As soluções de Infraestrutura Hiperconvergente (HCI) têm ganhado força nos últimos anos, com o número de implementações agora aumentando rapidamente. Os tomadores de decisão de TI estão considerando HCI ao planejar novas implementações ou atualizações de hardware, especialmente para aplicações já virtualizadas no VMware. As razões para escolher HCI incluem: lidar com um único fornecedor, interoperabilidade validada entre todos os componentes de hardware e software, alto desempenho, especialmente de IO (entrada/saída), escalabilidade simples pela adição de hosts, implementação simplificada e gerenciamento simplificado.
Escrevi este artigo com uma introdução para um leitor que é novo em HCI, analisando os recursos comuns das soluções de HCI. Em seguida, reviso as opções de configuração e recomendações para planejamento de capacidade e desempenho ao implementar aplicativos construídos na plataforma de dados InterSystems, com exemplos específicos para aplicativos de banco de dados. As soluções de HCI dependem do armazenamento flash para desempenho, por isso também incluo uma seção sobre as características e casos de uso de opções selecionadas de armazenamento flash.
O planejamento de capacidade e as recomendações de desempenho neste artigo são específicos para o VMWare vSAN. No entanto, o vSAN não está sozinho no crescente mercado de HCI; existem outros fornecedores de HCI, notóriamente a Nutanix que também possui um número crescente de implementações. Há muita similaridade entre os recursos, independentemente do fornecedor de HCI escolhido, então espero que as recomendações neste artigo sejam amplamente relevantes. Mas o melhor conselho em todos os casos é discutir as recomendações deste artigo com os fornecedores de HCI, levando em consideração os requisitos específicos de sua aplicação.
[Uma lista de outras publicações na série de Plataformas de Dados e desempenho da InterSystems está aqui.](https://community.intersystems.com/post/capacity-planning-and-performance-series-index)
# O que é HCI?
Estritamente falando, soluções convergentes existem há muito tempo, no entanto, nesta postagem, estou falando sobre as soluções HCI atuais, por exemplo, da Wikipedia: "A hiperconvergência se afasta de múltiplos sistemas discretos que são empacotados juntos e evoluem para ambientes inteligentes__ definidos por software__ que todos rodam em servidores rack x86 de prateleira, de uso geral...."
Então, HCI é uma coisa única?
Não. Ao conversar com fornecedores, você deve lembrar que o HCI tem muitas permutações; Convergido e hiperconvergido são mais um tipo de arquitetura, não um projeto ou padrão específico. Devido à natureza de commodity do hardware HCI, o mercado tem vários fornecedores se diferenciando na camada de software e/ou outras maneiras inovadoras de combinar computação, rede, armazenamento e gerenciamento.
Sem entrar muito em detalhes aqui, como exemplo, soluções rotuladas como HCI podem ter armazenamento dentro dos servidores em um cluster ou ter uma configuração mais tradicional com um cluster de servidores e armazenamento SAN separado – possivelmente de fornecedores diferentes – que também foi testado e validado para interoperabilidade e gerenciado a partir de um único painel de controle. Para planejamento de capacidade e desempenho, você deve considerar que soluções onde o armazenamento está em um array conectado por um fabric SAN (por exemplo, Fibre Channel ou Ethernet) têm um perfil de desempenho e requisitos diferentes do caso em que o pool de armazenamento é definido por software e localizado dentro de cada um dos nós do cluster de servidores com processamento de armazenamento nos servidores.
Então, o que é HCI novamente?
Para esta postagem, estou me concentrando em HCI e especificamente VMware vSAN onde o_armazenamento está fisicamente dentro dos servidores host._. Nessas soluções, a camada de software HCI permite que o armazenamento interno em cada um dos múltiplos nós em um cluster execute o processamento para agir como um sistema de armazenamento compartilhado. Portanto, outro fator impulsionador do HCI é que, mesmo que haja um custo para o software HCI, também pode haver economias significativas ao usar HCI em comparação com soluções que usam arrays de armazenamento corporativos.
Para esta postagem, estou falando sobre soluções onde o HCI combina computação, memória, armazenamento, rede e software de gerenciamento em um cluster de servidores x86 virtualizados.
Características comuns do HCI
Como mencionado acima, VMWare vSAN e Nutanix são exemplos de soluções HCI. Ambos têm abordagens de alto nível semelhantes para HCI e são bons exemplos do formato:
- VMware vSAN requer VMware vSphere e está disponível em hardware de vários fornecedores. Existem muitas opções de hardware disponíveis, mas estas são estritamente dependentes da Lista de Compatibilidade de Hardware (HCL) do vSAN da VMware. As soluções podem ser compradas pré-embaladas e pré-configuradas, por exemplo, EMC VxRail, ou você pode comprar componentes na HCL e construir o seu próprio.
