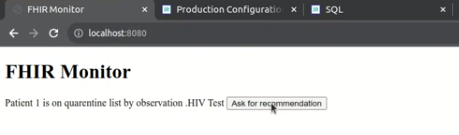
Sabe aquela sensação de receber o resultado do seu exame de sangue e parecer que está em grego? É exatamente esse problema que o FHIRInsight veio resolver. Surgiu da ideia de que dados médicos não deveriam ser assustadores ou confusos – deveriam ser algo que todos podemos utilizar. Exames de sangue são extremamente comuns para verificar nossa saúde, mas, sejamos sinceros, interpretá-los é difícil para a maioria das pessoas e, às vezes, até para profissionais da área que não trabalham em um laboratório. O FHIRInsight quer tornar todo esse processo mais simples e acessível.

🤖 Por que criamos o FHIRInsight
Tudo começou com uma simples pergunta:
“Por que interpretar um exame de sangue ainda é tão difícil — até para médicos, às vezes?”
Se você já olhou para um resultado de laboratório, provavelmente viu um monte de números, abreviações enigmáticas e uma “faixa de referência” que pode ou não se aplicar à sua idade, sexo ou condição. É uma ferramenta de diagnóstico, com certeza — mas sem contexto, vira um jogo de adivinhação. Até profissionais de saúde experientes às vezes precisam recorrer a diretrizes, artigos científicos ou opiniões de especialistas para entender tudo direito.
É aí que o FHIRInsight entra em cena.
Não foi feito apenas para pacientes — fizemos para quem está na linha de frente do atendimento. Para médicos em plantões intermináveis, para enfermeiros que captam sutis padrões nos sinais vitais, para qualquer profissional de saúde que precise tomar decisões certas com tempo limitado e muita responsabilidade. Nosso objetivo é facilitar um pouco o trabalho deles — transformando dados clínicos FHIR em algo claro, útil e fundamentado em ciência médica real. Algo que fale a língua humana.
O FHIRInsight faz mais do que só explicar valores de exames. Ele também:
- Fornece aconselhamento contextual sobre se um resultado é leve, moderado ou grave
- Sugere causas potenciais e diagnósticos diferenciais com base em sinais clínicos
- Recomenda próximos passos — sejam exames adicionais, encaminhamentos ou atendimento de urgência
- Utiliza RAG (Retrieval-Augmented Generation) para incorporar artigos científicos relevantes que fundamentam a análise
Imagine um jovem médico revisando um hemograma de um paciente com anemia. Em vez de buscar cada valor no Google ou vasculhar revistas médicas, ele recebe um relatório que não só resume o problema, mas cita estudos recentes ou diretrizes da OMS que embasam o raciocínio. Esse é o poder de combinar IA e busca vetorial sobre pesquisas selecionadas.
E o paciente?
Ele não fica mais diante de um monte de números, sem saber o que significa “bilirrubina 2,3 mg/dL” ou se deve se preocupar. Em vez disso, recebe uma explicação simples e cuidadosa. Algo que se assemelha mais a uma conversa do que a um laudo clínico. Algo que ele realmente entende — e que pode levar ao consultório do médico mais preparado e menos ansioso.
Porque é disso que o FHIRInsight trata de verdade: transformar complexidade médica em clareza e ajudar profissionais e pacientes a tomarem decisões melhores e mais confiantes — juntos.
🔍 Por dentro da tecnologia
Claro que toda essa simplicidade na superfície é viabilizada por uma tecnologia poderosa atuando discretamente nos bastidores.
Veja do que o FHIRInsight é feito:
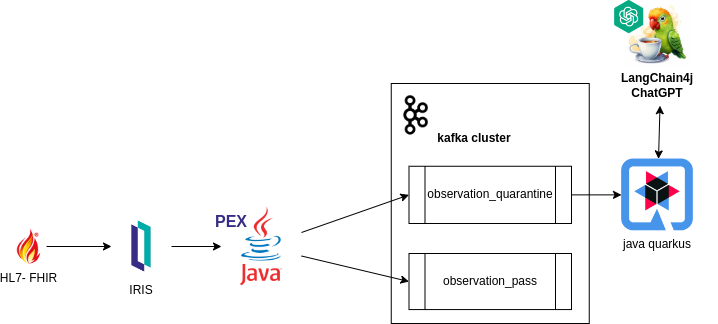
- FHIR (Fast Healthcare Interoperability Resources) — padrão global de dados de saúde. É assim que recebemos informações estruturadas como resultados de exames, histórico do paciente, dados demográficos e atendimentos. O FHIR é a linguagem que os sistemas médicos falam — e nós traduzimos essa linguagem em algo que as pessoas possam usar.
