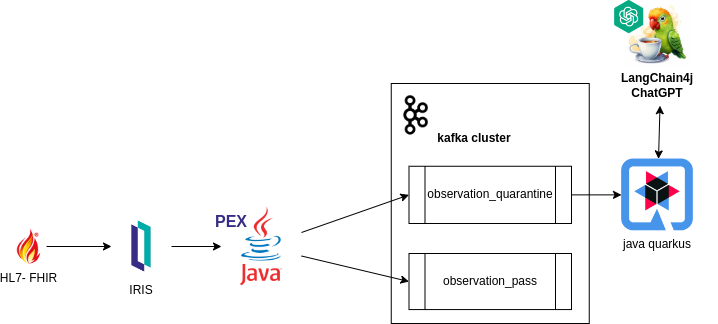
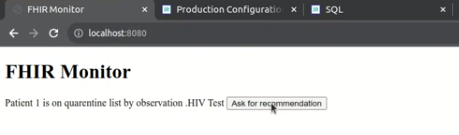
Painéis de análise baseados em consultas de linguagem natural humana: algumas semanas atrás, estava trabalhando na P&D de um projeto de inovação e, por acaso, percebi outro caso de uso: transformar consultas clínicas em linguagem humana em uma consulta de máquina em SQL/MDX. Na verdade, mais ou menos, sem qualquer ajuste ainda. Parece que ele está começando a aproximar linguagens humanas e tons de máquina, até certo ponto?
Não seria difícil imaginar uma situação assim: um médico digita uma consulta clínica em um chat na sua linguagem natural e um painel clínico é gerado automaticamente, destacando os pacientes que possam ter perdido a detecção precoce da insuficiência cardíaca, além de agrupar e classificar esses pacientes em regiões, gênero e faixas etárias. As diferenças na qualidade do cuidado seriam destacadas em minutos, em vez de meses de esforços de engenharia.
E, certamente, um assistente de IA personalizado de cuidados. Parecia tão remoto e complexo no ano passado, mas, ao que tudo indica, se torna rapidamente uma realidade com o GPT4. Teoricamente, nada impediria o GPT4 e os LLMs de analisarem meus registros de atendimento, apenas pedaços de dados estruturados e semiestruturados (como exames de laboratório e medicamentos), dados não estruturados (observações e relatórios clínicos etc.) e dados de imagem (raios X, tomografias e ressonâncias magnéticas), para começar a entender melhor e coordenar meus cuidados e consultas em breve.
Ressalva
Desculpe dizer o óbvio, mas o objetivo desta postagem não se trata de como podemos criar tabelas de consulta XML com rapidez, manualmente ou não. Na verdade, também sou muito bom com Excel e Notepad++. Em vez disso, o objetivo é entrar em contato com quem quer compartilhar casos de uso, reflexões, desafios, riscos e experiências na jornada das automações assistidas por LLMs etc.
E o poder dos LLMs veio dos desenvolvedores, de todos os repositórios públicos e das postagens que todos fizeram em fóruns públicos. GPTs não surgem do nada. Nos últimos meses, isso ainda não foi totalmente valorizado e reconhecido.
A AGI apresenta riscos à humanidade nessa velocidade, mas, pessoalmente, me sinto um pouco sortudo, aliviado e dispensado, já que estamos nos serviços de saúde.
Outros riscos rotineiros incluem a conformidade de privacidade de dados de acordo com a HIPPA, o GDPR e os Acordos de Processamento de Dados.
.png)
.png)
.png)






.png)

.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)


 Crie/use sua classe datatype
Crie/use sua classe datatype