- Nutanix também pode ser comprado e implantado como uma solução completa, incluindo hardware em blocos pré-configurados com até quatro nós em um appliance 2U. A solução Nutanix também está disponível como uma solução de software para construir o seu próprio, validada no hardware de outros fornecedores.
Existem algumas variações na implementação, mas, de modo geral, o HCI possui recursos comuns que informarão seu planejamento de desempenho e capacidade:
- Máquinas Virtuais (VMs) são executadas em hypervisors como VMware ESXi, mas também outros, incluindo Hyper-V ou Nutanix Acropolis Hypervisor (AHV). O Nutanix também pode ser implantado usando o ESXi.
- Os servidores host são frequentemente combinados em blocos de computação, armazenamento e rede. Por exemplo, um Appliance 2U com quatro nós.
- Vários servidores host são combinados em um cluster para gerenciamento e disponibilidade.
- O armazenamento é em camadas, totalmente flash ou híbrido com uma camada de cache flash mais discos rígidos como camada de capacidade.
- O armazenamento é apresentado como um pool definido por software, incluindo posicionamento de dados e políticas de capacidade, desempenho e disponibilidade.
- A capacidade e o desempenho de E/S são escalados adicionando hosts ao cluster.
- Os dados são gravados no armazenamento em vários nós do cluster de forma síncrona, para que o cluster possa tolerar falhas de host ou componente sem perda de dados.
- A disponibilidade e o balanceamento de carga da VM são fornecidos pelo hypervisor, por exemplo, vMotion, VMware HA e DRS.
Como observei acima, também existem outras soluções HCI com variações nesta lista, como suporte para arrays de armazenamento externo, nós somente de armazenamento... a lista é tão longa quanto a lista de fornecedores.
A adoção do HCI está ganhando ritmo e a concorrência entre os fornecedores está impulsionando a inovação e as melhorias de desempenho. Também vale a pena notar que o HCI é um bloco de construção básico para a implantação em nuvem.
# Os produtos da InterSystems são suportados em HCI?
É política e procedimento da InterSystems verificar e lançar os produtos da InterSystems em relação a tipos de processador e sistemas operacionais, inclusive quando os sistemas operacionais são virtualizados. Observe o Aviso da InterSystems: Data Centers Definidos por Software (SDDC) e Infraestrutura Hiperconvergente (HCI)..
Por exemplo: Caché 2016.1 executado no sistema operacional Red Hat 7.2 no vSAN em hosts x86 é suportado.
Observação: se você não escrever seus próprios aplicativos, também deverá verificar a política de suporte de seus fornecedores de aplicativos.
# Planejamento de capacidade do vSAN
Esta seção destaca considerações e recomendações para a implantação do VMware vSAN para aplicações de banco de dados em plataformas de dados InterSystems - Caché, Ensemble e HealthShare. No entanto, você também pode usar essas recomendações como uma lista geral de perguntas de configuração para revisar com qualquer fornecedor de HCI.
vCPU e memória da VM
Como ponto de partida, use as mesmas regras de planejamento de capacidade para a vCPU e a memória de suas VMs de banco de dados que você já usa para implantar seus aplicativos no VMware ESXi com os mesmos processadores.
Como um lembrete para o dimensionamento geral de CPU e memória para o Caché, uma lista de outras postagens nesta série está aqui: Planejamento de capacidade e índice de série de performance.
Uma das características dos sistemas HCI (Infraestrutura Hiperconvergente) é a latência de E/S de armazenamento muito baixa e a alta capacidade de IOPS (Operações de Entrada/Saída por Segundo). Você deve se lembrar da segunda postagem desta série, o gráfico dos grupos alimentares de hardware mostrando CPU, memória, armazenamento e rede. Eu destaquei que esses componentes estão todos relacionados entre si e mudanças em um componente podem afetar outro, às vezes com consequências inesperadas.Por exemplo, vi um caso em que a correção de um gargalo de E/S particularmente ruim em um array de armazenamento fez com que o uso da CPU saltasse para 100%, resultando em uma experiência do usuário ainda pior, pois o sistema estava repentinamente livre para fazer mais trabalho, mas não tinha os recursos de CPU para atender ao aumento da atividade do usuário e da taxa de transferência. Esse efeito é algo a se ter em mente ao planejar seus novos sistemas, se seu modelo de dimensionamento for baseado em métricas de desempenho de hardware menos performático. Mesmo que você esteja atualizando para servidores mais novos com processadores mais recentes, a atividade da VM do seu banco de dados deve ser monitorada de perto, caso você precise redimensionar devido à menor latência de E/S na nova plataforma.
Observe também que, conforme detalhado posteriormente, você também terá que considerar o processamento de E/S de armazenamento definido por software ao dimensionar os recursos de CPU e memória do host físico.