- Busca Vetorial RAG (Retrieval-Augmented Generation): o FHIRInsight aprimora seu raciocínio diagnóstico indexando artigos científicos em PDF e URLs confiáveis em um banco de dados usando a busca vetorial nativa do InterSystems IRIS. Quando um resultado de exame fica ambíguo ou complexo, o sistema recupera conteúdo relevante para embasar suas recomendações — não da memória do modelo, mas de pesquisas reais e atualizadas.
- Engenharia de Prompts para Raciocínio Médico: refinamos nossos prompts para guiar o LLM na identificação de um amplo espectro de condições relacionadas ao sangue. Desde anemia por deficiência de ferro até coagulopatias, desequilíbrios hormonais ou gatilhos autoimunes — o prompt conduz o LLM pelas variações de sintomas, padrões laboratoriais e causas possíveis.
- Integração com LiteLLM: um adaptador customizado direciona requisições para múltiplos provedores de LLM (OpenAI, Anthropic, Ollama etc.) através de uma interface unificada, permitindo fallback, streaming e troca de modelo com facilidade.
Tudo isso acontece em segundos — transformando valores brutos de laboratório em insights médicos explicáveis e acionáveis, seja para um médico revisando 30 prontuários ou um paciente tentando entender seus números.
🧩 o Adapter LiteLLM: Uma Interface para Todos os Modelos
Nos bastidores, os relatórios do FHIRInsight movidos a IA são impulsionados pelo LiteLLM — uma library python que nos permite chamar mais de 100 LLMs (OpenAI, Claude, Gemini, Ollama etc.) por meio de uma única interface estilo OpenAI.
Porém, integrar o LiteLLM ao InterSystems IRIS exigiu algo mais permanente e reutilizável do que scripts Python escondidos numa Business Operation. Então, criamos nosso próprio Adapter LiteLLM.
Conheça o LiteLLMAdapter
Esse adaptador lida com tudo o que você esperaria de uma integração robusta de LLM:
- Recebe parâmetros como
prompt,modeletemperature - Carrega dinamicamente variáveis de ambiente (por exemplo, chaves de API)
Para encaixar isso em nossa produção de interoperabilidade em um simples Business Operation:
- Gerencia configuração em produção por meio da configuração padrão
LLMModel - Integra-se ao componente FHIRAnalyzer para geração de relatórios em tempo real
- Atua como uma “ponte de IA” central para quaisquer componentes futuros que precisem de acesso a LLM
Eis o fluxo de forma simplificada:
set response = ##class(dc.LLM.LiteLLMAdapter).CallLLM("Me fale sobre hemoglobina.", "openai/gpt-4o", 0.7)
write response
🧪 Conclusão
Quando começamos a desenvolver o FHIRInsight, nossa missão era simples: tornar exames de sangue mais fáceis de entender — para todo mundo. Não apenas pacientes, mas médicos, enfermeiros, cuidadores... qualquer pessoa que já tenha encarado um resultado de laboratório e pensado: “Ok, mas o que isso realmente significa?”
Todos nós já passamos por isso.
Ao combinar a estrutura do FHIR, a velocidade do InterSystems IRIS, a inteligência dos LLMs e a profundidade de pesquisas médicas reais via busca vetorial, criamos uma ferramenta que transforma números confusos em histórias significativas. Histórias que ajudam pessoas a tomarem decisões mais inteligentes sobre sua saúde — e, quem sabe, detectar algo cedo que passaria despercebido.
Mas o FHIRInsight não é só sobre dados. É sobre como nos sentimos ao olhar para esses dados. Queremos que seja claro, acolhedor e empoderador. Que a experiência seja... como um verdadeiro “vibecoding” na saúde — aquele ponto perfeito onde código inteligente, bom design e empatia humana se encontram.