Planejamento da capacidade de armazenamento
Para entender o planejamento da capacidade de armazenamento e colocar as recomendações de banco de dados em contexto, você deve primeiro entender algumas diferenças básicas entre o vSAN e o armazenamento tradicional do ESXi. Abordarei essas diferenças primeiro e, em seguida, detalharei todas as recomendações de melhores práticas para bancos de dados Caché.
Modelo de armazenamento vSAN
No cerne do vSAN e do HCI em geral está o armazenamento definido por software (SDS). A maneira como os dados são armazenados e gerenciados é muito diferente do uso de um cluster de servidores ESXi e um array de armazenamento compartilhado. Uma das vantagens do HCI é que não existem LUNs (Números de Unidades Lógicas), mas sim pools de armazenamento que são alocados para VMs conforme necessário, com políticas que descrevem as capacidades de disponibilidade, capacidade e desempenho por VMDK (Disco Virtual da Máquina Virtual).
Por exemplo; imagine um array de armazenamento tradicional consistindo em prateleiras de discos físicos configurados juntos como grupos de discos ou pools de discos de vários tamanhos, com diferentes números e/ou tipos de discos, dependendo dos requisitos de desempenho e disponibilidade. Os grupos de discos são então apresentados como um número de discos lógicos (volumes de array de armazenamento ou LUNs) que, por sua vez, são apresentados aos hosts ESXi como datastores e formatados como volumes VMFS. As VMs são representadas como arquivos nos datastores. As melhores práticas de banco de dados para disponibilidade e desempenho recomendam, no mínimo, grupos de discos e LUNs separados para banco de dados (acesso aleatório), journals (sequencial) e quaisquer outros (como backups ou sistemas não produtivos, etc.).
vSAN é diferente; o armazenamento do vSAN é alocado usando gerenciamento baseado em políticas de armazenamento (SPBM). Políticas podem ser criadas usando combinações de capacidades, incluindo as seguintes (mas existem mais):
-Falhas a Tolerar (FTT), que dita o número de cópias redundantes de dados.
- Codificação de apagamento (RAID-5 ou RAID-6) para economia de espaço.
- Faixas de disco (disk stripes) para desempenho.
- Provisionamento de disco espesso (thick) ou fino (thin) (fino por padrão no vSAN).
- Outros...
VMDKs (discos de VM individuais) são criados a partir do pool de armazenamento vSAN selecionando as políticas apropriadas. Então, em vez de criar grupos de discos e LUNs no array com um conjunto de atributos, você define as capacidades de armazenamento como políticas no vSAN usando SPBM; por exemplo, "Banco de Dados" seria diferente de "Diário (Journal)", ou quaisquer outros que você precise. Você define a capacidade e seleciona a política apropriada quando cria discos para sua VM.
Outro conceito chave é que uma VM não é mais um conjunto de arquivos em um datastore VMDK, mas é armazenada como um conjunto de objetos de armazenamento. Por exemplo, sua VM de banco de dados será composta por múltiplos objetos e componentes, incluindo os VMDKs, swap, snapshots, etc. O vSAN SDS gerencia toda a mecânica de posicionamento de objetos para atender aos requisitos das políticas que você selecionou.
Camadas de armazenamento e planejamento de desempenho de E/S (IO)
Para garantir alto desempenho, existem duas camadas de armazenamento:
- Camada de cache - Deve ser flash de alta resistência.
- Camada de capacidade - Flash ou, para usos híbridos, discos rígidos (spinning disks).
Como mostrado no gráfico abaixo, o armazenamento é dividido em camadas e grupos de discos. No vSAN 6.5, cada grupo de discos inclui um único dispositivo de cache e até sete discos rígidos ou dispositivos flash. Pode haver até cinco grupos de discos, possivelmente até 35 dispositivos por host. A figura abaixo mostra um cluster vSAN all-flash com quatro hosts, cada host tem dois grupos de discos, cada um com um disco de cache NVMe e três discos de capacidade SATA.
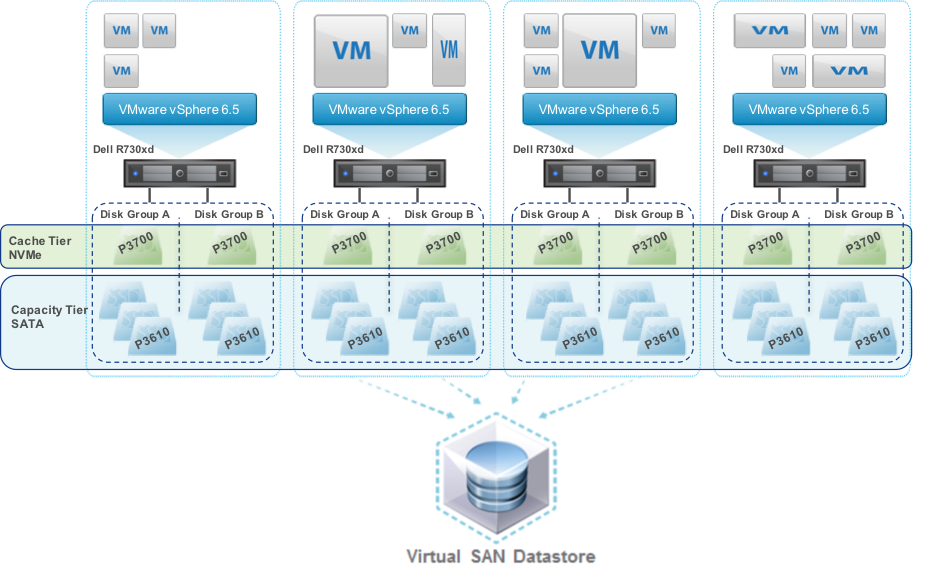
Figura 1. Armazenamento vSAN all-flash mostrando camadas e grupos de discos
Ao considerar como preencher as camadas e o tipo de flash para as camadas de cache e capacidade, você deve considerar o caminho de E/S; para a menor latência e o máximo desempenho, as escritas vão para a camada de cache, então o software consolida e descarrega as escritas para a camada de capacidade. O uso do cache depende do modelo de implantação, por exemplo, em configurações híbridas do vSAN, 30% da camada de cache é cache de escrita, no caso de all-flash, 100% da camada de cache é cache de escrita -- as leituras são da camada de capacidade flash de baixa latência.
Haverá um aumento de desempenho usando all-flash. Com unidades flash de maior capacidade e durabilidade disponíveis hoje, chegou a hora de você considerar se precisa de discos rígidos. O argumento comercial para flash em vez de discos rígidos foi feito nos últimos anos e inclui custo/IOPS muito menor, desempenho (menor latência), maior confiabilidade (sem partes móveis para falhar, menos discos para falhar para IOPS necessários), menor consumo de energia e perfil de calor, menor espaço físico e assim por diante. . Você também se beneficiará de recursos adicionais de HCI, por exemplo, o vSAN só permitirá deduplicação e compressão em configurações all-flash.
- Recomendação:_ Para melhor desempenho e menor TCO, considere all-flash.
Para o melhor desempenho, a camada de cache deve ter a menor latência, especialmente para o vSAN, pois há apenas um único dispositivo de cache por grupo de discos.
- Recomendação:_ Se possível, escolha SSDs NVMe para a camada de cache, embora SAS ainda seja adequado.
- Recomendação:_ Escolha dispositivos flash de alta resistência na camada de cache para lidar com alto I/O..
Para SSDs na camada de capacidade, há uma diferença de desempenho insignificante entre SSDs SAS e SATA. Você não precisa incorrer no custo de SSDs NVMe na camada de capacidade para aplicações de banco de dados. No entanto, em todos os casos, certifique-se de que está usando SSDs SATA de classe empresarial com recursos como proteção contra falha de energia.
- Recomendação:_ Escolha SSDs SATA de alta capacidade para a camada de capacidade.
- Recomendação:_ Escolha SSDs empresariais com proteção contra falha de energia.
Dependendo do seu cronograma, novas tecnologias como o 3D Xpoint, com IOPS mais altos, menor latência, maior capacidade e maior durabilidade, podem estar disponíveis. Há uma análise do armazenamento flash no final deste post.
- Recomendação:_ Fique atento a novas tecnologias a serem incluídas, como o 3D Xpoint, para as camadas de cache E capacidade.
Como mencionei acima, você pode ter até cinco grupos de discos por host e um grupo de discos é composto por um dispositivo flash e até sete dispositivos na camada de capacidade. Você pode ter um único grupo de discos com um dispositivo flash e quanta capacidade precisar, ou vários grupos de discos por host. Existem vantagens em ter vários grupos de discos por host:
- Desempenho: Ter vários dispositivos flash nas camadas aumentará os IOPS disponíveis por host.
- Domínio de falha: A falha de um disco de cache afeta todo o grupo de discos, embora a disponibilidade seja mantida, pois o vSAN reconstrói automaticamente.
Você terá que equilibrar disponibilidade, desempenho e capacidade, mas, em geral, ter vários grupos de discos por host é um bom equilíbrio.
- **Recomendação:_**Revise os requisitos de armazenamento, considere vários grupos de discos por host.
Qual desempenho devo esperar?
Um requisito fundamental para uma boa experiência do usuário de aplicativos é a baixa latência de armazenamento; a recomendação usual é que a latência de E/S de leitura do banco de dados deve estar abaixo de 10ms. Consulte a tabela da Parte 6 desta série aqui para obter detalhes.