Esperamos que você experimente, teste, questione — e nos ajude a melhorar.
Diga o que gostaria de ver no próximo release. Mais condições? Mais explicações? Mais personalização?
Isso é só o começo — e adoraríamos que você ajudasse a moldar o que vem a seguir.


 O que é a Open AI?
O que é a Open AI?










.png)
.png)



.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
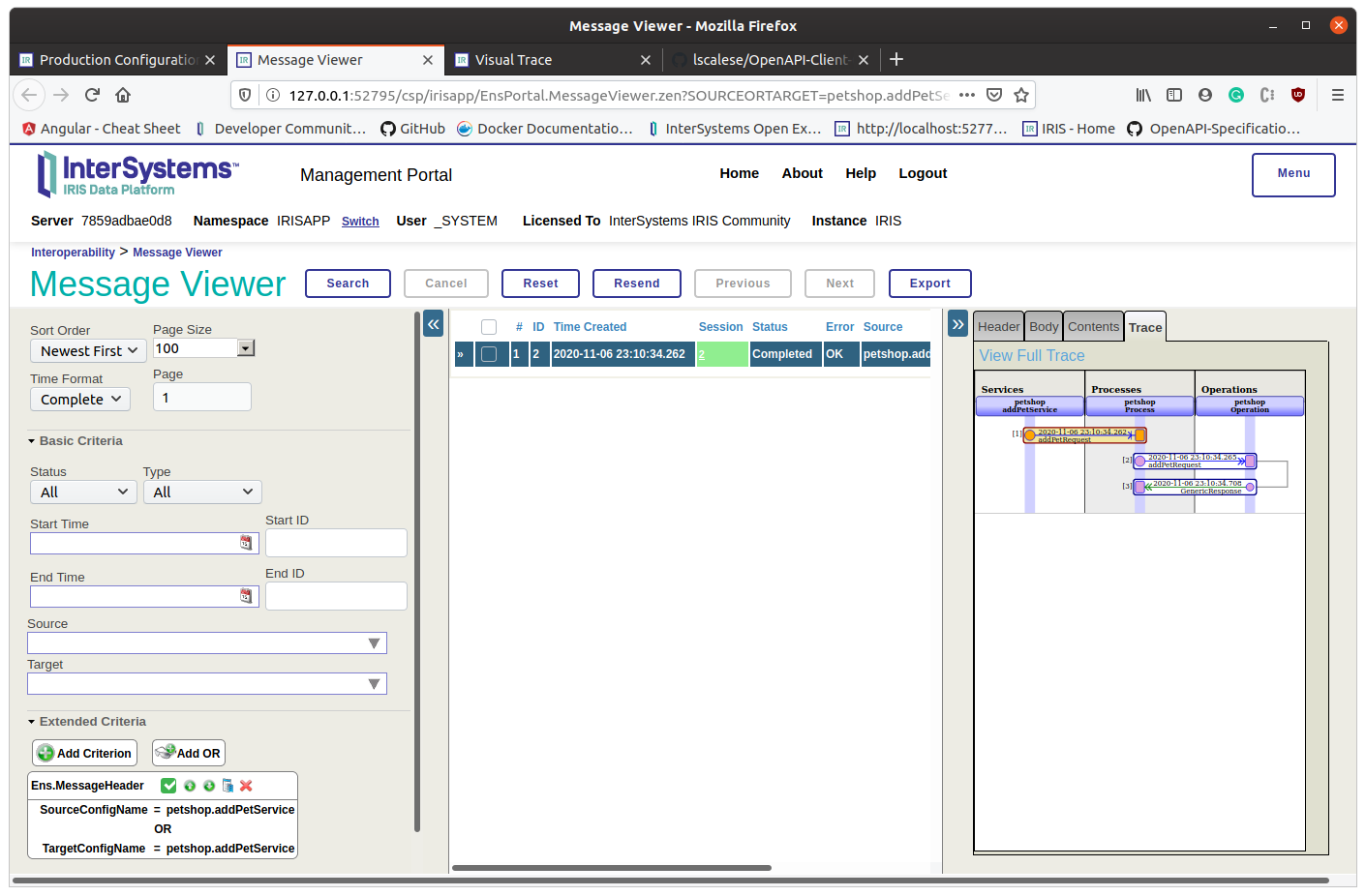
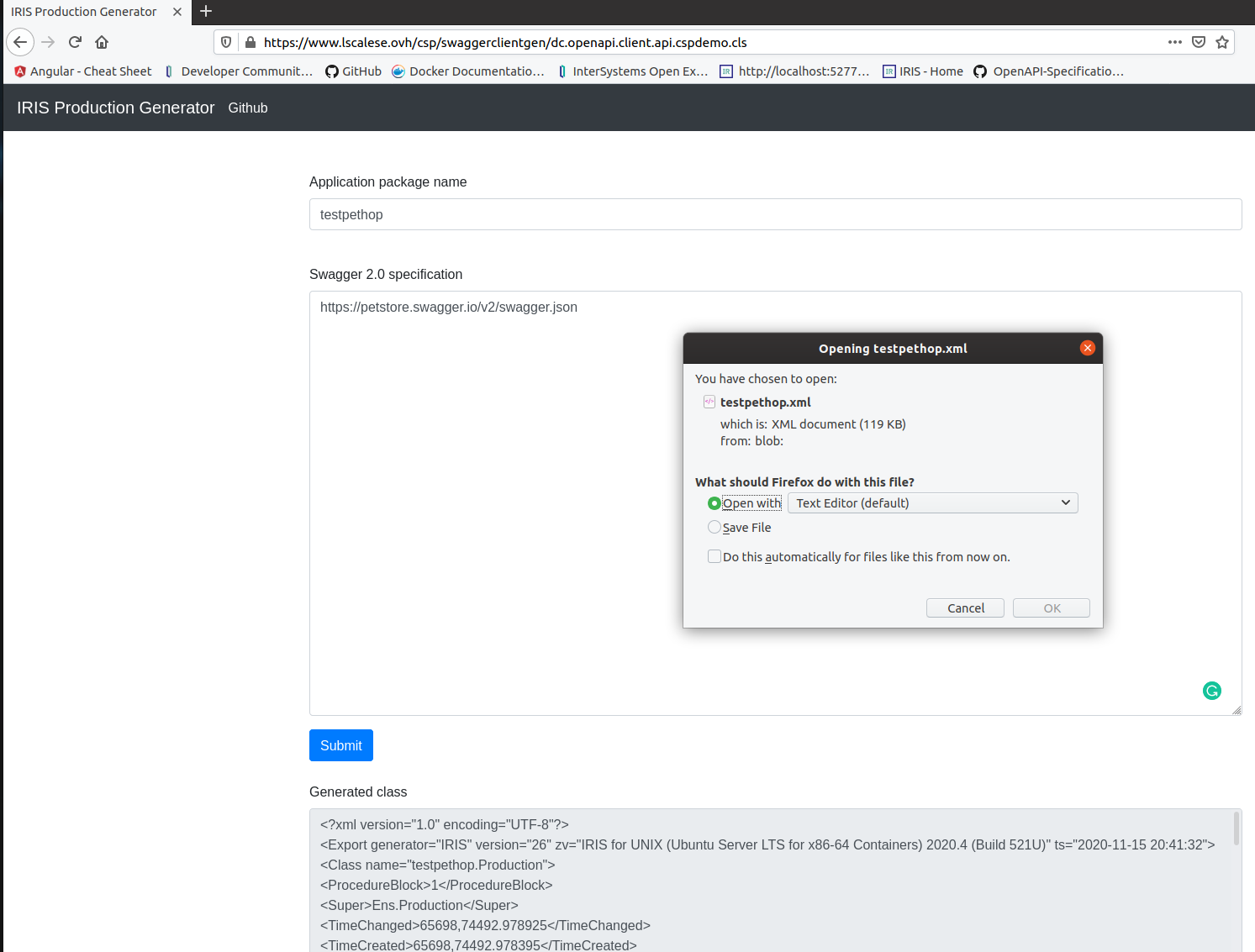
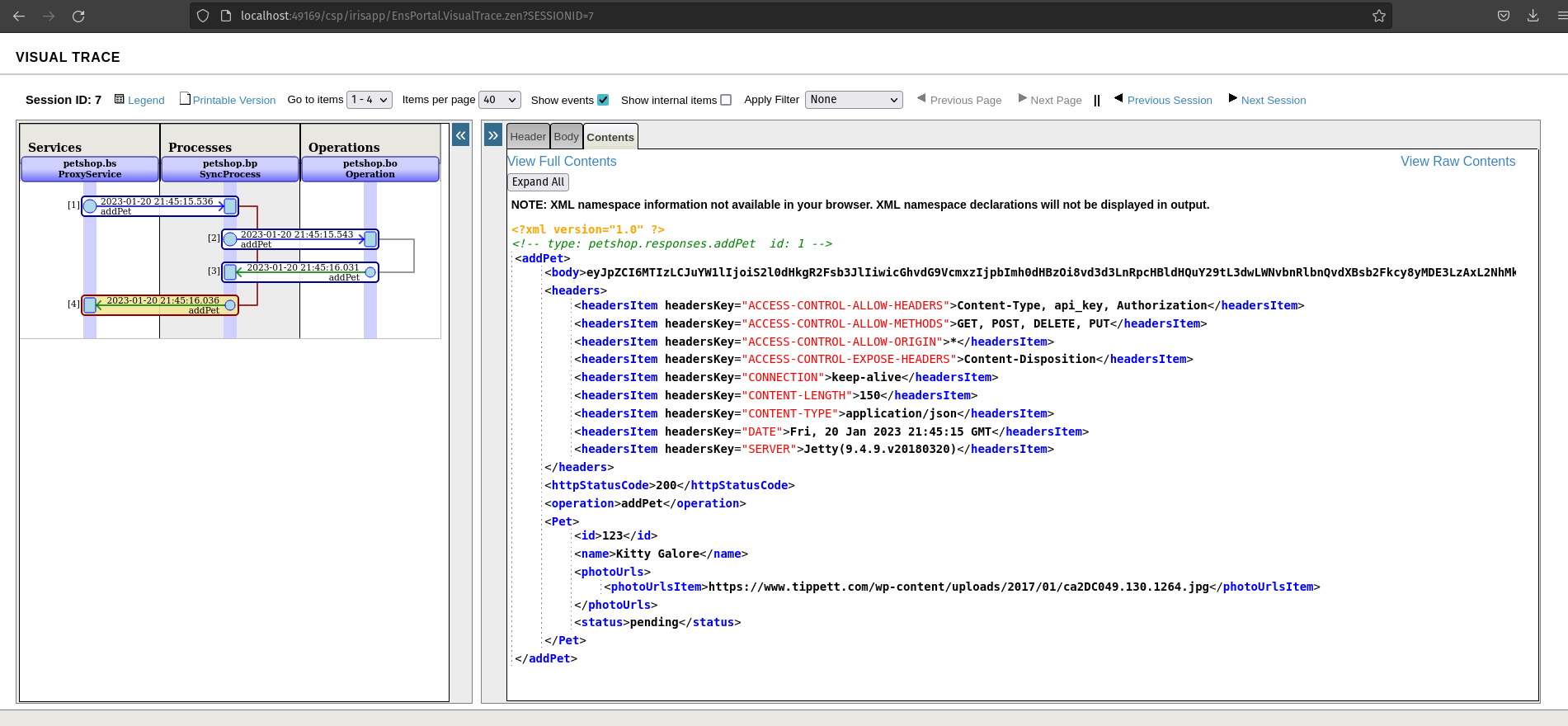 Se tudo estiver bem, podemos observar um código http de status 200. Como você pode ver, recebemos uma resposta do corpo e ela não está analisada.
Se tudo estiver bem, podemos observar um código http de status 200. Como você pode ver, recebemos uma resposta do corpo e ela não está analisada.