Para cargas de trabalho de banco de dados Caché testadas usando a política de armazenamento vSAN padrão e o utilitário RANREADo Caché, observei E/S de leitura aleatória sustentada de 100% acima de 30K IOPS com menos de 1ms de latência para vSAN all-flash usando SSDs SATA Intel S3610 na camada de capacidade. Considerando que uma regra prática básica para bancos de dados Caché é dimensionar instâncias para usar memória para o máximo de E/S de banco de dados possível, a capacidade de latência e IOPS all-flash deve fornecer ampla margem para a maioria das aplicações. Lembre-se de que os tempos de acesso à memória ainda são ordens de magnitude menores do que até mesmo o armazenamento flash NVMe
Como sempre, lembre-se de que seus resultados podem variar; políticas de armazenamento, número de grupos de discos e número e tipo de discos, etc., influenciarão o desempenho, portanto, você deve validar em seus próprios sistemas!
Planejamento de capacidade e desempenho
Você pode calcular a capacidade bruta em TB de um pool de armazenamento vSAN aproximadamente como o tamanho total dos discos na camada de capacidade. Em nossa configuração de exemplo na figura 1 há um total de 24 SSDs INTEL S3610 de 1,6 TB:
Capacidade bruta do cluster: 24 x 1.6TB = 38.4 TB
No entanto, a capacidade _disponível _ é muito diferente e é onde os cálculos se tornam complexos e dependem das escolhas de configuração; quais políticas são usadas (como FTT, que dita quantas cópias de dados) e também se a deduplicação e a compressão foram ativadas.
Vou detalhar políticas selecionadas e discutir suas implicações para capacidade e desempenho, e recomendações para uma arga de trabalho de banco de dados.
Todas as implementações de ESXi que vejo são compostas por múltiplas VMs; por exemplo, o TrakCare, um sistema de informação de saúde unificado construído na plataforma de informática de saúde da InterSystems, HealthShare, tem em seu núcleo pelo menos um grande (monstruoso) servidor de banco de dados VM que se encaixa absolutamente na descrição de "aplicação crítica de negócios de nível 1". No entanto, uma implementação também inclui combinações de outras VMs de propósito único, como servidores web de produção, servidores de impressão, etc. Bem como VMs de teste, treinamento e outras VMs de não produção. Geralmente, todas implantadas em um único cluster ESXi. Embora eu me concentre nos requisitos de VM de banco de dados, lembre-se de que o SPBM pode ser personalizado por VMDK para todas as suas VMs.
Deduplicação e Compressão
Para vSAN, a deduplicação e a compressão são configurações de liga/desliga em todo o cluster. A deduplicação e a compressão só podem ser ativadas quando você estiver usando uma configuração all-flash. Ambas as funcionalidades são ativadas juntas.
À primeira vista, a deduplicação e a compressão parecem ser uma boa ideia - você quer economizar espaço, especialmente se estiver usando dispositivos flash (mais caros) na camada de capacidade. Embora haja economia de espaço com deduplicação e compressão, minha recomendação é que você não habilite esse recurso para clusters com grandes bancos de dados de produção ou onde os dados são constantemente sobrescritos.
A deduplicação e a compressão adicionam alguma sobrecarga de processamento no host, talvez na faixa de utilização de CPU de um único dígito percentual, mas essa não é a principal razão para não recomendar para bancos de dados.
Em resumo, o vSAN tenta deduplicar dados à medida que são gravados na camada de capacidade dentro do escopo de um único grupo de discos, usando blocos de 4K. Portanto, em nosso exemplo na figura 1 os objetos de dados a serem deduplicados teriam que existir na camada de capacidade do mesmo grupo de discos. Não estou convencido de que veremos muita economia nos arquivos de banco de dados Caché, que são basicamente arquivos muito grandes preenchidos com blocos de banco de dados de 8K com ponteiros únicos, conteúdos, etc. Em segundo lugar, o vSAN só tentará compactar blocos duplicados e só considerará os blocos compactados se a compactação atingir 50% ou mais.Se o bloco deduplicado não compactar para 2K, ele será gravado não compactado. Embora possa haver alguma duplicação de sistema operacional ou outros arquivos, _ o benefício real da deduplicação e compressão seria para clusters implantados para VDI_.
Outro aviso é o impacto de uma falha (embora rara) de um dispositivo em um grupo de discos em todo o grupo quando a deduplicação e a compressão estão ativadas. Todo o grupo de discos é marcado como "não saudável", o que tem um impacto em todo o cluster: porque o grupo está marcado como não saudável, todos os dados em um grupo de discos serão evacuados desse grupo para outros locais, então o dispositivo deve ser substituído e o vSAN ressincronizará os objetos para reequilibrar.
- Recomendação:_ Para implementações de banco de dados, não habilite a compactação e a deduplicação.
Barra Lateral: Espelhamento de banco de dados InterSystems.
Para instâncias de aplicativos de banco de dados Caché de nível 1 de missão crítica que exigem a mais alta disponibilidade, recomendo o espelhamento de banco de dados síncrono da InterSystems, mesmo quando virtualizado. Soluções virtualizadas têm HA (alta disponibilidade) integrada; por exemplo, VMWare HA, no entanto, vantagens adicionais de também usar espelhamento incluem:
- Cópias separadas de dados atualizados.
- Failover em segundos (mais rápido do que reiniciar uma VM, depois o sistema operacional e, em seguida, recuperar o Caché).
-Failover em caso de falha do aplicativo/Caché (não detectada pelo VMware).
Acho que você percebeu a falha em habilitar a deduplicação quando você tem bancos de dados espelhados no mesmo cluster? Você estará tentando deduplicar seus dados espelhados. Geralmente não é sensato e também é uma sobrecarga de processamento.
Outra consideração ao decidir se espelhar bancos de dados em HCI é a capacidade total de armazenamento necessária. O vSAN fará várias cópias de dados para disponibilidade, e esse armazenamento de dados será dobrado novamente pelo espelhamento. Você precisará ponderar o pequeno aumento incremental no tempo de atividade em relação ao que o VMware HA fornece, contra o custo adicional de armazenamento.
Para o máximo tempo de atividade, você pode criar dois clusters para que cada nó do espelho de banco de dados esteja em um domínio de falha completamente independente. No entanto, observe o total de servidores e a capacidade de armazenamento para fornecer esse nível de tempo de atividade.
Criptografia
Outra consideração é onde você escolhe criptografar os dados em repouso. Você tem várias opções na pilha de E/S, incluindo;
- Usando a criptografia do banco de dados Caché (criptografa apenas o banco de dados).
- No armazenamento (por exemplo, criptografia de disco de hardware no SSD).
A criptografia terá um impacto muito pequeno no desempenho, mas pode ter um grande impacto na capacidade se você optar por habilitar a deduplicação ou a compressão no HCI.Se você optar por deduplicação e/ou compressão, não gostaria de usar a criptografia de banco de dados Caché, pois isso negaria quaisquer ganhos, já que os dados criptografados são aleatórios por design e não comprimem bem. Considere o ponto de proteção ou o risco que eles estão tentando proteger, por exemplo, roubo de arquivo versus roubo de dispositivo.
- Recomendação:_ Criptografe na camada mais baixa possível na pilha de E/S para um nível mínimo de criptografia. No entanto, quanto mais risco você deseja proteger, mova-se mais alto na pilha.
Falhas a tolerar (FTT)
FTT define um requisito para o objeto de armazenamento tolerar pelo menos n falhas simultâneas de host, rede ou disco no cluster e ainda garantir a disponibilidade do objeto. O padrão é 1 (RAID-1); os objetos de armazenamento da VM (por exemplo, VMDK) são espelhados entre os hosts ESXi.
Portanto, a configuração do vSAN deve conter pelo menos n + 1 réplicas (cópias dos dados), o que também significa que existem 2n + 1 hosts no cluster.
Por exemplo, para cumprir a política de um número de falhas a tolerar = 1 , você precisa de três hosts no mínimo em todos os momentos -- mesmo que um host falhe. Portanto, para contabilizar a manutenção ou outros momentos em que um host é retirado do ar, você precisa de quatro hosts.
- Recomendação:_ Um cluster vSAN deve ter um mínimo de quatro hosts para disponibilidade.
Observe que também existem exceções; uma configuração de Escritório Remoto de Filial (ROBO) que é projetada para dois hosts e uma VM de testemunha remota.
Codificação de Apagamento
O método de armazenamento padrão no vSAN é RAID-1 -- replicação ou espelhamento de dados. A codificação de apagamento é RAID-5 ou RAID-6 com objetos/componentes de armazenamento distribuídos entre os nós de armazenamento no cluster. O principal benefício da codificação de apagamento é uma melhor eficiência de espaço para o mesmo nível de proteção de dados.
Usando o cálculo para FTT na seção anterior como um exemplo; para uma VM tolerar _duas _ falhas usando um RAID-1, deve haver três cópias de objetos de armazenamento, o que significa que um VMDK consumirá 300% do tamanho base do VMDK. O RAID-6 também permite que uma VM tolere duas falhas e consuma apenas 150% do tamanho do VMDK.
A escolha aqui é entre desempenho e capacidade. Embora a economia de espaço seja bem-vinda, você deve considerar seus padrões de E/S de banco de dados antes de habilitar a codificação de apagamento. Os benefícios de eficiência de espaço vêm ao preço da amplificação das operações de E/S, que é ainda maior durante os períodos de falha de componentes, portanto, para o melhor desempenho do banco de dados, use RAID-1.