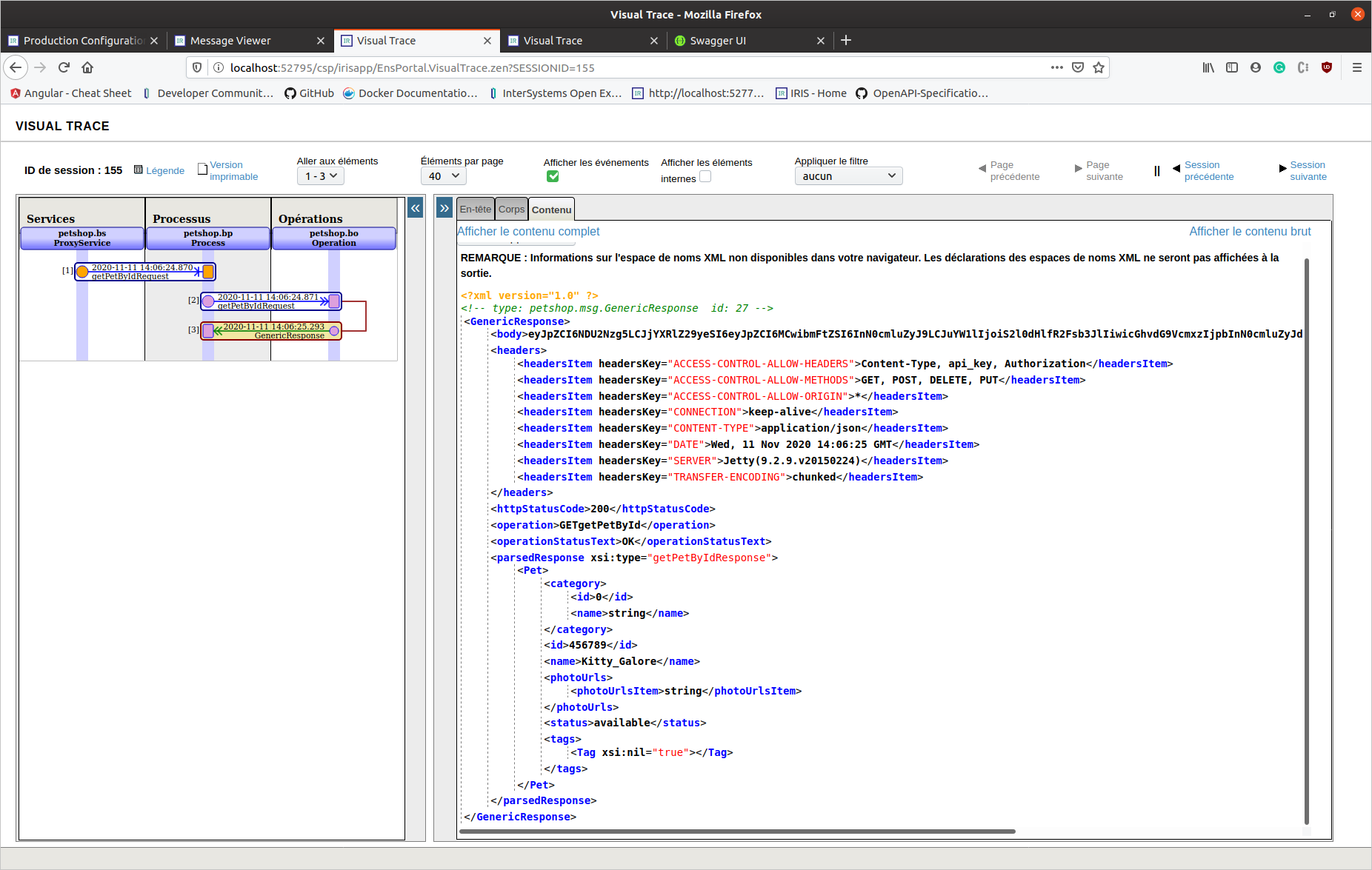 Desta vez, esta é uma resposta da aplicação/json (a resposta 200 está completa nas especificações Swagger). Podemos ver um objeto de resposta analisado.
### API REST - Gerar e baixar
Desta vez, esta é uma resposta da aplicação/json (a resposta 200 está completa nas especificações Swagger). Podemos ver um objeto de resposta analisado.
### API REST - Gerar e baixar