- Recomendação:_ Para bancos de dados de produção, não habilite a codificação de apagamento (erasure coding). Habilite apenas para ambientes de não produção.
A codificação de apagamento também impacta o número de hosts necessários em seu cluster. Por exemplo, para RAID-5, você precisa de um mínimo de quatro nós no cluster, e para RAID-6, um mínimo de seis nós.
- Recomendação:_ Considere o custo de hosts adicionais antes de planejar a configuração da codificação de apagamento.
Striping (Distribuição de Dados)
A distribuição de dados (striping) oferece oportunidades para melhorias de desempenho, mas provavelmente só ajudará com configurações híbridas.
- Recomendação:_ Para bases de dados de produção, não habilite o striping.
Reserva de Espaço de Objeto (provisionamento fino ou espesso)
O nome para esta configuração vem do vSAN usar objetos para armazenar componentes de suas VMs (VMDKs, etc.).Por padrão, todas as VMs provisionadas em um datastore vSAN têm reserva de espaço de objeto de 0% (provisionamento fino), o que leva a economia de espaço e também permite que o vSAN tenha mais liberdade para o posicionamento de dados. No entanto, para seus bancos de dados de produção, a melhor prática é usar reserva de 100% (provisionamento espesso), onde o espaço é alocado na criação. Para o vSAN, isso será Lazy Zeroed – onde os zeros são escritos à medida que cada bloco é gravado pela primeira vez. Existem algumas razões para escolher reserva de 100% para bancos de dados de produção; haverá menos atraso quando ocorrerem expansões de banco de dados, e você estará garantindo que o armazenamento estará disponível quando precisar.
- Recomendação:_ Para discos de banco de dados de produção, use reserva de 100%.
- **Recomendação:_**Para instâncias de não produção, deixe o armazenamento com provisionamento fino.
Quando devo ativar os recursos?
Geralmente, você pode habilitar os recursos de disponibilidade e economia de espaço após usar os sistemas por algum tempo, ou seja, quando houver VMs e usuários ativos no sistema. No entanto, haverá impacto no desempenho e na capacidade. Réplicas adicionais de dados, além do original, são necessárias, portanto, espaço adicional é exigido enquanto os dados são sincronizados. Minha experiência é que habilitar esses tipos de recursos em clusters com grandes bancos de dados pode levar muito tempo e expor a possibilidade de disponibilidade reduzida.
- Recomendação:_ Dedique tempo antecipadamente para entender e configurar recursos e funcionalidades de armazenamento, como deduplicação e compressão, antes da entrada em produção e definitivamente antes que grandes bancos de dados sejam carregados.
Existem outras considerações, como deixar espaço livre para balanceamento de disco, falhas, etc. O ponto é que você terá que levar em conta as recomendações deste post com as escolhas específicas do fornecedor para entender seus requisitos de disco bruto.
- Recomendação:_ Existem muitos recursos e permutações. Calcule seus requisitos totais de capacidade em GB como ponto de partida, revise as recomendações neste post [e com o fornecedor do seu aplicativo] e, em seguida, converse com seu fornecedor de HCI.
Sobrecarga de processamento de armazenamento
Você deve considerar a sobrecarga do processamento de armazenamento nos hosts. O processamento de armazenamento, que de outra forma seria tratado pelos processadores em um array de armazenamento empresarial, agora está sendo computado em cada host do cluster.
A quantidade de sobrecarga por host dependerá da carga de trabalho e de quais recursos de armazenamento estão habilitados. Minhas observações com testes básicos que realizei com Caché no vSAN mostram que os requisitos de processamento não são excessivos, especialmente quando você considera o número de núcleos disponíveis nos servidores atuais. A VMware recomenda planejar um uso de CPU do host de 5-10%.
O acima pode ser um ponto de partida para dimensionamento, mas lembre-se de que seus resultados podem variar e você precisará confirmar.
- Recomendação:_ Planeje para o pior caso de 10% de utilização da CPU e, em seguida, monitore sua carga de trabalho real.
Rede
Revise os requisitos do fornecedor -- assuma NICs de 10GbE mínimos -- NICs múltiplos para tráfego de armazenamento, gerenciamento (por exemplo, vMotion), etc. Posso dizer por experiência dolorosa que um switch de rede de classe empresarial é necessário para a operação ideal do cluster -- afinal, todas as gravações são enviadas de forma síncrona pela rede para disponibilidade.
- Recomendação:_ Largura de banda de rede comutada de 10GbE mínima para tráfego de armazenamento. NICs múltiplos por host, conforme as melhores práticas.
#Visão Geral do Armazenamento Flash
O armazenamento flash é um requisito do HCI, por isso é bom revisar onde o armazenamento flash está hoje e para onde está indo no futuro próximo.
A história curta é que, quer você use HCI ou não, se você não estiver implantando seus aplicativos usando armazenamento com flash hoje, é provável que sua próxima compra de armazenamento inclua flash.
Armazenamento hoje e amanhã
Vamos revisar as capacidades das soluções de armazenamento comumente implantadas e garantir que estamos claros com a terminologia.
Disco rígido
- Velho conhecido. Discos rígidos (HDD) de 7.2, 10K ou 15K com interface SAS ou SATA. Baixo IOPS por disco. Podem ter alta capacidade, mas isso significa que os IOPS por GB estão diminuindo. Para desempenho, os dados são normalmente distribuídos em vários discos para alcançar "IOPS suficientes" com alta capacidade.
Disco SSD - SATA e SAS
- Hoje, o flash é geralmente implantado como SSDs com interface SAS ou SATA usando flash NAND. Também há alguma DRAM no SSD como um buffer de gravação. SSDs empresariais incluem proteção contra perda de energia - em caso de falha de energia, o conteúdo da DRAM é descarregado para a NAND.
Disco SSD - NVMe
- Semelhante ao disco SSD, mas usa o protocolo NVMe (não SAS ou SATA) com flash NAND. A mídia NVMe se conecta via barramento PCI Express (PCIe), permitindo que o sistema se comunique diretamente, sem a sobrecarga de adaptadores de barramento de host e estruturas de armazenamento, resultando em latência muito menor.
Array de Armazenamento
- Arrays Empresariais fornecem proteção e a capacidade de escalar. Hoje em dia, é mais comum que o armazenamento seja um array híbrido ou totalmente flash. Arrays híbridos têm uma camada de cache de flash NAND mais uma ou mais camadas de capacidade usando discos rígidos de 7.2, 10K ou 15K. Arrays NVMe também estão se tornando disponíveis.
NVDIMM de Modo Bloco
- Esses dispositivos estão sendo enviados hoje e são usados quando latências extremamente baixas são necessárias. NVDIMMs são instalados em um socket de memória DDR e fornecem latências em torno de 30ns. Hoje, eles são enviados em módulos de 8GB, portanto, provavelmente não serão usados para aplicativos de banco de dados legados, mas novos aplicativos de scale-out podem aproveitar esse desempenho.
3D XPoint
Esta é uma tecnologia futura - não disponível em novembro de 2016.
- Desenvolvido pela Micron e Intel. Também conhecido como Optane (Intel) e QuantX (Micron).
- Não estará disponível até pelo menos 2017, mas, comparado ao NAND, promete maior capacidade, >10x mais IOPS, >10x menor latência com resistência extremamente alta e desempenho consistente.
- A primeira disponibilidade usará o protocolo NVMe.
Resistência do Dispositivo SSD
A _resistência _ do dispositivo SSD é uma consideração importante ao escolher unidades para camadas de cache e capacidade. A história curta é que o armazenamento flash tem uma vida finita. As células flash em um SSD só podem ser excluídas e reescritas um certo número de vezes (nenhuma restrição se aplica às leituras). O firmware no dispositivo gerencia a distribuição de gravações pela unidade para maximizar a vida útil do SSD. SSDs empresariais também normalmente têm mais capacidade flash real do que a visível para alcançar uma vida útil mais longa (superprovisionados), por exemplo, uma unidade de 800GB pode ter mais de 1TB de flash.
A métrica a ser observada e discutida com seu fornecedor de armazenamento é o número total de Gravações de Unidade por Dia (DWPD) garantido por um certo número de anos. Por exemplo; um SSD de 800GB com 1 DWPD por 5 anos pode ter 800GB gravados por dia durante 5 anos. Portanto, quanto maior o DWPD (e anos), maior a resistência. Outra métrica simplesmente muda o cálculo para mostrar dispositivos SSD especificados em Terabytes Gravados (TBW); o mesmo exemplo tem TBW de 1.460 TB (800GB * 365 dias * 5 anos). De qualquer forma, você tem uma ideia da vida útil do SSD com base no seu IO esperado.
Resumo
Esta postagem aborda os recursos mais importantes a serem considerados ao implantar HCI e, especificamente, o VMWare vSAN versão 6.5. Existem recursos do vSAN que não abordei, se eu não mencionei um recurso, assuma que você deve usar os padrões. No entanto, se você tiver alguma dúvida ou observação, ficarei feliz em discutir através da seção de comentários.
Espero retornar ao HCI em futuras postagens, esta certamente é uma arquitetura que está em ascensão, então espero ver mais clientes da InterSystems implantando em HCI.
 Olá!
Olá!{kind=link}